BurpSuite -- 模块 仪表盘(Dashboard)
BurpSuite -- 仪表盘(Dashboard)
自带两个模块,相当于以前版本的spider 和scanner 模块
Dashboard
主要分为三块:
tasks:任务
event log:事件日志;这个主要是burpsuite出现问题或异常状况查看日志用,平时一般用不到。
issue activity:动态发现的问题。这个有个坑,比如点了high后,再有新的high级别的漏洞,不会实时刷新,要重新选下才会出来。
tasks中自带了两个模块,相当于以前版本中的spider和scanner模块的结合体,支持自定义创建。
主动扫描
确定一个URL,然后由扫描器中的爬虫模块爬取所有链接,对GET、POST等请求进行参数变形和污染,进行重放测试,然后依据返回信息中的状态码、数据大小、数据内容关键字等去判断该请求是否含有相应的漏洞
被动扫描:在进行手动测试的过程中,代理将流量转发给漏洞扫描器,然后再进行漏洞检测
主动式
在Dashboard仪表盘块下,点击new scan,进行扫描配置
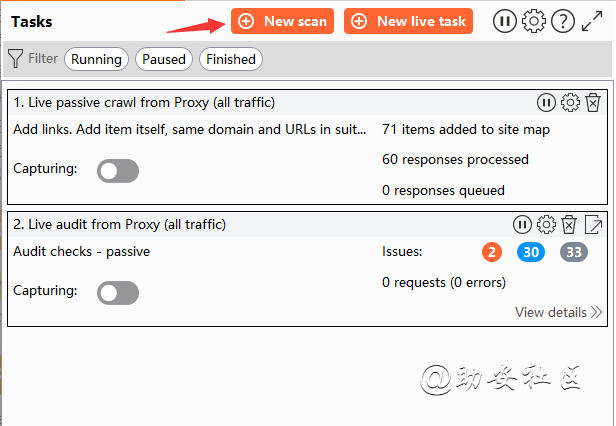
New scan主动扫描
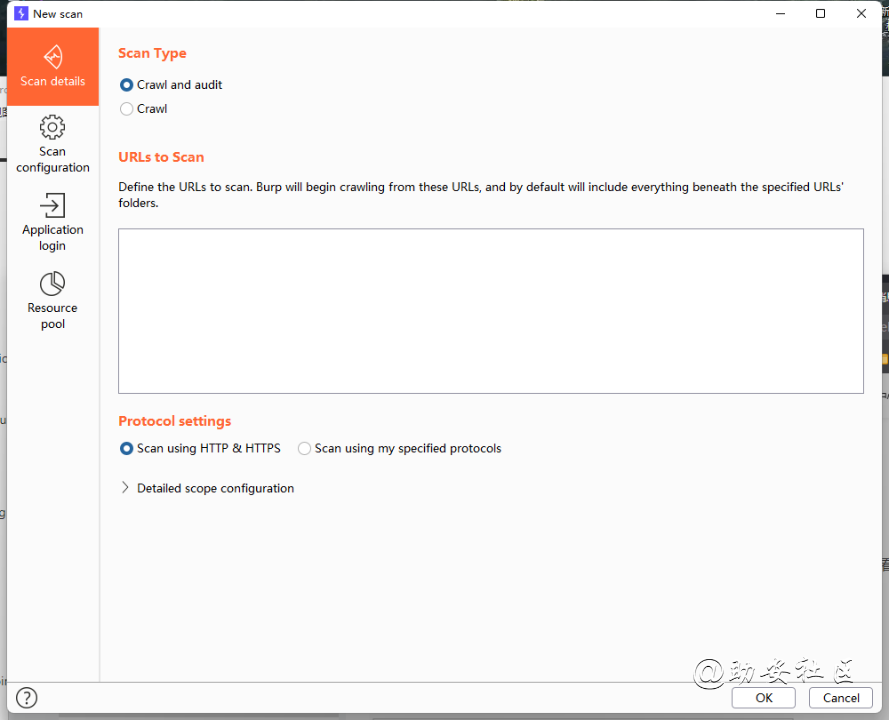
Scan details,设置扫描模式,爬虫或者爬虫且审计,设置扫描范围,可以把url添加到URLs to Scan
new scan (主动扫描)
scan details 选项有两个,一个是爬虫+审计,第二个是只有审计 然后填上URL即可
scan configuration 可以设置自己的UA头,或者按照默认配置即可
Application login options 应用登录选项,只有爬虫检测到登录表单会自动提交,可以自定义设置账户密码,审计用不到
Resource pool options 并发数配置,默认为10
Scan Configuration
常用的设置也就configuration name和user agent。
user agent在miscellaneous下拉框中设置
user agent可以设置成浏览器的请求头,在浏览器控制台network选项的请求中看见。
最后,编辑好设置后,save to library保存到设置库中。以后就方便直接使用了
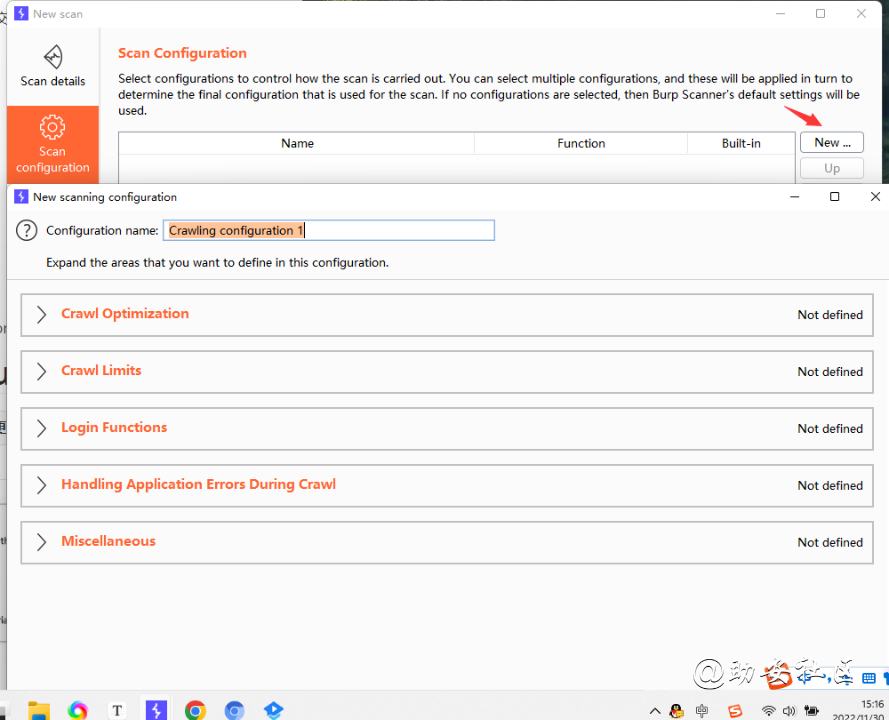
Crawl爬行配置文件之Scanconfiguration
| Crwal Optimization | 爬行的优化 | 最大链接深度更快还是更完整 |
|---|---|---|

- Maximum link depth:最大的爬行深度
- crawl strategy爬行策略
- Fastest最快的Faster很快的Normal普通的More complete爬得更加完整More complete爬得最完整的
Crawl爬行配置文件之Crawl Limits
| Crwal Limits | 爬行最大限制 | 最大时间 最多链接 最大请求数 |
|---|---|---|
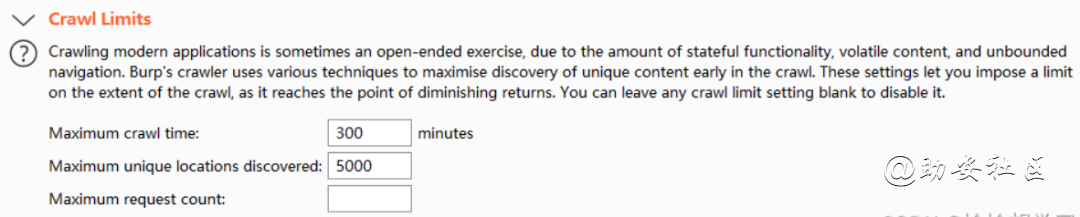
Crawl Limits爬行的限制
Maximum crawl time:设置爬行最长的时间默认150分钟
或者爬行了
Maximum unique locations discovered:爬行长达1500的地址结束 默认1500
Maximum request count:设置发送多少个HTTP请求后结束 默认为空
Crawl爬行配置文件之Login Functions
| Login Function | 登陆注册 | 登陆操作:自动注册 用无效的用户名主动触发登陆失败 |
|---|---|---|
- Login Functions如果有登陆页面是否进行登陆
- Attempt to self-register a user 是否自行注册一个账户
- Trigger login failusers(using invalid username)是否触发登陆失败页面
Crawl爬行配置文件之Handing Application Errors During Crawl
| Handing Application | 错误处理 | 爬行过程中的错误处理,比如超时 |
|---|---|---|
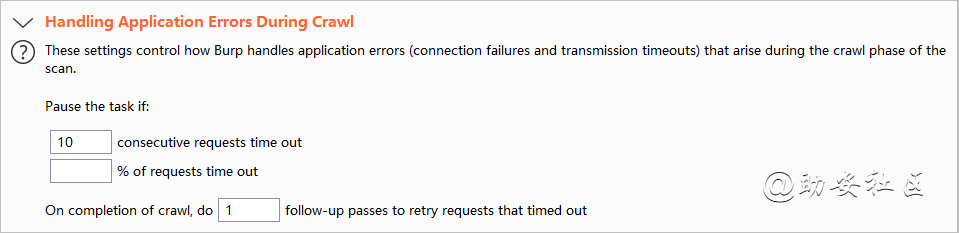
Handing Application Errors During Crawl 错误处理
consecutive requests time out如果出现多少次爬取失败进行跳过
% of requests time out当站点出现百分之多少时连接超时进行跳过这个站点
Auditing
Crawl and Audit审计配置文件之Audit Optimization审计的优化 ![image-20221130152054314]()
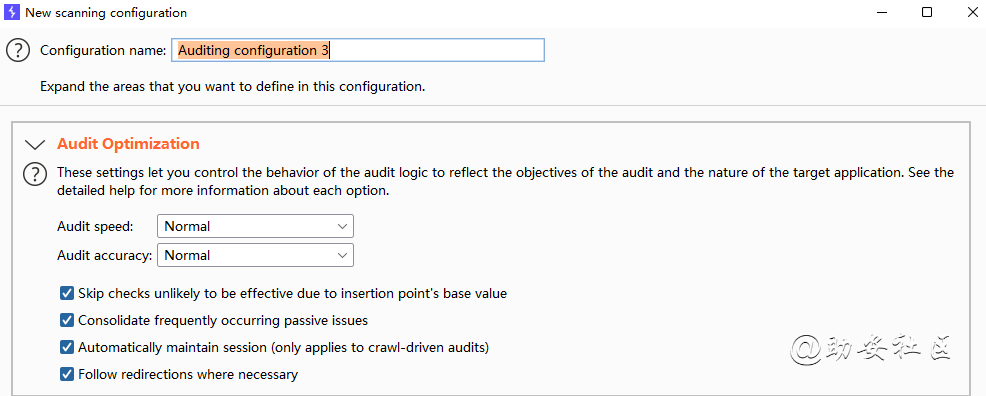
Crawl and Audit审计配置文件之Audit Optimization审计的优化
Audit Optimization:审计的优化,决定速度,精确性。四个选项分别决定:
基于审计的值,是否跳过不太可能的漏洞检查。例如一个数字值就不会尝试目录遍历漏洞。
将经常出现的问题进行合并。
自动维持 session。只在当选择 Crawl and Audit 模式才有作用。
在必要时遵循重定向。可以在Project options.HTTP.Redirections 设置具体的重定向条件
Crawl and Audit审计配置文件之Issues Reported
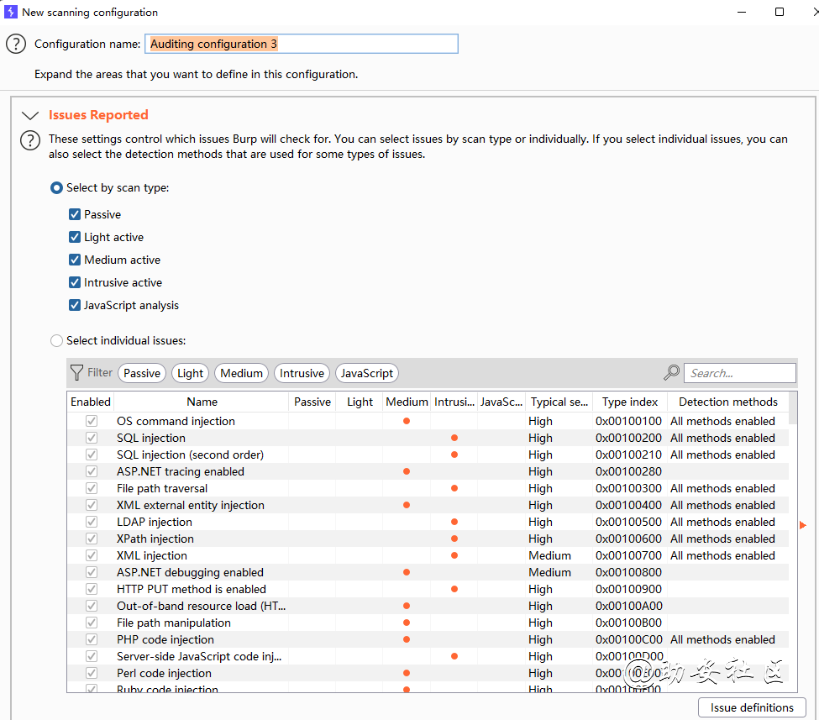
Issues Reported审计扫描结果报告
Select by scan type:进行审计的类型选择
passive:被动扫描
Light activer:高危漏洞主动扫描
Medium active:中危漏洞扫描
Intrusive active:侵入漏洞扫描
Javascript analysis:javascript的
漏洞扫描Select individual issues:选择常见漏洞例如sql注入等
忽略的插入点,可以自行设置更改
Crawl and Audit审计配置文件之Handing Application Errors During Audit
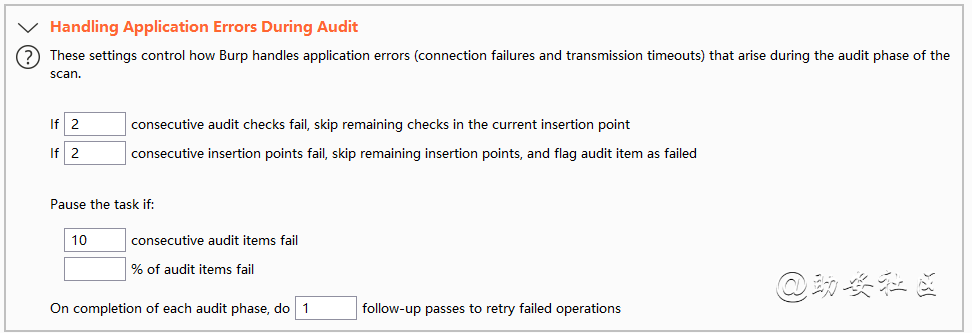
扫描时遇见错误处理,和crawl模块一样
if [2] consecutive audit checks fail,skip remaining checks in the current insertion point如果连续两次进行审计失败的插入点进行跳过
if [2] consecutive insertion points fail,skip remaining insertion points,and flag audit item as failed如果两个插入点失败了,那么所有插入点都进行跳过
consecutive requests time out如果出现多少次爬取失败进行跳过
% of requests time out当站点出现百分之多少时连接超时进行跳过这个站点
Crawl and Audit审计配置文件之Insertion Point Types
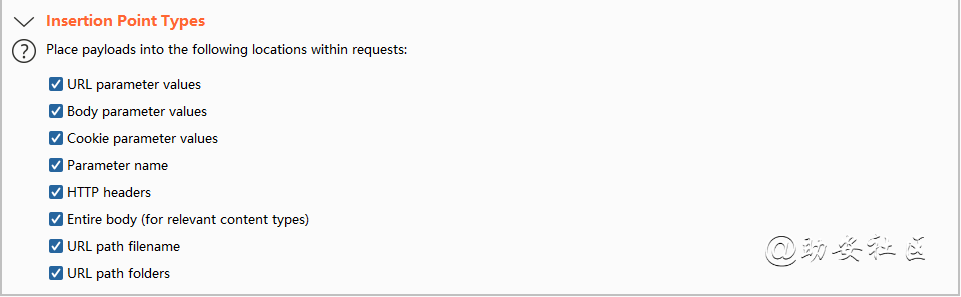
审计插入点配置
URL parameter values:URL地址插入值
Body parameter values:Body里面插入值
Cookie parameter values:Cookie里面插入值
Paramter name:URL参数名字插入(可以造成文件包含漏洞等)
HTTP headers:http消息头插入
Entire body(for relevant conten types):整个body插入
URL path filename:URL地址filename参数插入值
URL path folders:URL中的路径文件夹插入值
Crawl and Audit审计配置文件之Modifying Parameter Locations

Modifying Parameter插入点位置替换,交叉检测
URL to body:将URL中的测试值放在Body中
URL to cookie:将URL中的测试值放在cookie中
Body to URL:将Body测试值放在URL中
Body to cookie:将Body测试值放在cookie中
Cookie to URL:将cookie值的测试值放在URL中
Cookie to body:将cookie值的测试值放在body中
Crawl and Audit审计配置文件之Ignored Insertion Points
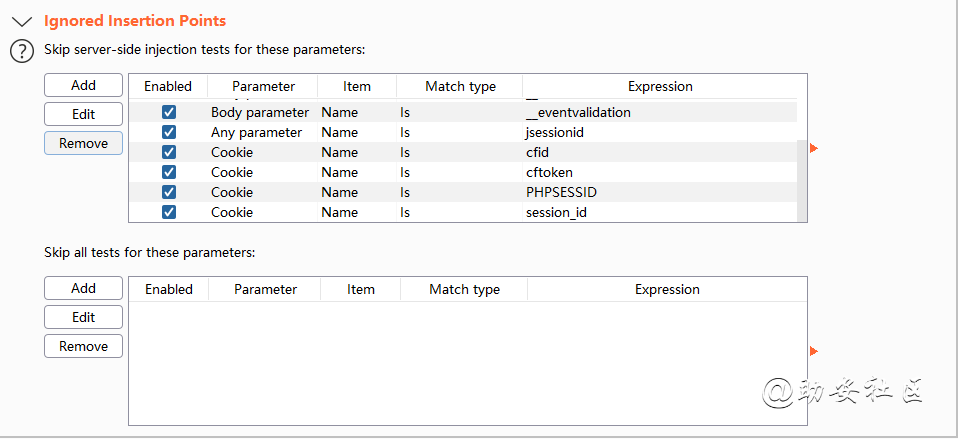
忽略的插入点,可以自行设置更改
Crawl and Audit审计配置文件之Frequently Occurring Insertion Points
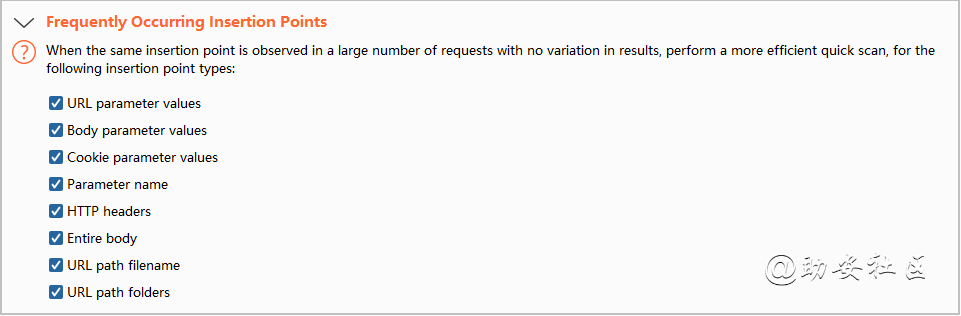
Frequently Occurring Insertion Points:当大量的插入点结果没有区别的时候,更高效的扫描
misc insertion Point Options

杂项插入点选项
javaScript Analysis
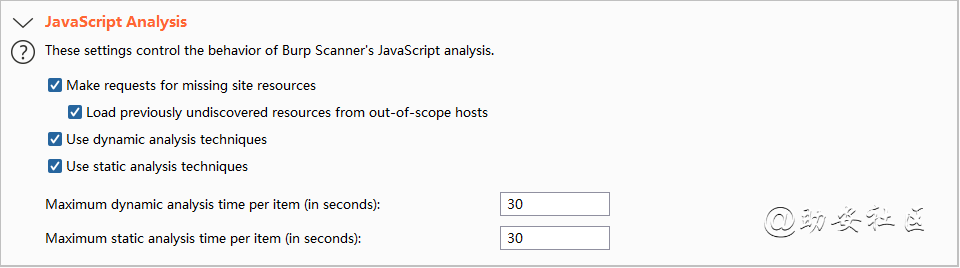
javascript Analysis 分析
Application login
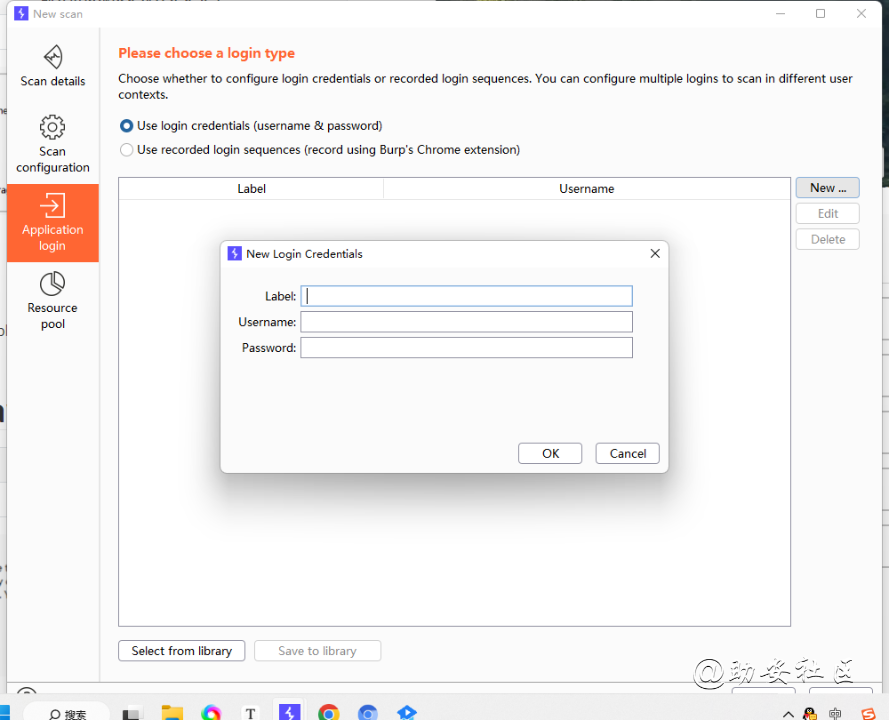
application login设置登录
对于没有验证码的网站,可以使用这个。软件会自动填入账号和密码到需要密码和账号的地方。
Resource pool
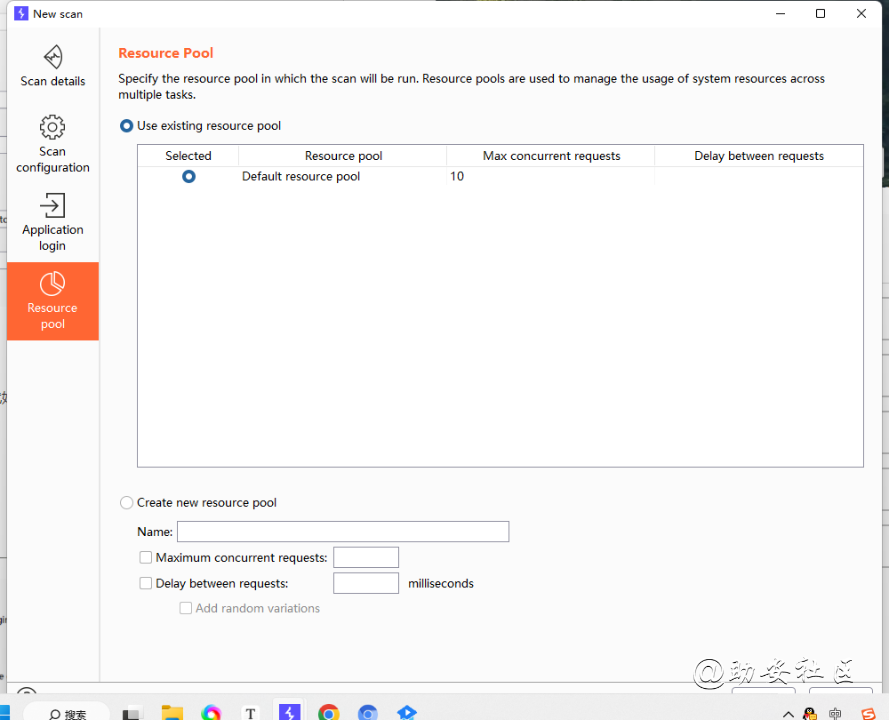
resource pool资源池
设置同时请求数,请求之间间隔多少时间。在Tasks界面也能改。
maximum concurrent同时请求数,delay between requests每个请求间隔
被动式
有爬虫和审计两个功能的设置:
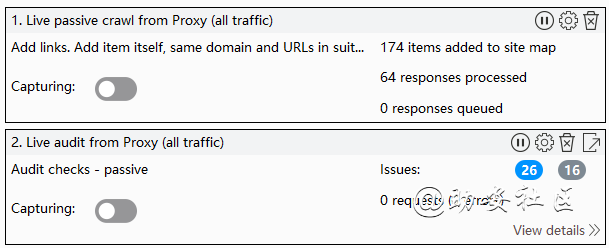
live passive crawl from proxy实时被动爬虫(来自代理所有流量的被动抓取)
live audit from proxy实时审计(来自代理所有流量的实时审计)
被动式是几乎不额外构造请求进行爬虫和扫描,根据用户浏览网页进行常规请求,并对请求的数据进行简单分析。
New live task新的实时任务
Live audit,动态审计
Live passive crawl,动态被动爬虫
Tools scope,选择使用哪种工具作为范围
URL Scope,选择使用url的范围
deduplication,删除重复url,减少重复扫描
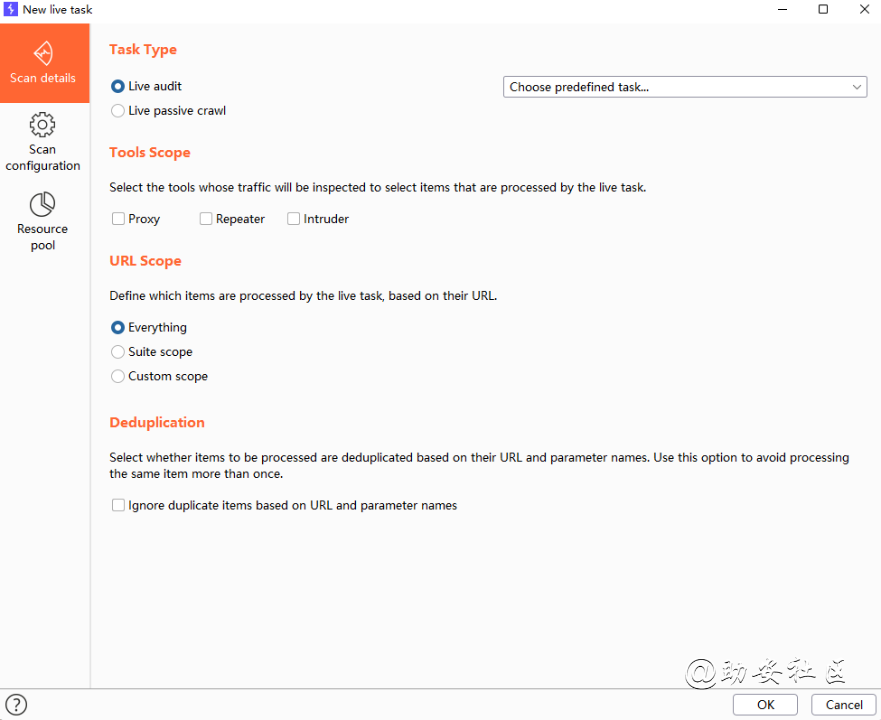
后面的功能和主动扫描基本一样
View Details
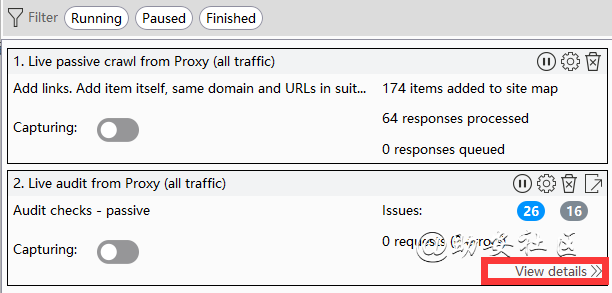
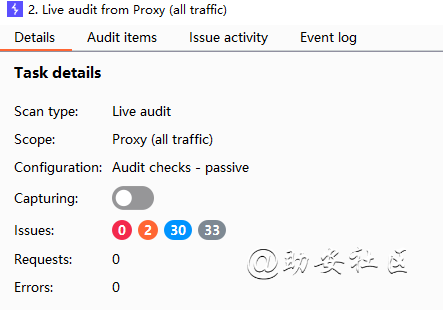
Sacn type:扫描类型
Scope:扫描域名称
Configuration:扫描配置文件
Requests:HTTP请求次数
Errors:连接超时错误次数
Unique locations:发起的单独的地址,可以证明爬取到了很多重复的地址
扫描的过程

发现的漏洞

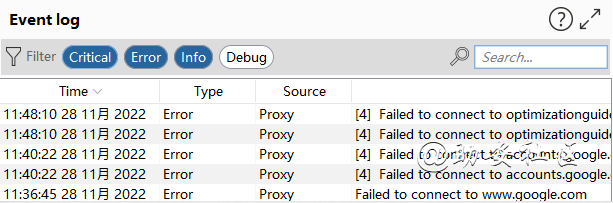
二、Event log日志信息
BurpSuite出现问题可以从这里查看,一般用不到
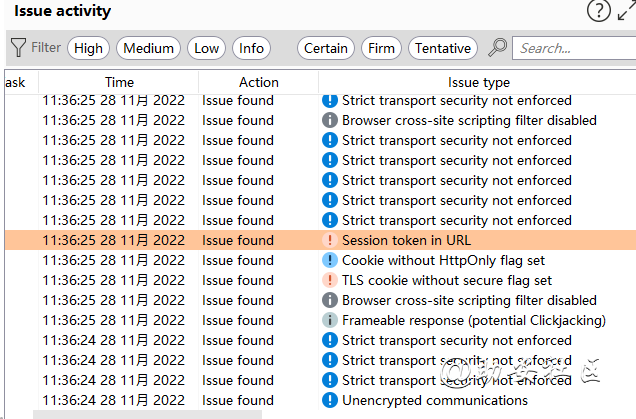
三、Issue activity发现的问题
发现的网站漏洞会出现在这里
HTTP简介
http请求包格式
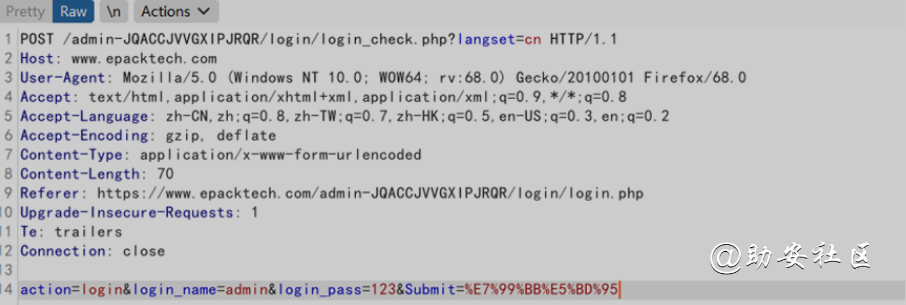
请求方法 请求资源(目录结构/目录文件/传参的参数[GET]) HTTP版本
host: 主机名
User-Agent:客户端基本环境信息
Content-Type:传参的类型
Content-Length: 请求包长度
Referer: 上一步来源。
X-Forwarded-For:当前身份ip
Cookie:用户身份标识
http应答包格式
HTTP版本 返回状态值 服务端自定变量
Date:日期
Server:服务端相关信息
X-Powered-By:当前编程语言环境
Content-Length: 返回包长度
当前响应回客户端(浏览器)的前端代码
http状态值
如果某项请求发送到您的服务器要求显示您网站上的某个网页(例如,用户通过浏览器访问您的网页或 Googlebot 抓取网页时),服务器将会返回 HTTP 状态码响应请求。
此状态码提供关于请求状态的信息,告诉 Googlebot 关于您的网站和请求的网页的信息。
一些常见的状态码为:
200 - 服务器成功返回网页
404 - 请求的网页不存在
503 - 服务器超时
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态码。
100(继续) 请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)表示成功处理了请求的状态码。
200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果是对您的 robots.txt 文件显示此状态码,则表示 Googlebot 已成功检索到该文件。
201(已创建) 请求成功并且服务器创建了新的资源。
202(已接受) 服务器已接受请求,但尚未处理。
203(非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204(无内容) 服务器成功处理了请求,但没有返回任何内容。
205(重置内容) 服务器成功处理了请求,但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向) 要完成请求,需要进一步操作。通常,这些状态码用来重定向。Google 建议您在每次请求中使用重定向不要超过 5 次。您可以使用网站管理员工具查看一下 Googlebot 在抓取重定向网页时是否遇到问题。诊断下的网络抓取页列出了由于重定向错误导致 Googlebot 无法抓取的网址。
300(多种选择) 针对请求,服务器可执行多种操作。服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301(永久移动) 请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
302(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
303(查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改) 自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。如果网页自请求者上次请求后再也没有更改过,您应将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,进而节省带宽和开销。
305(使用代理) 请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。
307(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来响应以后的请求。此代码与响应 GET 和 HEAD 请求的 <a href=answer.py?answer=>301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个页面或网站已经移动,因为 Googlebot 会继续抓取原有位置并编制索引。
4xx(请求错误) 这些状态码表示请求可能出错,妨碍了服务器的处理。
400(错误请求) 服务器不理解请求的语法。
401(未授权) 请求要求身份验证。对于登录后请求的网页,服务器可能返回此响应。
403(禁止) 服务器拒绝请求。如果您在 Googlebot 尝试抓取您网站上的有效网页时看到此状态码(您可以在 Google 网站管理员工具诊断下的网络抓取页面上看到此信息),可能是您的服务器或主机拒绝了 Googlebot 访问。
404(未找到)
服务器找不到请求的网页。例如,对于服务器上不存在的网页经常会返回此代码。
如果您的网站上没有 robots.txt 文件,而您在 Google 网站管理员工具"诊断"标签的 robots.txt 页上看到此状态码,则这是正确的状态码。但是,如果您有 robots.txt 文件而又看到此状态码,则说明您的 robots.txt 文件可能命名错误或位于错误的位置(该文件应当位于顶级域,名为 robots.txt)。
如果对于 Googlebot 抓取的网址看到此状态码(在"诊断"标签的 HTTP 错误页面上),则表示 Googlebot 跟随的可能是另一个页面的无效链接(是旧链接或输入有误的链接)。
405(方法禁用) 禁用请求中指定的方法。
406(不接受) 无法使用请求的内容特性响应请求的网页。
407(需要代理授权) 此状态码与 <a href=answer.py?answer=35128>401(未授权)类似,但指定请求者应当授权使用代理。如果服务器返回此响应,还表示请求者应当使用代理。
408(请求超时) 服务器等候请求时发生超时。
409(冲突) 服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,以及两个请求的差异列表。
410(已删除) 如果请求的资源已永久删除,服务器就会返回此响应。该代码与 404(未找到)代码类似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。如果资源已永久移动,您应使用 301 指定资源的新位置。
411(需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415(不支持的媒体类型) 请求的格式不受请求页面的支持。
416(请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态码。
417(未满足期望值) 服务器未满足"期望"请求标头字段的要求。
5xx(服务器错误)这些状态码表示服务器在处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
500(服务器内部错误) 服务器遇到错误,无法完成请求。
501(尚未实施) 服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
502(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503(服务不可用) 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
504(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505(HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号