

h2 ---database
processes = 500 # Max. no. of users x 2
sessions = 1000 # 2 X processes
修改完之后,重启DB,参数就会生效。
addbctl.sh stopaddbctl.sh start
查看参数设置
show parameter processesshow parameter sessions
文章Oracle EBS DB Init Parameters里,有提到Oracle提供一个init parameter参考的设置。
关于Processes和sessions parameters,init.ora有相关描述
#########
#
# Processes and sessions parameters
#
# A database process can be associated with one or more database
# sessions. For all technology stack components other than Oracle
# Forms, there is a one-to-one mapping between sessions and processes.
#
# For Forms processes, there will be one database session per
# open form, with a minimum of two sessions per Forms user (one
# for the navigator form, and one for the active form).
#
# The sessions parameter should be set to twice the value of the
# processes parameter.
#
#########
另外如何查询当下数据的连接数和最大连接数
转载请注明出处:http://blog.csdn.net/pan_tian/article/details/7730028
======EOF======
刚刚写完(一),本来想把两篇写在一起,但是发现关联不大,最后觉得分开写:
本文来自:http://blog.csdn.net/lengzijian/article/details/7729465
先写上数据库配置:
一个主数据库,两个从数据库
主数据库:Intel(R) Pentium(R) D CPU 2.80GHz *2 | MemTotal: 1027072 kB
从库1 :Pentium(R) Dual-Core CPU E5200 @ 2.50GHz| MemTotal: 2066020 kB
从库2 :Pentium(R) Dual-Core CPU E5200 @ 2.50GHz| MemTotal: 2066020 kB
本人自己写了c语言的测试脚本,用到了libpq c库,这里附上源码:
编译方法:
使用方法:
由于本人机器并非服务器,所以数据只用来参考,希望读者可以用上面的代码,测试服务器上主机后,发送给本人,本人不胜感激!!!!
直接上数据:
|
线程数量 |
每个线程插入次数 |
总时间(s) |
每秒处理次数 |
|
1 |
1000 |
0.684 |
1461.988304 |
|
1 |
10000 |
6.56 |
1524.390244 |
|
1 |
50000 |
33.008 |
1514.784295 |
|
1 |
100000 |
76.972 |
1299.173726 |
|
2 |
1000 |
0.83 |
2409.638554 |
|
2 |
10000 |
7.96 |
2512.562814 |
|
2 |
50000 |
41 |
2439.02439 |
|
2 |
100000 |
95.675 |
2090.410243 |
|
3 |
1000 |
1.15 |
2608.695652 |
|
3 |
10000 |
11.99 |
2502.085071 |
|
3 |
50000 |
70.98 |
2113.271344 |
|
3 |
100000 |
163.4 |
1835.985312 |
|
5 |
1000 |
1.22 |
4098.360656 |
|
5 |
10000 |
15.9 |
3144.654088 |
|
5 |
50000 |
82.9 |
3015.681544 |
|
5 |
100000 |
118.4034 |
4222.852386 |
|
10 |
1000 |
1.830302 |
5463.579234 |
|
10 |
10000 |
16.94417 |
5901.736326 |
|
10 |
50000 |
87.61617 |
5706.709487 |
|
10 |
100000 |
179.2664 |
5578.290561 |

上次安装了集群后,一段时间没有时间写个测试文章,今天有空就写了篇初级测试的文章,如果大家还想知道不同情况下postgres集群的处理方法,可以留言给我!!!
本文来自:http://blog.csdn.net/lengzijian/article/details/7729380
先来模拟下主从库关闭,看看数据的同步情况:
1. 重启主节点:
|
方式①:./pg_ctl stop -D ../data/ |
|
waiting for server to shut down............................................................... failed pg_ctl: server does not shut down HINT: The "-m fast" option immediately disconnects sessions rather than waiting for session-initiated disconnection. 虽然显示关闭失败,但是连接数据库操作已经不可用,并且显示错误!!! |
|
方式②./pg_ctl stop -D ../data/ -m fast |
|
直接关闭数据库,连接数据库时,显示没有服务。 重启主节点后,对集群功能没有影响 |
|
方式③:kill -9 8581 8582 8584 8585 8586 8587 8589 8597 8669 |
|
向其中一台从节点插入一条数据; (这里理论上是可读,但是为了方便展示还是插入一条) insert failed:ERROR: cannot execute INSERT in a read-only transaction 启动主节点,插入一条数据,并验证集群功能:
集群功能完好! |

2. 关闭从节点
|
关闭方式①:./pg_ctl stop -D ../data_bac/ -m fast |
|
插入主节点一条数据,再打开从节点,查看数据是否同步。
数据同步成功。 |
|
关闭方式②:kill -9 19971 19972 19973 19974 19975 19976 |
|
插入二条数据后;正常启动子节点,查看数据是否同步:
可以看到自己点意外死亡情况,重启后会同步数据。 |

3. 在插入过程中杀死主节点
|
关闭方式①:./pg_ctl stop -D ../data_bac/ -m fast |
|
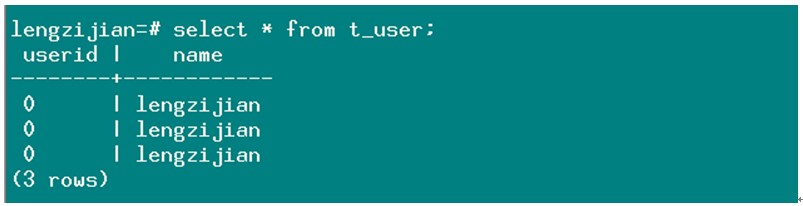
用单线程方式,插入100000数据,并在中途按方式①,关闭主节点;重启后查看主库和从库数据是否一致: 1. 当断开后,查看两个从库的数据量都为5719
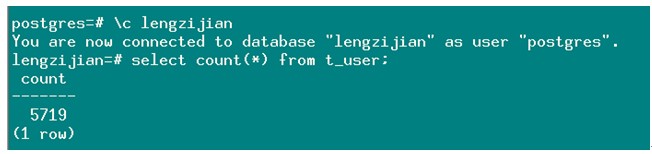
2. 重启主数据库,查看数据量:
发现数据没有丢失,为了验证正确性,我们验证10个线程每个线程100000并发时,没有丢数据情况发生。 |
|
关闭方式②:kill -9 19971 19972 19973 19974 19975 19976 |
|
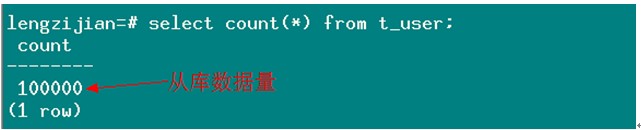
查看从库数据量:
启动主库,查看主库数据量:
可以发现主库和从库数据量不等,有人可能会说丢数据,先别下太早的结论,我们再来看下从库数据量是否有变化:
我们可以认为,当主节点意外死亡时,主库wal日志还没有发送到从库主机,使得主从库数据不同步,但是重启主库后,主库会把没有传递的wal日志重发,再次同步数据。 |



上面是我模拟的一些集群会遇到的情况,目前只能想到这么多,如果有建议可以留言。
Oracle EBS里查看数据库参数
路径:System Administration > Oracle Applications Manager > Initialization Parameters或者
路径:System Administration > Oracle Applications Manager > System Configuration Overview > Database > Init.ora Parameters
可以查看DB的数据库parameter(init.ora或者pfile parameter)

关于Oracle Parameter可以参见我之前写得帖子:Oracle Parameters
如果是使用的init<sid>.ora的话,这个DB参数文件默认放在$RDBMS_ORACLE_HOME/dbs/init<sid>.ora
你可以在这个文件中修改DB参数,注意,修改完之后,需要重启数据库才能生效。
EBS的DB init.ora参数文件的设置
另外这里有两篇不错的metalink notes可以帮助你来设置EBS的init.ora参数文件,给出了一些设置的建议
Note: 216205.1 - Database Initialization Parameters for Oracle Applications Release 11i
Note: 396009.1 - Database Initialization Parameters for Oracle Applications Release 12
Index for Note 396009.1
This document describes the database initialization parameter settings required for Oracle E-Business Suite Release 12.
- Section 1: Common Database Initialization Parameters For All Releases
- Section 2: Release-Specific Database Initialization Parameters For Oracle 10g Release 2
- Section 3: Release-Specific Database Initialization Parameters For Oracle 11g Release 1
- Section 4: Release-Specific Database Initialization Parameters For Oracle 11g Release 2
- Section 5: Using System Managed Undo (SMU)
- Section 6: Temporary Tablespace Setup
- Section 7: Database Initialization Parameter Sizing
* The document consists of a common section, which provides a common set of database initialization parameters used for all releases of the Oracle Database, followed by several release-specific sections, which list parameters and settings required for a particular release of the Oracle Database.
* Put together, the parameters from the common section and appropriate release-specific section formulate a complete set of database initialization parameters.
* Parameters may appear on a removal list either because they are obsolete, or because the default value is required and no other value may be set.
* In the various parameter lists, check for comments giving any platform-specific exceptions. Such comments will apply only to the exact platform mentioned: for example, a reference to HP-UX (PA-RISC) will not apply to HP-UX (Itanium IA-64).
* The "X" notation used in the release-specific section denotes all patchset releases within that major version. For example, "10.2.0.X" refers to all releases of 10.2.0, such as 10.2.0.2 and 10.2.0.3.
* Oracle E-Business Suite Release 12 requires Oracle Database 10g Release 2 (10.2.0.2) Enterprise Edition as a minimum release level and edition. No earlier releases, or other editions of any release, may be used.
Database Initialization Parameter Sizing
关于DB Parameter Sizing,Oracle根据用户数提供了一个参考的设置列表

Footnote 1
The parameter sga_target should be used for Oracle 10g or 11g based environments such as Release 12. This replaces the parameter db_cache_size, which was used in Oracle 9i based environments. Also, it is not necessary to set the parameter undo_retention for 10g or 11g-based systems, since undo retention is set automatically as part of automatic undo tuning.
Enabling the 11g Automatic Memory Management (AMM) feature is supported in EBS, and has been found to be useful in scenarios where memory is limited, as it will dynamically adjust the SGA and PGA pool sizes. AMM is enabled by using the memory_target and memory_max_target initialization parameters. MEMORY_TARGET specifies the system-wide sharable memory for Oracle to use when dynamically controlling the SGA and PGA as workloads change. The memory_max_target parameter specifies the maximum size that memory_target may take. AMM has proven useful for small to mid-range systems as it simplifies both the configuration and management. However, many customers with large production systems have experienced better performance with manually sized pools (or large minimum values for the pools). On Linux, Hugepages has resulted in improved performance; however, this configuration is not compatible with AMM. For large mission-critical applications systems, it is advisable to set sga_target with a minimum fixed value for shared_pool_size and pga_aggregate_target.
Footnote 2
The total memory required refers to the amount of memory required for the database instance and associated memory, including the SGA and the PGA. You should ensure that your system has sufficient available memory in order to support the values provided above. The values provided above should be adjusted based on available memory so as to prevent paging and swapping.
转载请注明出处:http://blog.csdn.net/pan_tian/article/details/7728738
======EOF======
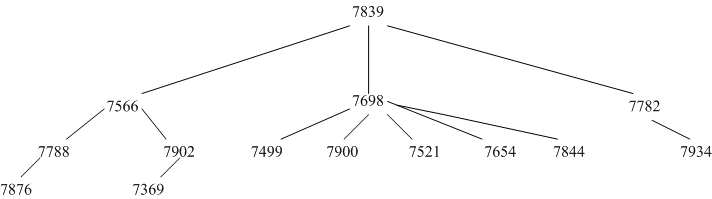
图1.1 EMP表树结构图
在这个树结构中,如果一个节点有直接的下属节点(如图中的7566有下属7788 和7902),那么称该节点是下属节点的父节点,下属节点为该节点的子节点。通过雇员的EMPNO和MGR可以看出他们之间的父子节点关系,父节点的 EMPNO与子节点的MGR相同。在树结构中,有且仅有一个节点无父节点,如图中的7839(KING),该节点被称为根节点。从图上的标记可以看出,只有KING的 MGR为空值。除根节点外,任何节点只有一个父节点,有一个,多个或没有子节点。
在扫描树结构表时,需要依此访问树结构的每个节点,一个节点只能访问一次,其访问的步骤如下:
第一步:从根节点开始;
第二步:访问该节点;
第三步:判断该节点有无未被访问的子节点,若有,则转向它最左侧的未被访问的子节,并执行第二步,否则执行第四步;
第四步:若该节点为根节点,则访问完毕,否则执行第五步;
第五步:返回到该节点的父节点,并执行第三步骤。
总之:扫描整个树结构的过程也即是中序遍历树的过程。
1. 树结构的描述
树结构的数据存放在表中,数据之间的层次关系即父子关系,通过表中的列与列间的关系来描述,如 EMP表中的EMPNO和MGR。EMPNO表示该雇员的编号,MGR表示领导该雇员的人的编号,即子节点的MGR值等于父节点的EMPNO值。在表的每 一行中都有一个表示父节点的MGR(除根节点外),通过每个节点的父节点,就可以确定整个树结构。
在SELECT命令中使用CONNECT BY 和蔼START WITH 子句可以查询表中的树型结构关系。其命令格式如下:
SELECT 。。。
CONNECT BY {PRIOR 列名1=列名2|列名1=PRIOR 裂名2}
[START WITH];
其中:CONNECT BY子句说明每行数据将是按层次顺序检索,并规定将表中的数据连入树型结构的关系中。PRIORY运算符必须放置在连接关系的两列中某一个的前面。对于节 点间的父子关系,PRIOR运算符在的一侧表示父节点,在另一侧表示子节点,从而确定查找树结构是的顺序是自顶向下还是自底向上。在连接关系中,除了可以 使用列名外,还允许使用列表达式。START WITH 子句为可选项,用来标识哪个节点作为查找树型结构的根节点。若该子句被省略,则表示所有满足查询条件的行作为根节点。
例1 以树结构方式显示EMP表的数据。
SQL>select empno,ename,mgr
from emp
connect by prior empno=mgr
start with empno=7839
EMPNO ENAME MGR
----- ---------- -----
7839 KING
7566 JONES 7839
7788 SCOTT 7566
7876 ADAMS 7788
7902 FORD 7566
7369 SMITH 7902
7698 BLAKE 7839
7499 ALLEN 7698
7521 WARD 7698
7654 MARTIN 7698
7844 TURNER 7698
7900 JAMES 7698
7782 CLARK 7839
7934 MILLER 7782
14 rows selected
仔细看empno这一列输出的顺序,就是上图树状结构每一条分支(从根节点开始)的结构。
2. 关于PRIOR
运算符PRIOR被放置于等号前后的位置,决定着查询时的检索顺序。
PRIOR被置于CONNECT BY子句中等号的前面时,则强制从根节点到叶节点的顺序检索,即由父节点向子节点方向通过树结构,我们称之为自顶向下的方式。如:
CONNECT BY PRIOR EMPNO=MGR
(父节点与子节点的关系,在表内存储的数据上体现)
PIROR运算符被置于CONNECT BY 子句中等号的后面时,则强制从叶节点到根节点的顺序检索,即由子节点向父节点方向通过树结构,我们称之为自底向上的方式。例如:
CONNECT BY EMPNO=PRIOR MGR
在这种方式中也应指定一个开始的节点。
例2 从SMITH节点开始自底向上查找EMP的树结构。
SQL>select empno,ename,mgr
from emp
connect by empno=prior mgr
start with empno=7369
EMPNO ENAME MGR
----- ---------- -----
7369 SMITH 7902
7902 FORD 7566
7566 JONES 7839
7839 KING
在这种自底向上的查找过程中,只有树中的一枝被显示,这是因为,在树结构中每一个节点只允许有一个父节点,其查找过程是从开始节点起,找到其父节点,再由其父节点向上,找父节点的父节点。这样一直找到根节点为止,结果就是树中一枝的数据。
备注:例2的另外一种写法
SELECT EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR MGR=EMPNO
START WITH EMPNO=7369;
3. 定义查找起始节点
在自顶向下查询树结构时,不但可以从根节点开始,还可以定义任何节点为起始节点,以此开始向下查找。这样查找的结果就是以该节点为开始的结构树的一枝。
例3 查找7566(JONES)直接或间接领导的所有雇员信息。
SQL>SELECT EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
START WITH EMPNO=7566;
EMPNO ENAME MGR
----- ---------- -----
7566 JONES 7839
7788 SCOTT 7566
7876 ADAMS 7788
7902 FORD 7566
7369 SMITH 7902
START WITH 不但可以指定一个根节点,还可以指定多个根节点。
例4 查找由FORD和BLAKE 领导的所有雇员的信息。
SQL>SELECT EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
START WITH ENAME IN (’FORD’,’BLAKE’);
EMPNO ENAME MGR
--------------------------
7698 BLAKE 7839
7499 ALLEN 7698
7521 WARD 7698
7654 MARTIN 7698
7844 TURNER 7698
7900 JAMES 7698
7902 FORD 7566
7369 SMITH 7902
8 rows selected.
在自底向上查询树结构时,也要指定一个开始节点,以此开始向上查找其父节点,直至找到根节点,其结果将是结构树中的一枝数据。
4.使用LEVEL
在具有树结构的表中,每一行数据都是树结构中的一个节点,由于节点所处的层次位置不同,所以每行记录都可以有一个层号。层号根据节点与根节点的距离确定。不论从哪个节点开始,该起始根节点的层号始终为1,根节点的子节点为2, 依此类推。
在查询中,可以使用伪列LEVEL显示每行数据的有关层次。LEVEL将返回树型结构中当前节点的层次,我们可以使用LEVEL来控制对树型结构进行遍历的深度。
例5显示EMP表中的各行数据及层号。
SQL>SELECT LEVEL,EMPNO,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
START WITH ENAME=‘KING’
/
LEVEL EMPNO ENAME MGR
1 7839 KING
2 7566 JONES 7839
3 7788 SCOTT 7566
4 7876 ADAMS 7788
3 7902 FORD 7566
4 7369 SMITH 7902
2 7698 BLAKE 7839
3 7499 ALLEN 7698
3 7521 WARD 7698
3 7654 MARTIN 7698
3 7844 TURNER 7698
3 7900 JAMES 7698
2 7782 CLARK 7839
3 7934 MILLER 7782
14 rows selected.
伪列LEVEL为数值型,可以在SELECT 命令中用于各种计算。
例6 使用LEVEL改变查询结果的显示形式。
SQL> COLUMN LEVEL FORMAT A20
SQL> SELECT LPAD(LEVEL,LEVEL*3,' ') as "LEVEL",EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
START WITH ENAME='KING'
/
LEVEL EMPNO ENAME MGR
在SELECT使用了函数LPAD,该函数表示以LEVEL*3个空格进行填充,由于不同行处于不同的节点位置,具有不同的LEVEL值,因此填充的空格数将根据各自的层号确定,空格再与层号拼接,结果显示出这种层次关系。
5.节点和分支的裁剪
在对树结构进行查询时,可以去掉表中的某些行,也可以剪掉树中的一个分支,使用WHERE子句来限定树型结构中的单个节点,以去掉树中的单个节点,但它却不影响其后代节点(自顶向下检索时)或前辈节点(自底向顶检索时)。
例7 仅剪去了树中单个节点SCOTT
SQL>SELECT LPAD(LEVEL,LEVEL*3,' ') as "LEVEL",EMPNO,ENAME,MGR
FROM EMP
WHERE ENAME!='SCOTT'
CONNECT BY PRIOR EMPNO=MGR
START WITH ENAME='KING'
/
LEVEL EMPNO ENAME MGR
--------------- ---------- ---------- ----------
1 7839 KING
2 7566 JONES 7839
4 7876 ADAMS 7788
3 7902 FORD 7566
4 7369 SMITH 7902
2 7698 BLAKE 7839
3 7499 ALLEN 7698
3 7521 WARD 7698
3 7654 MARTIN 7698
3 7844 TURNER 7698
3 7900 JAMES 7698
LEVEL EMPNO ENAME MGR
--------------- ---------- ---------- ----------
2 7782 CLARK 7839
3 7934 MILLER 7782
已选择13行。
在这个查询中,仅剪去了树中单个节点SCOTT。若希望剪去树结构中的某个分支,则要用CONNECT BY 子句。CONNECT BY 子句是限定树型结构中的整个分支,既要剪除分支上的单个节点,也要剪除其后代节点(自顶向下检索时)或前辈节点(自底向顶检索时)。
例8.显示KING领导下的全体雇员信息,除去SCOTT领导的一支。
SQL> SELECT LPAD(LEVEL,LEVEL*3,' ') as "LEVEL",EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
AND ENAME!='SCOTT'
START WITH ENAME='KING'
/
LEVEL EMPNO ENAME MGR
已选择12行。
这个查询结果就与例7不同,除了剪去单个节点SCOTT外,还将SCOTT的子节点ADAMS剪掉,即把SCOTT这个分支剪掉了。
当然WHERE子句可以和CONNECT BY子句联合使用,这样能够同时剪掉单个节点和树中的某个分支。
例9.显示KING领导全体雇员信息,除去雇员SCOTT,以及BLAKE领导的一支。
这个留给大家实践吧:)
6.排序显示
像在其它查询中一样,在树结构查询中也可以使用ORDER BY 子句,改变查询结果的显示顺序,而不必按照遍历树结构的顺序。
例10 以EMPNO的顺序显示树结构EMP 中的数据。
SQL> SELECT LPAD(LEVEL,LEVEL*3,' ') as "LEVEL",EMPNO,ENAME,MGR
FROM EMP
CONNECT BY PRIOR EMPNO=MGR
START WITH ENAME='KING'
ORDER BY EMPNO
/
LEVEL EMPNO ENAME MGR
--------------- ---------- ---------- ----------
4 7369 SMITH 7902
3 7499 ALLEN 7698
3 7521 WARD 7698
2 7566 JONES 7839
3 7654 MARTIN 7698
2 7698 BLAKE 7839
2 7782 CLARK 7839
3 7788 SCOTT 7566
1 7839 KING
3 7844 TURNER 7698
4 7876 ADAMS 7788
LEVEL EMPNO ENAME MGR
--------------- ---------- ---------- ----------
3 7900 JAMES 7698
3 7902 FORD 7566
3 7934 MILLER 7782
已选择14行。
在使用SELECT 语句来报告树结构报表时应当注意,CONNECT BY子句不能作用于出现在WHERE子句中的表连接。如果需要进行连接,可以先用树结构建立一个视图,再将这个视图与其他表连接,以完成所需要的查询。
应用内测很重要
走到内测这一步,已经离正式产品只有一步之遥了。内测非常关键,通过内测可以尽可能的减少bugs、修正错误、调整参数等等。自己的产品其实就是一件艺术品,不光需要娴熟的技艺,同时也需要耐心和细心不断的打磨,就好像不断的打磨一件玉器,使其更圆润透亮。内测是能接收到真实用户反馈的最宝贵的机会,而移动应用的内测对应用开发者来说尤为重要。尤其是iOS应用,这是你的应用能够在App Store里得以被用户发现的珍贵的机会,可以最大幅度的减少产品出问题的风险,以及能够顺利通过各大应用商店的测试。

用户满意度 via brainstuck
内测宝典
1.找到有价值的目标用户
还记得去年愤怒的小鸟团队曾在CSDN移动开发者大会上提到:“开发愤怒的小鸟时候,先是给一些亲朋好友进行体验,获得了极大好评,随后开发者将这款游戏分享给他们的亲朋好友。于是在芬兰,愤怒的小鸟开始火了起来。”PopCap亚太总裁James Gwertzman介绍植物大战僵尸的时候提到了一个有趣的故事:“为了测试这个游戏是否真的达到了“每个人都能玩起来”,他们发动了团队成员的女朋友们。他们发现某些自己觉得很简单的地方,老婆大人们却表示各种搞不懂。”
你可以把内测版本发放到个大论坛上进行推广,来获得第一批小白鼠。但是这些小白鼠提供大量的反馈很可能会让你应接不暇、精疲力尽。况且App Store的beta test法规规定,一个应用最多只允许有100个内测的用户。中国古话有云:“不打没有把握的仗,不简单粗暴的盲目寻找目标用户."当然后一句是我加上去的。这里一定要提前做一些市场调研的工作,尽量将目标锁定在“有价值”的目标用户身上,他们才是能够给你带来所谓“正能量”的使徒们。

目标用户 via Egm Digital Media
2.选择内测用户的主流方式
Founder Space称,要想吸引用户,首先得给用户一个入口,能够让他们简单的了解一下你的应用,提供一些必要的信息。说白了,你的应用首先得有个网页,成为联系你和用户的一扇门。接下来,你要了解用户们都喜欢泡在什么地方,微博?人人?豆瓣?各大论坛?起码你得有至少一个SNS网站的帐号,以期获得和用户沟通的机会。切记不要简单粗暴的发个邀请链接就完事了,中国古人还说过:“攻心为上。”所以,学点社会工程学没坏处。
把自己介绍给“合适的人”,很多人可能首先想到的是某意见领袖,某知名网络红人,某科技博客等等。其实有时候这些人提供的反馈并不能满足你的内测需求,你需要的是“合适的人”,例如某公司创始人,某CSDN的编辑/记者 [mailto] 等,他们的人际网络中很可能很多潜在用户。
3.拉拢用户并维护用户关系
喜新厌旧是动物的天性,也是自然界发展的规律。所以用户不会无缘无故对你的产品进行长期持续的关注,你需要拉拢更多心用户参与进来,同时也要维护好和绝大部分用户的关系。我说绝大部分,是因为用户流失也是自然规律之一。如果你能清晰的定位到“有价值”的目标用户,拉拢用户就不存在太大问题。
及时对用户的反馈做出回应,但是要有技巧的进行回应。同时也要尽可能的诱导用户之间的沟通和讨论,让他们感觉到参与其中的乐趣,了解他们的欲求和想法,及时做出调整,这个时候一定要把握好节奏,节奏是一条很重要的自然规律!

维护好的用户关系 via BlogSpot
4.采取激励手段感恩用户
内测用户为你做出了非常大的贡献,他们将来也会成为你的应用或者游戏的资深用户,对未来的新用户以及用户社区产生影响。你需要提供一些激励手段,使得内测用户觉得参与这个项目不仅仅获得了抢先体验、甚至有时候产品特性“因我改变”的乐趣,更使得用户对你的产品产生持续的好感,忍不住用/玩下去。
5.数据分析
在获取“有价值”的目标用户的时候,我们需要建立一些列的成就等级,用来考核你达成的效果,定义用户满意度以及参与度的参数,通过不断的数据分析,来检验是否已达成成就,用户满意度如何,发现更多的分发渠道以及搜集到用户使用产品背后的一些故事。

应用内测很重要
走到内测这一步,已经离正式产品只有一步之遥了。内测非常关键,通过内测可以尽可能的减少bugs、修正错误、调整参数等等。自己的产品其实就是一件艺术品,不光需要娴熟的技艺,同时也需要耐心和细心不断的打磨,就好像不断的打磨一件玉器,使其更圆润透亮。内测是能接收到真实用户反馈的最宝贵的机会,而移动应用的内测对应用开发者来说尤为重要。尤其是iOS应用,这是你的应用能够在App Store里得以被用户发现的珍贵的机会,可以最大幅度的减少产品出问题的风险,以及能够顺利通过各大应用商店的测试。
用户满意度 via brainstuck
内测宝典
1.找到有价值的目标用户
还记得去年愤怒的小鸟团队曾在CSDN移动开发者大会上提到:“开发愤怒的小鸟时候,先是给一些亲朋好友进行体验,获得了极大好评,随后开发者将这款游戏分享给他们的亲朋好友。于是在芬兰,愤怒的小鸟开始火了起来。”PopCap亚太总裁James Gwertzman介绍植物大战僵尸的时候提到了一个有趣的故事:“为了测试这个游戏是否真的达到了“每个人都能玩起来”,他们发动了团队成员的女朋友们。他们发现某些自己觉得很简单的地方,老婆大人们却表示各种搞不懂。”
你可以把内测版本发放到个大论坛上进行推广,来获得第一批小白鼠。但是这些小白鼠提供大量的反馈很可能会让你应接不暇、精疲力尽。况且App Store的beta test法规规定,一个应用最多只允许有100个内测的用户。中国古话有云:“不打没有把握的仗,不简单粗暴的盲目寻找目标用户."当然后一句是我加上去的。这里一定要提前做一些市场调研的工作,尽量将目标锁定在“有价值”的目标用户身上,他们才是能够给你带来所谓“正能量”的使徒们。
目标用户 via Egm Digital Media
2.选择内测用户的主流方式
Founder Space称,要想吸引用户,首先得给用户一个入口,能够让他们简单的了解一下你的应用,提供一些必要的信息。说白了,你的应用首先得有个网页,成为联系你和用户的一扇门。接下来,你要了解用户们都喜欢泡在什么地方,微博?人人?豆瓣?各大论坛?起码你得有至少一个SNS网站的帐号,以期获得和用户沟通的机会。切记不要简单粗暴的发个邀请链接就完事了,中国古人还说过:“攻心为上。”所以,学点社会工程学没坏处。
把自己介绍给“合适的人”,很多人可能首先想到的是某意见领袖,某知名网络红人,某科技博客等等。其实有时候这些人提供的反馈并不能满足你的内测需求,你需要的是“合适的人”,例如某公司创始人,某CSDN的编辑/记者 [mailto] 等,他们的人际网络中很可能很多潜在用户。
3.拉拢用户并维护用户关系
喜新厌旧是动物的天性,也是自然界发展的规律。所以用户不会无缘无故对你的产品进行长期持续的关注,你需要拉拢更多心用户参与进来,同时也要维护好和绝大部分用户的关系。我说绝大部分,是因为用户流失也是自然规律之一。如果你能清晰的定位到“有价值”的目标用户,拉拢用户就不存在太大问题。
及时对用户的反馈做出回应,但是要有技巧的进行回应。同时也要尽可能的诱导用户之间的沟通和讨论,让他们感觉到参与其中的乐趣,了解他们的欲求和想法,及时做出调整,这个时候一定要把握好节奏,节奏是一条很重要的自然规律!
维护好的用户关系 via BlogSpot
4.采取激励手段感恩用户
内测用户为你做出了非常大的贡献,他们将来也会成为你的应用或者游戏的资深用户,对未来的新用户以及用户社区产生影响。你需要提供一些激励手段,使得内测用户觉得参与这个项目不仅仅获得了抢先体验、甚至有时候产品特性“因我改变”的乐趣,更使得用户对你的产品产生持续的好感,忍不住用/玩下去。
5.数据分析
在获取“有价值”的目标用户的时候,我们需要建立一些列的成就等级,用来考核你达成的效果,定义用户满意度以及参与度的参数,通过不断的数据分析,来检验是否已达成成就,用户满意度如何,发现更多的分发渠道以及搜集到用户使用产品背后的一些故事。
 2012年7月8日
2012年7月8日
有人问起Oracle EBS的销售价格的问题,每个公司的情况不一样,上的模块情况不一样,用户数也不一样,所以价格也就有很大区别。
具体价格可以拨打甲骨文免费销售咨询热线:800-810-0161 或者E-mail:salesinquiry_cn@oracle.com
也查了下,发现Oracle官方提供了一文档“Oracle E-Business Suite Applications Global Price List Software Investment Guide(2012.Jun)”讲Oracle的Price List,这个价格可能是一个参考价格。
比如对于Logistic模块的Inventory


库存管理模块下的MSCA和仓储管理模块是可选的。单说Inventory模块,Lisense Price为4595美元(每5个Application User),Software Update License & Support费用为1010.9美元(每5个Application User)
HR模块

HR模块下面又包含了很多子模块,比如人事,薪资,绩效...价格各不同,但HR模块的定价方式和库存的定价方式又有不同,HR模块是按员工数来定价的,不如人事模块,最小员工数销售单位为100雇员。
Reference:
Contact Oracle: http://www.oracle.com/us/corporate/contact/index.html
Applications Licensing Table:http://www.oracle.com/us/corporate/pricing/application-licensing-table-070571.pdf
Oracle licensing:http://www.orafaq.com/wiki/Oracle_Licensing
注:以上数据不一定准确,仅供参考,有意向购买EBS的话,最好垂询Oracle的销售热线800-810-0161
转载请注明出处:http://blog.csdn.net/pan_tian/article/details/7727515
======EOF======
基本数据库对象:表,视图,索引,触发器,存储过程,用户,图表,规则,默认值。
表:表示数据库中最最基本的对象,我们的数据都存放在表中。
表由行,列构成。列为字段,行为记录。一般我们在设计的表的时候操作的是列,在操作数据的时候用的是行。
一、表结构的操作:
表的基本操作:创建,修改,删除。
要创建一个表,上篇博客中写到,添加数据库对象就像是给大楼里招住户,表中的数据就是每个用户的家庭成员。表就是其中的住户。那么住户要搬进去,就要根据自己的需要给房间进行装修。放到数据库中,就是我们建表之前的设计阶段。
设计阶段要考虑什么呢?
建表不得不说的几个概念:约束,默认值,规则,
约束包括主键,外键,check,唯一性,null 。
主键:指定表的一列或几列在表中具有唯一性。
外键:是定义表之间的约束。例如:A表中的列跟B表中的主键相同时,可以将A表中的这列设置为A 表的外键。
Check:通过检查输入到列中的值来判断是否合理。
唯一性:用来确保不受主键约束的列上的数据的唯一性。
Null:该列是否可以为空值。
规则:对列中的数据和自定义数据类型的值进行的规定和限制。注意这里多了一个自定义和数据类型,约束中没有哦!
默认值:如果输入记录时,某列没有指定值,系统自动插入的值。
标识列:可以为某一列设置为标识列,这样就不必为这列赋值了,系统会自动添加行序号。但是这列数据类型必需是数据类型的哦,字符串之类的就没有这个属性哦!
接下来开始设计表吧!
我们一起来盘算一下:有数据类型,字段长度,字段名,主键,外键,check等约束,规则,标识符等等。这样记很麻烦哦!我们可以类比一下生活,一个用户搬进新家,首先看看房间是几室几厅,好比确定有几列;房间类型:卧室,客房,客厅,厨房,好比各个字段放什么类型数据;然后看各个房间的面积大小,当然就是根据实际需要确定数据的长度了;最后就是摆设了,必须的就是厨房要摆做饭的东西,卧室必须有床吧,这些可以理解成规则,规则是使用数据库的;客厅随你设置哦,还有就是,厨房放什么样的厨具,卧室的其他设置这些各家都不尽相同,这可以理解为约束。约束是针对表的。
可以参照下表:
|
数据库 |
数据类型 |
字段长度 |
字段名称 |
约束,规则 |
|
生活 |
房间类型 |
面积 |
房间名称 |
不同的房间放不同的东西 |
创建表
利用T-SQL 语言 create
use 职工表
create table 领导基本信息(编号 int identity,姓名 varchar(10) primary key,职务 varchar(10) not null,工资 money default 1500
constraint salary check('工资'>1000 and '工资'<2000))
create table 员工基本信息(编号 int primary key,姓名 varchar(10) foreign key references 领导基本信息(姓名) on delete cascade,工资 money default 1500 )
create rule 工资范围 as @salary>1000 and @salary<2000
go
exec sp_bindrule '工资范围','员工基本信息.工资'
该例子中创建了主键列:姓名;标识列:编号;非空限制:职务列;工资列:既有默认值,还设置了check约束。
第二个员工信息表在领导信息表的基础上建立外键。
还为员工信息表创建了规则,规则是独立的数据库对象,创建后需要绑定和松绑。
修改表 alter
修改表包括:增、删、修改字段,重命名。
把领导基本信息中职务列改为可以为空。
alter table 领导基本信息
Alter column 职务 varchar(10) null
增加,删除列:把 alter 换成add 或者drop 即可。
重命名:利用系统存储过程:EXEC sp_rename '员工基本信息', 'employee'
删除表 drop
Drop table 表名
以上这些对表的操作都可以通过企业管理器来实现,比较简单不做详细介绍。
二、表中数据的基本操作为:增,删,改,查。
增加数据: insert
删除:delete
改:update
查:select
Use 职工表
Insert into 表名 value(列的一些定义)
Update 表名 set 旧列值=新列值 where 条件语句
Delete from 表名 where 条件语句
Select 列名,…… from 表名 【where 条件】
三、关系图
多个表之间存在的某种联系,我们可以通过企业管理器创建关系图来表示。
最后附上一张数据库表的里截图,大家参考一下。

2012年7月7日
{
int nCount = myPts.Count;
int nCross = 0;
for (int i = 0; i < nCount; i++)
{
Point p1 = myPts[i];
Point p2 = myPts[(i + 1) %nCount];
// 求解 y=p.y 与 p1p2 的交点
if (p1.Y == p2.Y)
continue;
// 交点在p1p2延长线上
if (Y < Math.Min(p1.Y,p2.Y))
continue;
// 交点在p1p2延长线上
if (Y >= Math.Max(p1.Y,p2.Y))
continue;
// 求交点的 X 坐标--------------------------------------------------------------
double x = (double)(Y - p1.Y) *(double)(p2.X - p1.X) / (double)(p2.Y - p1.Y) + p1.X;
if (x > X)
nCross++; // 只统计单边交点
}
// 单边交点为偶数,点在多边形之外 ---
return (nCross % 2 == 1);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号