Elasticsearch
因工作原因接触到es,正好没怎么了解过,来玩一下
如果你的目标是珠穆朗玛,华山自然就不在话下
阅读前提醒
这篇文章里面主要记录了本人对elasticsearch这个app的理解,并没有涉及实际查询和配置操作,不具有实用性,如果你来这里是为了查询到一些能够很好使用elasticsearch的教程,或者一些对elasticsearch进行配置的信息,请前往elasticsearch官网获取帮助。
正文
elasticsearch(以下简称es)官方定义是一个搜索和分析引擎,那么搜索引擎的定义是什么?以下是度娘的答案:
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上采集信息,在对信息进行组织和处理后,为用户提供检索服务,将检索的相关信息展示给用户的系统。它是根据用户需求与一定算法,运用特定策略从互联网检索出制定信息反馈给用户的一门检索技术。
那么可以理解为,es是一个根据一定算法和优化技术,对数据进行分析和检索的软件。当然这个理解可以说是过于广泛,接下来就进一步细化一下。
-
主要概念
其实概念还挺多的,所以我根据官方文档顺序一个个解释,大部分是官方文档的原话,按照自身理解增删一些内容,为避免歧义,有些地方我会附上英文原话
es存储格式:文档(documents)
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位,它不会将信息储存为列数据行,而是储存已序列化为 JSON 文档的复杂数据结构。当你在一个集群中有多个节点时,储存的文档分布在整个集群里面,并且立刻可以从任意节点去访问。关于文档:es文档的元数据

元数据,用于标注文档的相关信息 _index-文档所属的索引名 _type-文档所属的类型名 _id-文档唯一 ld _source:文档的原始Json 数据 _all:整合所有字段内容到该字段,已被废除 _version:文档的版本信息 _score:相关性打分es对文档的优化:索引(index)
An index can be thought of as an optimized collection of documents and each document is a collection of fields 可以把索引理解为对文档优化后的集合,而文档是对字段的集合,Elasticsearch对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。比如文本字段存储在倒排索引中,数字字段和地理字段存储在BKD树中。使用按字段数据结构组合并返回搜索结果的方式使Elasticsearch如此之快。 es中的索引是一个或多个物理分片的逻辑分组,每个物理分片是一个独立索引(an Elasticsearch index is really just a logical grouping of one or more physicashards, where each shard is actually a self-contained index. )es的扩展和弹性:集群(cluster),节点(node),分片(shards)
这三个概念关联性比较大,所以我也仿照官方文档,放在一块来解释了 首先要了解一个基础知识:es是分布式的,并且天生就是分布式的,在设计时就加入了分布式的元素 节点:每个节点就是你起的一个es服务 分片:每个分片是一个Lucene实例**,一个分片(shard)是一个最小级别的“工作单元(worker unit)”; 将文档分布在分片的索引中,再将分片分布在多个节点中,实现冗余和负载均衡。(By distributing the documents in an index across multiple shards, and distributing those shards across multiple nodes)【这里如果不太明白没关系,下文会结合Lucene进行解释】 集群:一个集群可包含一个或多个节点,配置es时指定cluster.name相同的所有启动了的es服务属于一个集群(这个其实没啥好说的,就是普通集群的概念) 节点,分片,索引之间关系: 一个node对应一个es instance 一个node可以有多个index 一个index可以有多个shard 一个shard是一个lucene index **注:Lucene是apache开源的全文检索引擎工具包,es是对Lucene的进一步封装和优化得来的,下面我也会简单展开一些lucene,不过不会太深入。 -
es的功能模块
这里的功能模块旨在解释和说明es进行的优化操作,而不会太详细的去介绍其中的内容,如果有意愿去深入了解,请参考官方文档https://www.elastic.co/guide/en/elasticsearch/reference/
-
索引模块
作用:控制与索引相关的所有方面
因为es的索引是基于lucene做的,所以接下来要先简单普及下lucene的内部原理
lucene
lucene是 Doug Cutting用java开发的一套用于全文检索和搜寻的开源程序库,是es搜索引擎的底层调用,通常用于java环境中的全文索引和搜索。
首先先说一下全文检索是什么 我们生活中的数据总体分为两种:结构化数据 和非结构化数据。 结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等。 非结构化数据: 指不定长或无固定格式的数据,如邮件,word文档等。 当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。非结构化数据又一种叫法叫全文数据。 按照数据的分类,搜索也分为两种: 对结构化数据的搜索 :如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。 对非结构化数据的搜索 :如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。 对非结构化数据也即对全文数据的搜索主要有两种方法: 一种是顺序扫描法 (SeriaScanning): 所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。 有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗? 这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。 这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引 。 这种说法比较抽象,举几个例子就很容易明白,比如字典,字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。 这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search) 。 其实就是把非结构化数据建立索引,再对它进行类似结构化搜索的过程 全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。其实此时索引的创建就是类似k,v形式的存储词典及其对应文档链表
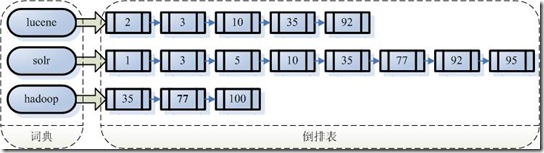
而查找的过程就是根据词典中的词去取出倒排表中的链表而已
-
取出包含字符串“lucene”的文档链表。
-
取出包含字符串“solr”的文档链表。
-
通过合并链表,找出既包含“lucene”又包含“solr”的文件。

当然其中涉及的还有很多比如如何去分词形成一个词典,如何形成倒排链表,查找的相关性如何计算,这些太过详细就不在叙述了,这里推荐一下这个blog可以看下 blog.csdn.net/fatshaw/article/details/51959020,这大佬也是转的,转的谁的就不太清楚了。
es基于lucene,相应的继承了lucene的优点,使用倒排索引快速的进行全文搜索。
那么现在我们开始填介绍概念时候留的坑,通过上面的过程我们了解到lucene创建索引和全文检索的一个大概流程,那么es的index,和lucene的index有什么区别呢?
就如概念中阐述的,es的索引(index)是一个逻辑空间(es中的索引是一个或多个物理分片的逻辑分组,每个物理分片是一个独立索引),其实这是对lucene的index的进一步优化;上面也说过,一个分片(shard)是一个lucene实例,其实就意味着一个分片就是单独的一组lucene的索引,里面包含了文档(document),而一个es的索引有一个或多个分片 (默认是 5 个),es的索引还包含了"type"字段(就像数据库中的表),用来逻辑划分和隔离索引中的数据。
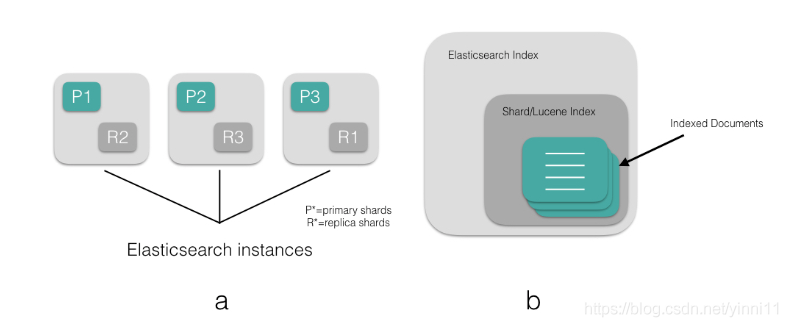
盗个图,实在不想画了,不过这个图还是有点表达不完善,每个es里面只画了一个shard,大致是这个逻辑,这个图中还引入了副本(replica)的概念,其实这没啥好说的,就类似数据库的主从。
倒排索引具有不变性的特性,被写入磁盘后是 不可改变 的:它永远不会被修改。 不变性有重要的价值:
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
- 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量。
当然,一个不变的索引也有不好的地方。主要事实是它是不可变的! 你不能修改它。如果你需要让一个新的文档 可被搜索,你需要重建整个索引。这要么对一个索引所能包含的数据量造成了很大的限制,要么对索引可被更新的频率造成了很大的限制。
如何解决不变性带来的缺点——动态更新索引
当有了不变性的特性,那么想要对数据进行CUD操作就会变得困难,es对此的解决方案是——新建更多的索引;通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮询——从最早开始直到查询完,之后再对结果进行合并。
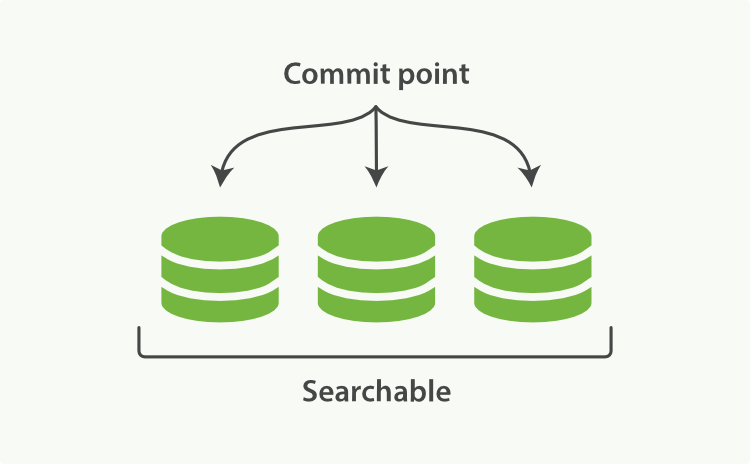
上图表示的是一个lucene节点,其中有三个段(segment),还有一个提交点(commit point)
每个段自身都是一个倒排索引,要注意的是这里的索引并不是lucene的索引,lucene的索引是所有段的集合,外加提交点组成。
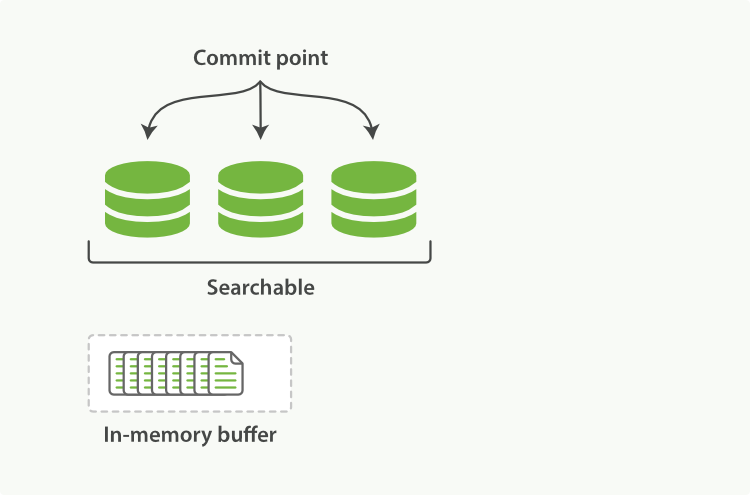
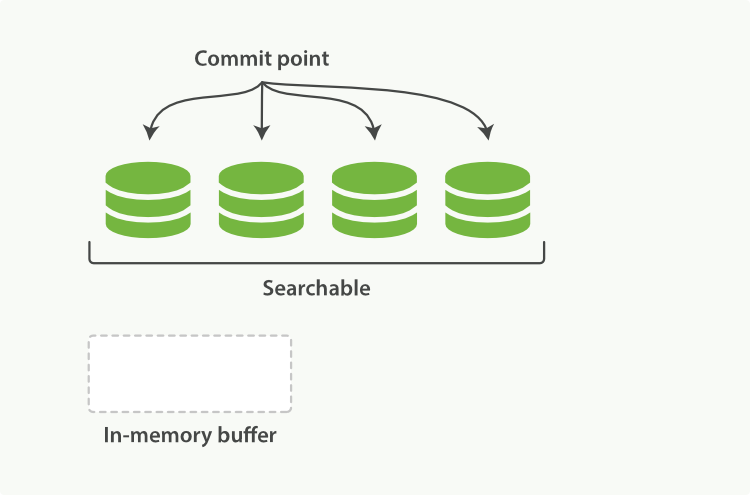
上两图展示了新增索引流程,
- 新文档被收集到内存索引缓存(memory buffer)
- 不时地, 缓存被 提交 :
- 一个新的段(一个追加的倒排索引)被写入磁盘。
- 一个新的包含新段名字的 提交点 被写入磁盘。(注意,实际更新的是提交点)
- 磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件。
- 新的段被开启,让它包含的文档可见以被搜索。
- 内存缓存被清空,等待接收新的文档。
那么对于删除和更新操作又是怎样的?
解决方案是在commit point里面附加了一个
.del文件,文档的删除和更新其实都是逻辑层面,.del文件作用在返回查询结果的阶段,将需要更新 or 移除的文档在返回前从结果中移除上面的流程叙述中有没有什么技术性问题?
其实不知道大家注意到没有,按照上述新增索引流程的第三条(新的段被开启,让它包含的文档可见以被搜索)需要在写入物理文件之后,那么就有一个疑问,也就是意味着直到段被加载到硬盘,之间的阶段其实是不允许被搜索到的,而段加载到内存建立索引,再到硬盘存储,这是个磁盘IO操作,可能效率会很慢。那么就会导致无法实时搜索的问题。
lucene对此做的优化是在(磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件)这一步之前进行(新的段被开启,让它包含的文档可见以被搜索)这个操作,当新的段加入lucene-index文件缓冲区时且还没有写入磁盘就默认已经可搜索,这样就大大缩短了搜索的延迟时间。
想想,是否还有问题?
上面说,新文档的添加每次都会被创建一个段索引,而且这个过程是自动的(默认是1s添加一回),那么就会造成lucene索引里面有大量的段,这里面每个段都会占用一些资源,并且搜索请求也会轮询这些段获取结果,这会造成资源的大量占用和查询效率低下。
所以lucene引入了段合并的概念,
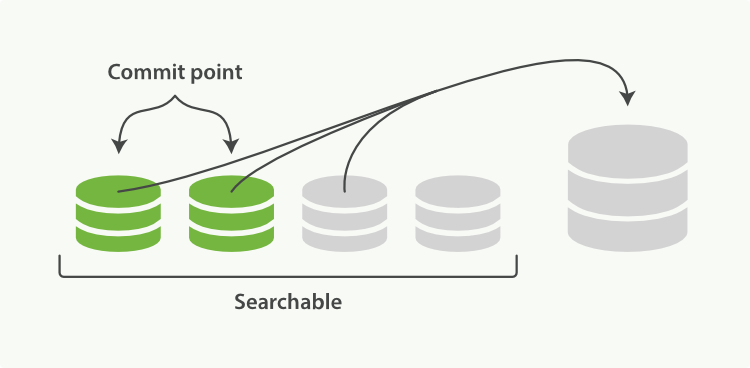
-
当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
-
合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
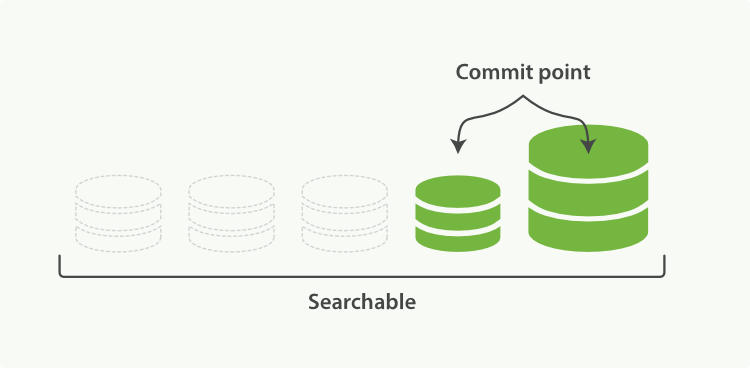
- 新的段被刷新(flush)到了磁盘。 ** 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
当然,合并也是一个IO操作,需要耗费大量系统资源,所以es对其进行了资源限制,留出足够的搜索资源。
-
-
分析与分析器
作用:
分析 包含两个过程:
-
首先,将一块文本分成适合于倒排索引的独立的 词条 ,
-
之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
从上面索引的介绍我们知道,建立索引的时候需要进行分词,依据分词结果形成词典并作为索引创建索引表,es封装了相应的分析工具:
字符过滤器 字符串按顺序通过字符过滤器 。在分词前整理字符串。字符过滤器可以用来去掉HTML,或者将 & 转化成and。 分词器 其次,字符串被分词器分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。 Token 过滤器 最后,词条按顺序通过每个token过滤器 。这个过程可能会改变词条(例如,小写化 Quick 为quick),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)。分析的过程不仅仅是针对索引创建过程,且也针对索引查找过程,两个过程进行之前进行一系列的分析和更改,从而完成对数据可搜索性的增强。
es提供了分析器的自定义模块,可以按需进行词条的预处理,具体方法就不说了,都查得到。
es内置分词器有以下几类:
Elasticsearch 的内置分词器 Standard Analyzer 一默认分词器,按词切分,小写处理 Simple Analyzer —按照非字母切分(符号被过滤),小写处理 Stop Analyzer-小写处理,停用词过滤(the, a, is) Whitespace Analyzer 按照空格切分,不转小写 Keyword Analyzer — 不分词,直接将输入当作输出 Patter Analyzer — 正则表达式,默认 \W+(非字符分隔) Language-提供了30多种常见语言的分词器 Customer Analyzer 自定义分词器 -
-
映射(mapping)
作用:文档的形式多种多样,不一定全是字符串形式的,映射的作用就是把文档的类型和es的类型进行关联和对应。Ø Mapping 定义文档字段的名称/类型/ 倒排索引的相关配置
Elasticsearch 支持如下简单域类型: 字符串: string 整数 : byte, short, integer, long 浮点数: float, double 布尔型: boolean 日期: date 当你索引一个包含新域的文档(之前未曾出现)-- Elasticsearch会使用动态映射,通过JSON中基本数据类型,尝试猜测域类型es也提供了映射模块的自定义功能,这里不再展开。
-
内部对象的索引
作用:有些时候我们提供的是具有嵌套结构的JSON数据集,lucene不能够理解内部对象,es在此之上做了扁平化处理,将内部对象提取出来。
例如
{ "gb": { "tweet": { "properties": { "tweet": { "type": "string" }, "user": { "type": "object", "properties": { "id": { "type": "string" }, "gender": { "type": "string" }, "age": { "type": "long" }, "name": { "type": "object", "properties": { "full": { "type": "string" }, "first": { "type": "string" }, "last": { "type": "string" } } } } } } } } }转化为了如下⬇
{ "tweet": [elasticsearch, flexible, very], "user.id": [@johnsmith], "user.gender": [male], "user.age": [26], "user.name.full": [john, smith], "user.name.first": [john], "user.name.last": [smith] }再例如如果内部嵌套是一个数组
{ "followers": [ { "age": 35, "name": "Mary White"}, { "age": 26, "name": "Alex Jones"}, { "age": 19, "name": "Lisa Smith"} ] }转化为⬇
{ "followers.age": [19, 26, 35], "followers.name": [alex, jones, lisa, smith, mary, white] }
-
-
文档的CRUD
Type名,约定都用_doc
Create-如果ID已经存在,会失败
Index-如果ID不存在,创建新的 文档。否则,先删除现有的文档,
再创建新的文档,版本会增加
Update-文档必须已经存在,更新只会对相应字段做增量修改
Delete-删除文档

*Create一个文档*

支持自动生成文档Id和指定文档Id两种方式
通过调用“post /users/ _doc”
Ø 系统会自动生成document ld
使用HTTP PUT user/_create/1创建时URI中显示指定_create,此时如果该id的文档已经存在,操作失败
*Get一个文档*
找到文档,返回HTTP 200
Ø 文档元信息
² _index / _type
² 版本信息,同一个Id的文档,即使被删除, Version 号也会不断增加
² _source 中默认包含了文档的所有原始信息
找不到文档,返回 HTTP 404

*Index文档*
Index 和 Create不一样的地方:如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引。版本信息+1
*Update文档*
Update方法不会删除原来的文档,而是实现真正的数据更新
*BULK API*
支持在一次AP|调用中,对不同的索引进行操作
支持四种类型操作
Ø Index
Ø Create
Ø Update
Ø Delete
可以再UR中指定Index,也可以在请求的Payload中进行
操作中单条操作失败,并不会影响其他操作
返回结果包括了每一条操作执行的结果

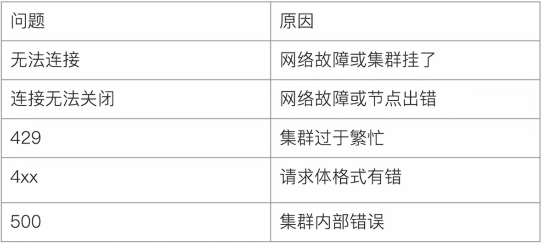
*常见错误返回*
*正排索引和倒排索引*
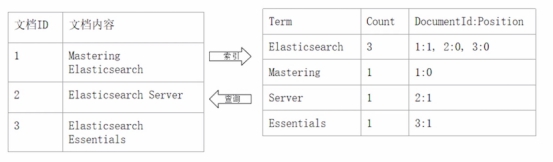
*倒排索引的核心组成*
倒排索引包含两个部分:
单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
Ø 单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足高性能的插入与查询
倒排列表(Posting List)-记录了单词对应的文档结合,由倒排索引项组成
Ø 倒排索引项 (Posting)
² 文档ID
² 词频TF-该单词在文档中出现的次数,用于相关性评分
² 位置(Position)-单词在文档中分词的位置。用于语句搜索 (phrase queny
² 偏移(Offset)-记录单词的开始结束位登,实现高亮显示
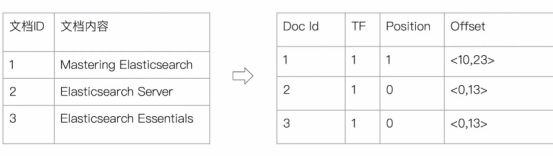
*Elasticsearch 的倒排索引*
Elasticsearch 的 JSON文档中的每个字段,都有自己的倒排索引
可以指定对某些字段不做索引
Ø 优点:节省存储空间
Ø 缺点:字段无法被搜索
免责声明
这篇文章里面有本人的理解,但是主要概念的阐述和功能点优化参考了多篇博客,以及官方文档,并不是全部原创内容,如有雷同,那一定是我抄过来的 😛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号