
Java SPI机制实战详解及源码分析
背景介绍
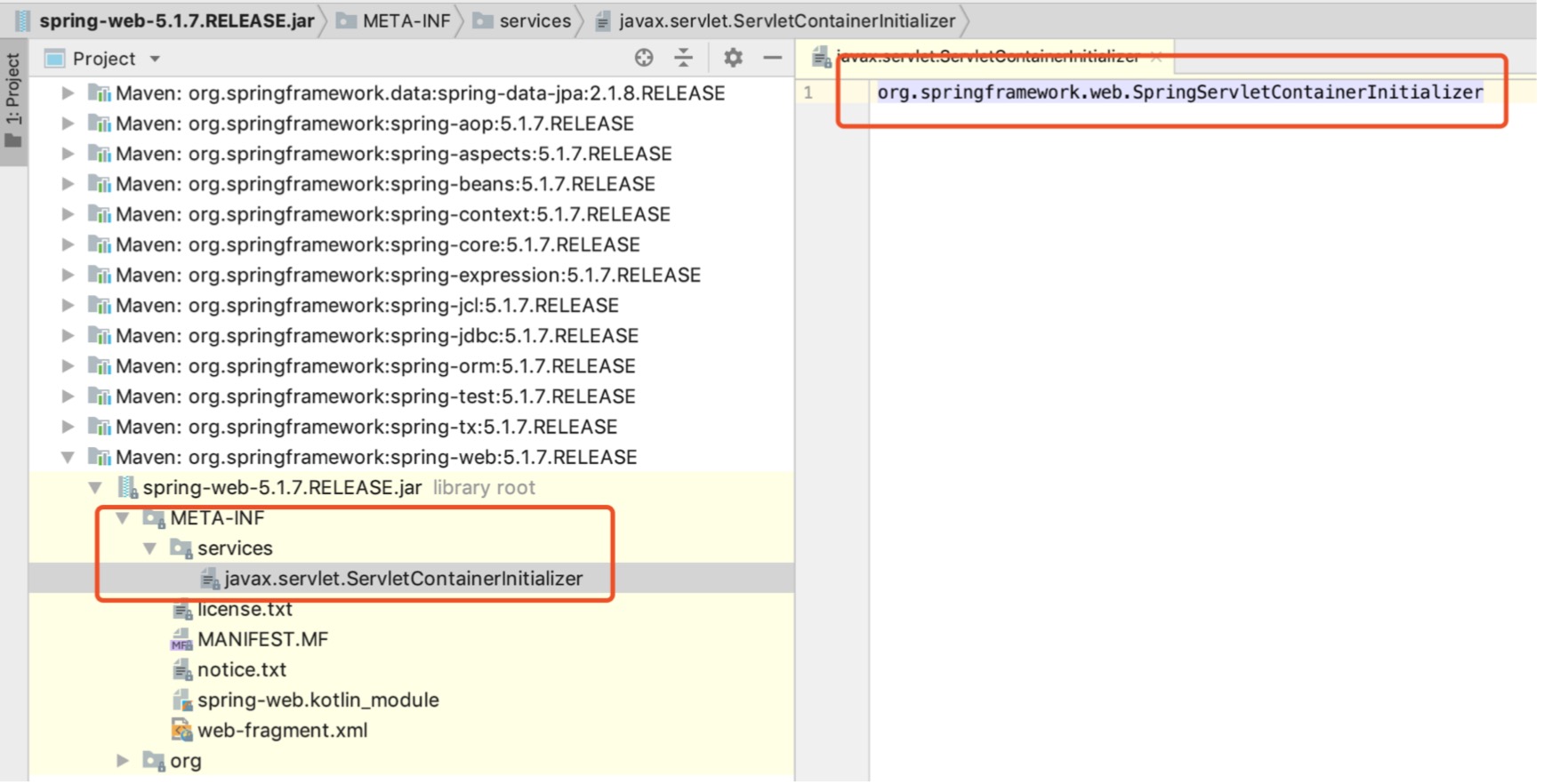
提起SPI机制,可能很多人不太熟悉,它是由JDK直接提供的,全称为:Service Provider Interface。而在平时的使用过程中也很少遇到,但如果你阅读一些框架的源码时,会发现它的有点无处不在的感觉。比如我们经常使用的spring框架,其spring-web包下就在使用该机制。
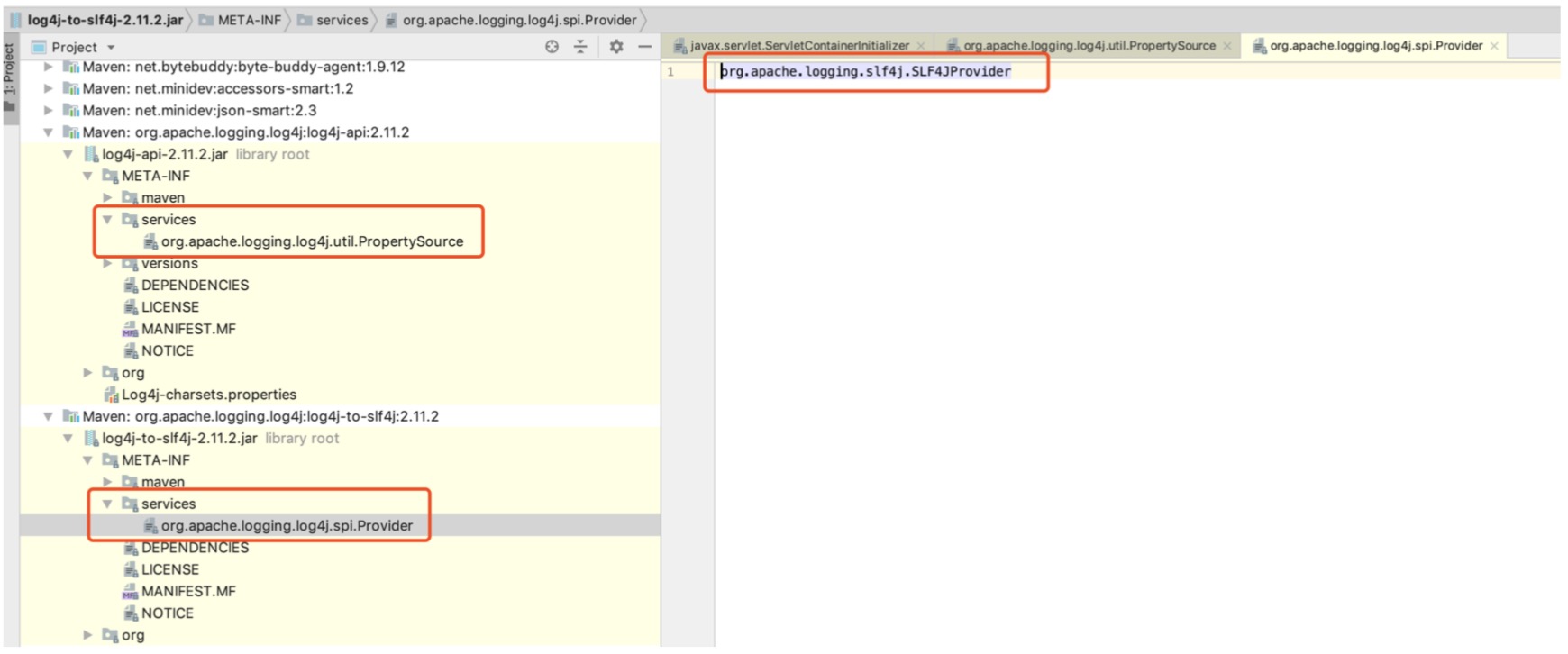
还有我们每个项目都离不开的日志框架log4j和数据库驱动框架中也同样的使用着SPI机制。
这么看来,SPI机制可谓无处不在,那么今天这篇文章就带大家揭开它的神秘面纱。
什么是SPI机制
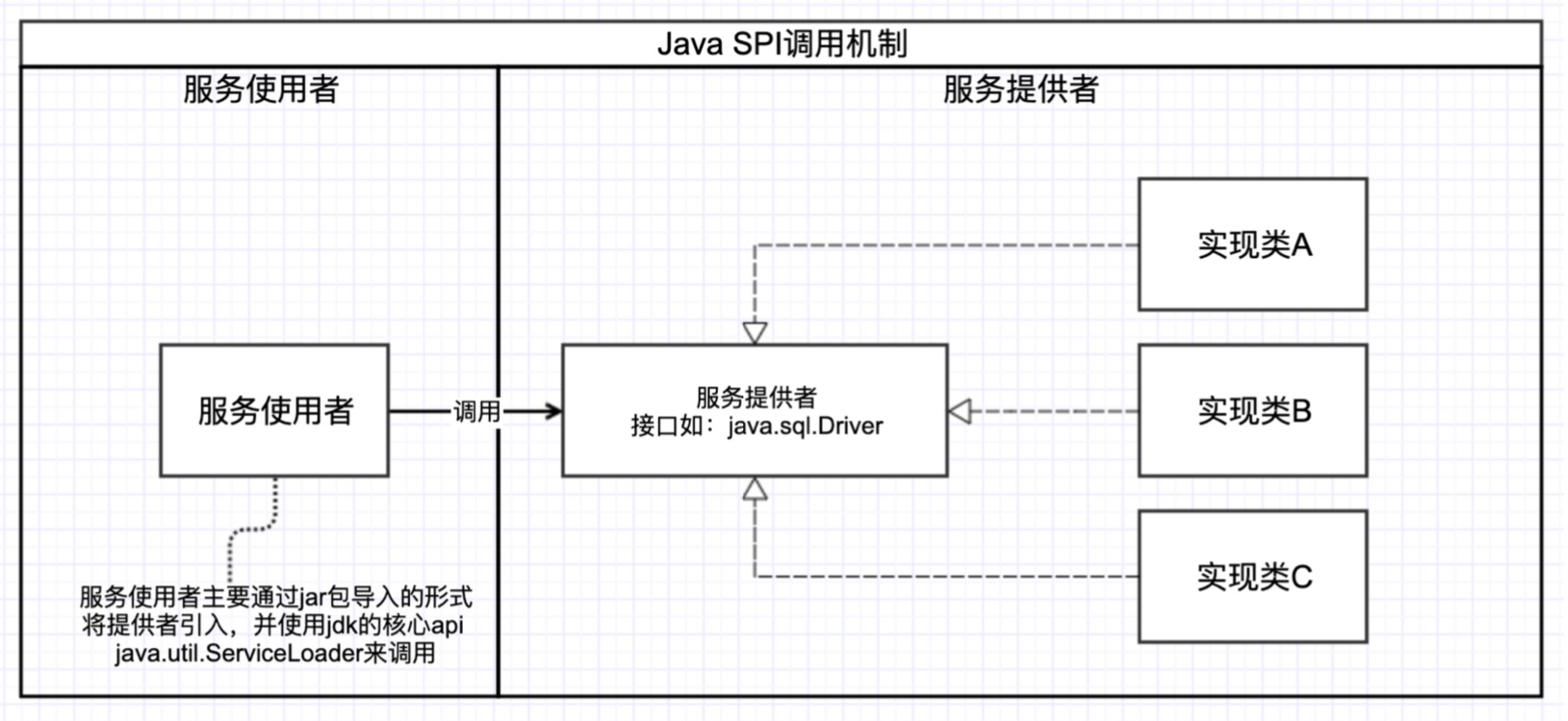
SPI机制,全称 Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,可以用来启用框架扩展和替换组件,它的核心类是java.util.ServiceLoader。
在大型系统设计中,开闭原则和解耦是必不可少的,而SPI机制的核心便是解耦合。通过SPI机制,将实现类隐藏在接口后面,根据需要寻找服务实现,SPI就提供了这样的服务发现机制。
Effective Java中也提到SPI是一种将服务接口与服务实现分离以达到解耦、大大提升了程序可扩展性的机制。引入服务提供者就是引入了SPI接口的实现者,通过本地的注册发现获取到具体的实现类,轻松可插拔。
使用场景
在最开始的背景介绍中,我们已经在不同的框架中发现SPI的身影。可以说在针对“调用者根据实际需要,使用不同框架的实现策略”中非常有用。
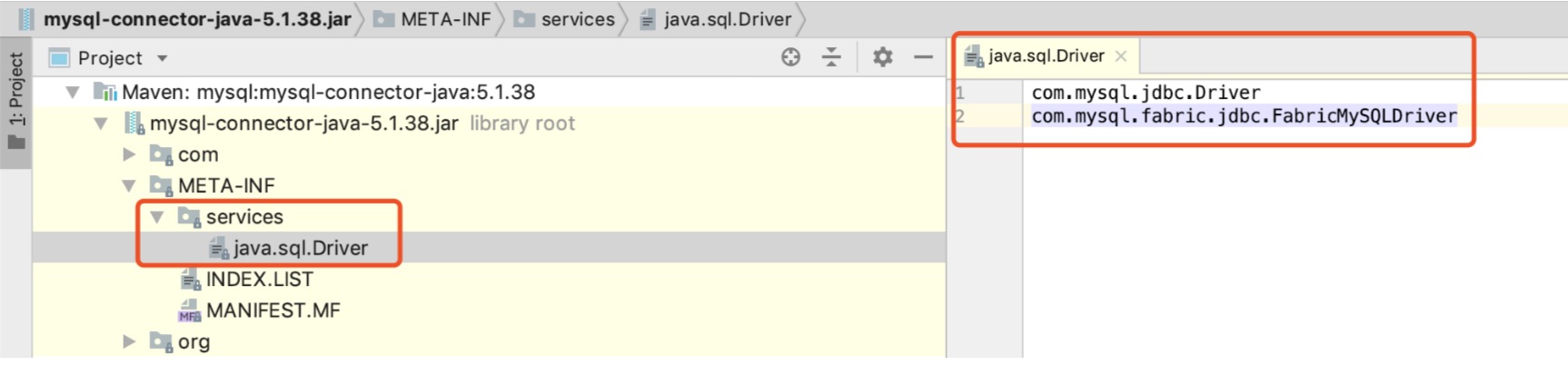
比如,我们日常使用是数据库驱动,会提供统一的规范(java.sql.Driver),各数据库服务商提供对应数据库的逻辑实现。当使用到该数据库时,直接引入不同的SPI服务实现即可。
常见场景:
- Spring框架中有大量实现,如上图中Spring对servlet3.0规范的ServletContainerInitializer的实现。
- 数据库驱动程序加载不同数据库的实现,如上图中java.sql.Driver接口的实现。
- 日志框架log4j中的实现。
- Dubbo中实现框架扩展的实现。
使用规范
下面了解一下使用SPI的基本规范步骤:
- 服务提供者定义对外接口及方法,比如数据库驱动会提供一个java.sql.Driver的接口。
- 针对定义的接口,提供一个实现类。
- 在项目或jar包的META-INF/services目录下,创建一个文本文件:名称为接口的“全限定名”,内容为实现类的全限定名。上面的截图中其实已经可以发现,统一都是如此。
- 服务调用者引入该项目的jar包,并将其放置于classpath下。
- 服务调用者通过核心API java.util.ServiceLoader来动态加载该实现,主要就是扫描classpath下所有jar包内META-INF/services目录下,按照指定格式定义的文件,并把其中类进行加载。
- 由于SPI机制使用的过程中无法进行传递构造参数,因此需提供一个无参的构造方法。
具体实例
下面以订阅公众号为例,来演示SPI机制的使用。为了方便起见,服务使用者和服务提供者放在了同一个项目内,正常来说,服务提供者单独定义接口及实现,然后通过jar包的形式引入到服务调用者项目中。
首先,创建项目,定义接口Subscribe,并提供一个follow方法。
public interface Subscribe {
void follow();
}
然后,定义两个实现类:MySubscribe和OtherSubscribe。
public class MySubscribe implements Subscribe {
@Override
public void follow() {
System.out.println("关注了公众号:程序新视界!");
}
}
public class OtherSubscribe implements Subscribe {
@Override
public void follow() {
System.out.println("关注了其他公众号!");
}
}
然后,在resources目录下依次创建META-INF/services目录,并在目录下创建名称为:com.secbro2.Subscribe的文件。文件内容为:
com.secbro2.impl.MySubscribe
com.secbro2.impl.OtherSubscribe
最后,编写main方法进行调用,main方法相当于SPI机制中的调用者。
public class Call {
public static void main(String[] args) {
ServiceLoader<Subscribe> services = ServiceLoader.load(Subscribe.class);
for (Subscribe sub : services) {
sub.follow();
}
}
}
执行main方法,打印如下内容:
关注了公众号:程序新视界!
关注了其他公众号!
ServiceLoader源码解析
顺便我们看一下ServiceLoader的源码信息,首先通过常量的定义,我们可以看到为什么要将文件配置在META-INF/services下了。
public final class ServiceLoader<S> implements Iterable<S>{
private static final String PREFIX = "META-INF/services/";
}
整个类的源码就不全部贴出了,简单介绍一下该类的基本操作流程。
- 通过ServiceLoader的load(Class<S> service)方法进入程序内部;
- 上面load方法内获得到ClassLoader,并再此调用内部的load(Class<S> service,lassLoader loader)方法,该方法内会创建ServiceLoader对象,并初始化一些常量。
- ServiceLoader的构造方法内会调用reload方法,来清理缓存,初始化LazyIterator,注意此处是Lazy,也就懒加载。此时并不会去加载文件下的内容。
- 当遍历器被遍历时,才会去读取配置文件。
关于读取META-INF/services下配置文件的核心代码如下:
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
同过以上代码我们会发现,其实ServiceLoader扫描了所有jar包下的配置文件。然后通过解析全限定名获得,并在遍历时通过Class.forName进行实例化。
小结
经过上面的讲解和示例,大家已经了解整个SPI机制的使用,但SPI机制并不是万能的,它也有自身的缺点。比如,虽然它采用了懒加载,在真正遍历使用的时候才会去加载类,但每次基本上都是将全部的类遍历一遍并进行实例化,这也造成了不必要的浪费。另外,它是非线程安全的。
原文链接:《Java SPI机制实战详解及源码分析》


 浙公网安备 33010602011771号
浙公网安备 33010602011771号