


mysql设置了utf8mb4,为什么还有utf8mb4_general_ci和utf8mb4_0900_ai_ci?
前段时间,遇到一个mysql的问题,我仔细看看报错信息,应该是MySQL数据库报出来的,大意是说:collation不兼容,一个是 utf8mb4_0900_ai_ci,另一个是utf8mb4_general_ci。
utf8mb4_general_ci这玩意儿我见过,是针对utf8mb4编码的collation,但是utf8mb4_0900_ai_ci是啥,我也没见过。
于是我问他,这玩意儿从哪里出来的?
他说:“我也不知道,我完全没见过啊。再说,我数据库编码已经是utf8mb4了,怎么还会有这么多名堂?”
看他着急又不知所措的样子,我便花了点时间来研究,还真学到点新知识。而且我也发现,有许多程序员天真的以为“用了UTF8就等于做了国际化了,不用再担心编码问题”。看来,这个话题还真值得多讲讲。
首先从utf8mb4_0900_ai_ci这个诡异的名字说起。
Unicode编码的诞生,是为了解决之前各国的计算机文字编码自成一体的问题。不同国家采用不同的编码,自己用还算正常,但是跨文化交流必然会出问题,更无法解决“在同一篇文档里又要显示中文又要显示韩文还要显示日文”之类的问题。
有了Unicode,地球上所有的文字都有独一无二的编码(Code Point,也就是为它分配的码值,或者说“逻辑代号”),前述问题就解决了。
但是Unicode(有个相关的名字是UCS,Universal Coded Character Set,二者基本等价)只确定了码值,或者说,只分配了逻辑代号。至于这些逻辑代号在实际使用中如何存储,如何传输,那是另一个问题。而UTF-8,就是解决存储和传输等问题的“实际方案”。
实际上,UTF的全名是Unicode Transformation Format,也就是“Unicode变换格式”。这里的“变换”,基本可以类比为:要告诉别人明天早上九点来开会,到底是发邮件呢,还是打电话呢,还是写纸条呢,还是直接去敲门打招呼呢?。
所以,Unicode的变换格式不只UTF-8一种,还有UTF-16、UTF-32等等。UTF-8使用比较普遍,因为它是变长编码,如果只传输ASCII字符,则每个字符只需要一个字节。因此,如果数据中包含大量的ASCII字符,那么UTF-8可以节省很多存储空间。
老一点的程序员大概都知道UTF-8,在MySQL中写作utf8,没有横线。如果要用MySQL存储多种语言的字符,那么把字符集(character set)设定为utf8是合适的选择。注意,MySQL中必须指定utf8,而不是Unicode。因为Unicode只是逻辑规范,utf8才是具体存储和传输的格式。
那么,utf8mb4_0900_ai_ci什么意思呢?
我们分部分来看这个名字,先从开头看起。
utf8mb4,这个名字许多人大概熟悉。如今️✈️♥️emoji表情已经大量使用,但MySQL之前的的字符集(character set)是utf8(更准确的名字是utf8mb3,一个字符最多使用3个字节来存储),只能存储编码值从0x000到0xFFFF之间的字符。
然而,emoji表情字符的码值超过了0xFFFF,按照UTF-8规范,存储时需要用4个字节。正因为如此,MySQL才提供了utf8mb4的字符集。如果把数据库表的字符集设定为utf8mb4,就可以正常存储包含表情字符的文本了。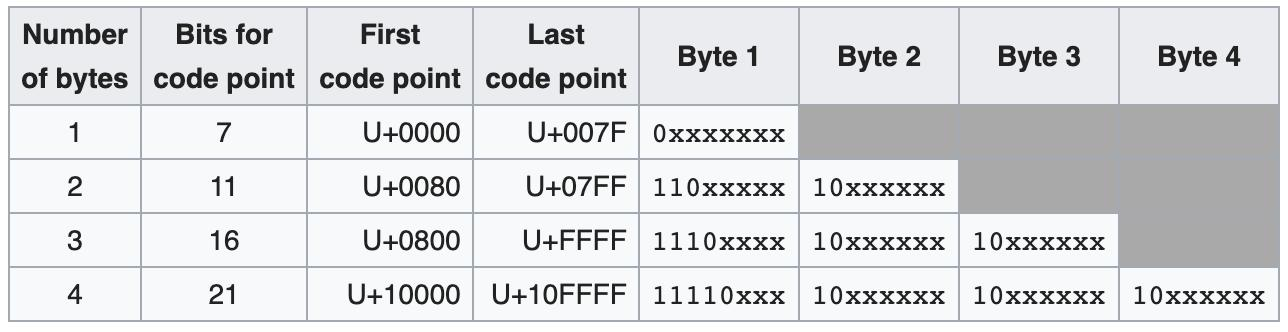
UTF-8编码图解,来源:维基百科
中间的0900,它对应的是Unicode 9.0的规范。要知道,Unicode规范是在不断更新的,每次更新既包括扩充,也包括修正。比如6.0版新加入了222个中日韩统一表义字符(CJK Unified Ideographs),7.0版加入了俄国货币卢布的符号等等。
如果支持新的Unicode规范,就可以直接享受好处,像对待普通字符那样对待这些新字符,当然是好事。
以前的MySQL虽然也会跟随Unicode的更新,但速度太慢了。MySQL 5.7的第一个发行版MySQL 5.7.1是2013年4月23日面世的,它包含的最新的Unicode规范是Unicode 5.2,发布于2009年10月。即便是2020年1月13日发布的MySQL 5.7.29,仍然是这样。
然而Unicode规范早已升级了很多版,即便是9.0版本,也发布于2016年6月,过去了好多年了。到目前为止,最新的版本已经到了12.1,发布于2019年5月。所以从5.2更新到9.0,看起来是一大进步,其实也只是补课而已。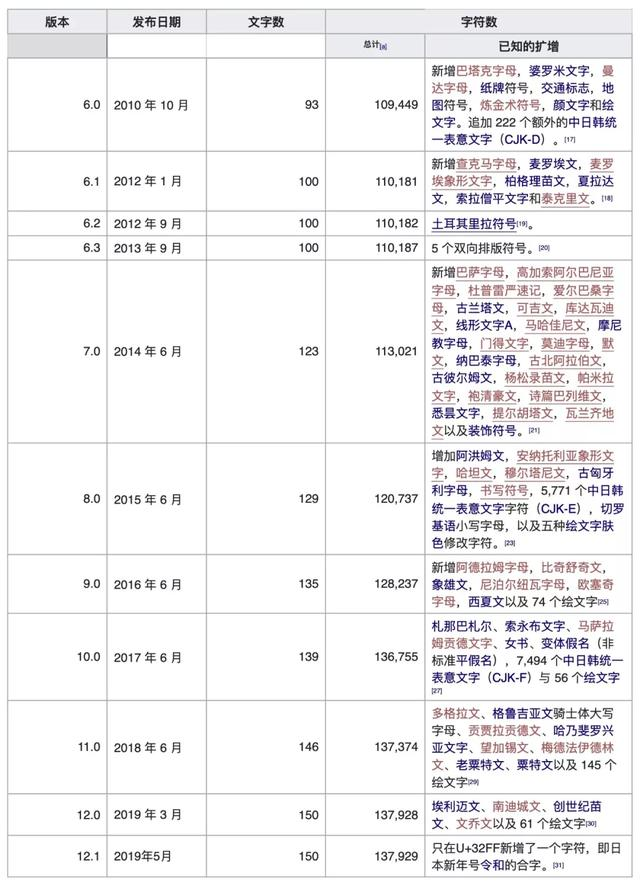
Unicode在不断更新,来源:维基百科
最后两部分_ai_ci,ai表示accent insensitivity,也就是“不区分音调”,而ci表示case insensitivity,也就是“不区分大小写”。
所以,utf8mb4_0900_ai_ci到底是个什么东西呢?其实,它是个collation。
说起“字符集”,许多人想当然认为,给每个字符分配了一个编码,并且能存储、能传输,这就够了。其实这当然不够,我们不但需要给每个字符分配编码,让它们能存储、能传输,还需要定义一套关系来组织它们,找到它们之间的联系。这套关系的定义,就是collation。
collation定义了哪个字符和哪个字符是“等价”的。所以如果指定“不区分大小写”,那么a和A,e和E就是等价的,这样查找时就会方便很多。但这还不够,世界上的文字很多,所以才会有“不区分音调”的要求,这时候e、ē、é、ě、è就是等价的,那么假设我们要进行拼音查找,只要按e去找就可以全部列出来,很方便。甚至,它们也和ê、ë也是等价的,这样就更方便了。
collation也定义了字符的排序规则,如果按照“字符顺序(而不是简单的‘字母顺序’)”来排序,哪个字符应当排在哪个字符前面。所以,尽管“啊”、“副”、“德”三个字的拼音开头分别为A、F、D,但直接选定collation为utf8mb4,它们并不会按照“啊”、“德”、“副”的顺序排序,而是会排成“副”、“啊”、“德”。如果你希望把中文字符按照拼音来排序,指定使用gb18030_chinese_ci作为collation就可以了。
当然,要补充的是,collation依赖于字符集(character set),所以把gb18030_chinese_ci作为collation,就要求字符集是gb18030,而不能是utf8mb4。
这也很好理解,字符集定义了可以使用的字符,对应的collation定义了字符之间的关系。如果collation不依赖于字符集,那么很可能出现“有些字符没有关系定义,不知如何判断等价和顺序”的问题。
到这里,我的疑惑就解开了。MySQL 8.0之后,默认collation不再像之前版本一样是是utf8mb4_general_ci(这个名字也确实取得有问题,话说得太满,有点自负了),而是统一更新成了utf8mb4_0900_ai_ci。
不幸的是,我之前建的各种数据表,它们的collation仍然是utf8mb4_general_ci,而新建的表是utf8mb4_0900_ai_ci。如果恰好遇到包含字符串相等或者大小比较的联表查询语句,而关联的表又使用了不同的collation,MySQL就无法决策到底应当使用哪个,就会报错。
既然如此,解决办法也很简单,用alter table table_name collate utf8mb4_0900_ai_ci显式统一所有表的collation,问题就解决了。
我们可以多想想,把character set和collation分开,到底有什么好处?其实好处很多。如果把字符看作个人,character set就相当于验明正身,给每个字符发张身份证,而collation相当于告诉大家,排队的时候谁在前谁在后。collation有多套,就相当于可以灵活按身高、体重、年龄、出身地等等因素来排序,却完全不会受到身份证号的干扰。
实际上collation也是如此,既然有utf8mb4_0900_ai_ci,就还有utf8mb4_0900_as_ci和utf8mb4_0900_as_cs。看名字也可以知道,utf8mb4_0900_as_ci表示“区分音调”,所以e、ē、é、ě、è就不再是等价的;而utf8mb4_0900_as_cs表示“区分大小写”,所以查e的时候就不会把E查出来。
这个问题本来不麻烦,为什么会难住人呢?原因不复杂,你去看关于MySQL和Unicode的中文资料,绝大部分都是告诉你,utf8或者utf8mb4就可以解决问题了。因此,不少程序员完全意识不到还有collation这种东西。
所以,这些程序员理解的“字符集”就只有一堆孤零零的字符,根本没想到还需要定义字符之间的等价和排序关系。而这恰恰是最可惜的,因为他们完全错过了“举一反三”的启发,许多类似问题也就缺乏解决思路。要知道,哪怕你做的不是国际化的业务,也可以从collation中受益的。
我们都知道,电商系统的订单处理是一个流程,其中涉及许多状态,比如“已下单,未支付”、“已支付”、“已确认”、“已拣货”、“已发货”等等。
有程序员看到这个需求,想当然就按照先后顺序,用1、2、3、4、5来表示对应状态,确实简单不会出错,也方便先后对比,比如要查找所有“已确认”之前的订单,就查查“已确认”的状态码是4,那么找状态码<4的订单就可以。
然后,有一天,忽然要在两个状态之间加入某个中间状态,比如“已确认”之后需要新的风险评估,通过了才可以去拣货,怎么办?总不可能在3和4之间加一个3.5吧?因为这个数据字段本来就是整数型啊。
所以“有经验”一点的程序员会改改,一开始就不按照1、2、3、4、5这样来分配状态码,而是按100、200、300、400、500,留足空隙,这样就避免了3.5的尴尬,直接给“风控系统已通过”分配350就可以了。
但这仍然不够。如果业务忽然要求既有顺序要变,比如之前“已确认”在前,“风控系统已通过”在后,现在要求“风控系统已通过”在前,“已确认”在后,该怎么办?350总不可能大于400呀。
如果你了解了collation就会发现,这是同样的问题。数据的标识和数据的有序性应当隔离开来,标识是一套规范,有序性是另一套规范,两者可以随意组合。你看,Unicode字符的排序可以按照字符的编码值来,也可以按照其它规范来——加载不同collation就是了嘛。
所以,“已下单,未支付”的代码就可以是OUPD,“已支付“的代码就可以是PDED,“已确认”的代码就可以是CFMD…… 它们只用来做唯一标识,没有任何其它意义。然后在外面定义一套顺序规则,比如OUPD < PDED < CFMD,然后提供一个查询接口,做任何比较的时候都查询这个接口就好——实际上许多语言可以自定义compare函数来做排序,道理就在这里。万一将来要改业务流程,比如加入新状态,或者更改状态的先后顺序,也只需要做一点点更改,规则查询接口保持不变,其它地方更是保持原封不动。
最后我想补充的是,即便你有非常多的软件开发经验,但如果要做“国际化”的业务,仍然会面对许多想不到的问题——e、ē、é、ě、è、ê、ë的等价问题就是一例。这类问题,不亲自经历是很难想象的。
回想起来,十多年前我开始接触这方面业务,还真的积累了一些经验,是坐在办公室里写代码想不到,也非常有意思的问题。

