正则表达式之基础(四)
匹配组
正则表达式中用一对圆括号()表示一个匹配组,括号中的匹配内容则被看做是一个整体。
(regex)
表示匹配regex并获取到一个自动命名的组,自动命名的组是从下标1开始的,依次是1,2,3,4,5。。。
例
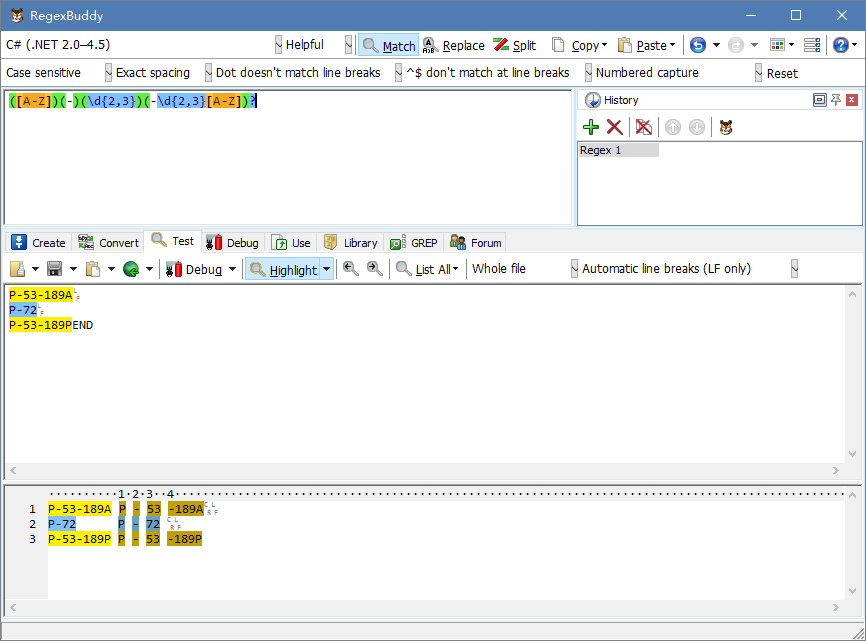
([A-Z])(-)(\d{2,3})(-\d{2,3}[A-Z])?
其中就有四个匹配组,并且自动命名为1,2,3,4
(?<name>regex)
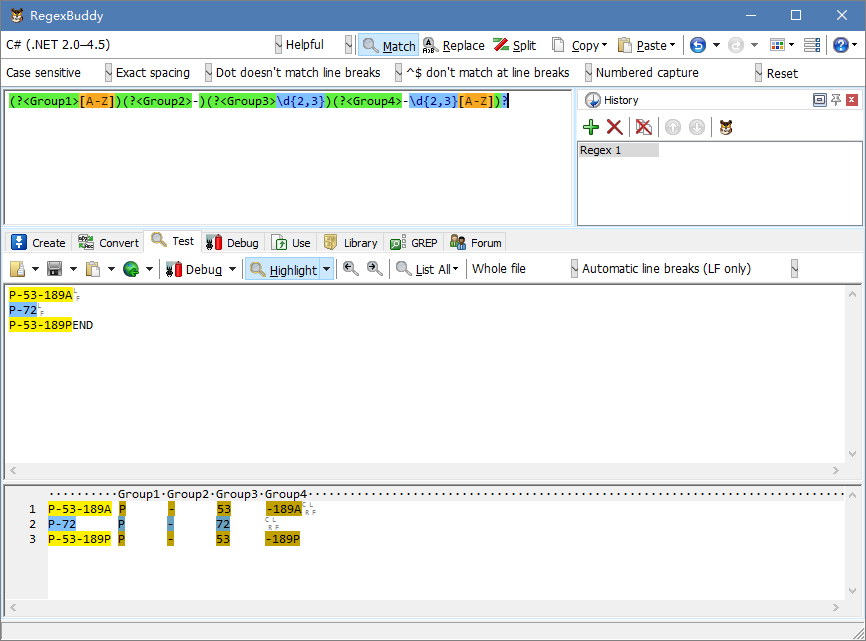
当然我们也可以用这种方式来为一个匹配组命名
(?<Group1>[A-Z])(?<Group2>-)(?<Group3>\d{2,3})(?<Group4>-\d{2,3}[A-Z])?
非获取匹配组
以上两种匹配组都是获取匹配,匹配到后会将结果保存已被后续的使用。典型的用法就是后项引用:
<(h\d)>.*?</\1>

关于非获取匹配我在上一篇 正则表达式之基础(三) 中已经介绍过,这里简单再总结一下,基本可以理解为,(?<=regex)以什么开头,(?<!regex)不以什么开头,(?=regex)以什么结尾,(?!regex)不以什么结尾
虽然这些都会包含一对圆括号,但匹配结果并不会被保存以备后用

替换
有了上面匹配组的一些简单知识,我们就可以运用它来做一些简单的替换操作了。
例
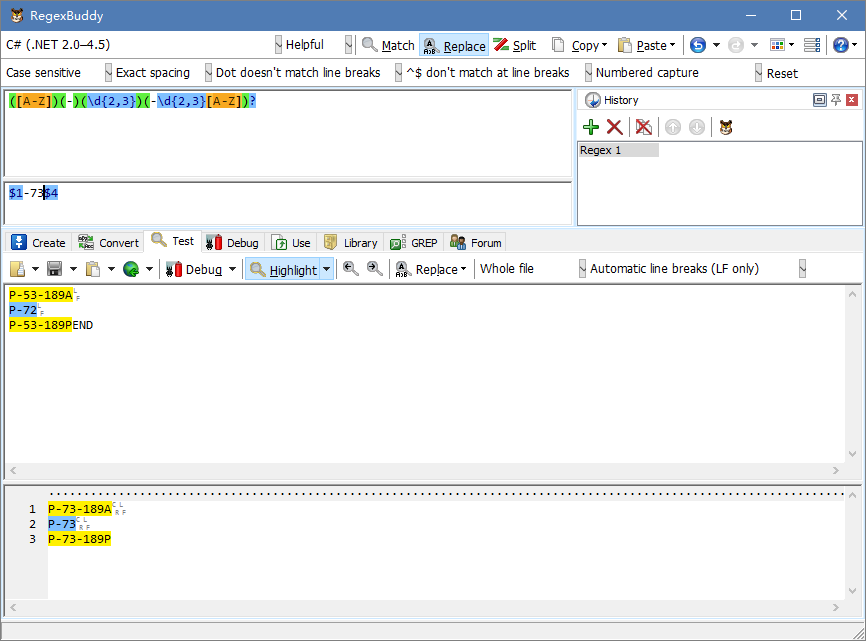
P-53-189A
-》
P-73-189A
([A-Z])(-)(\d{2,3})(-\d{2,3}[A-Z])?
$1-73$4
或
(?<Group1>[A-Z])(?<Group2>-)(?<Group3>\d{2,3})(?<Group4>-\d{2,3}[A-Z])?
${Group1}-73${Group4}
替换元素
| 替换 | 说明 |
| $number | 包括替换字符串中的由 number 标识的捕获组所匹配的最后一个子字符串,其中 number 是一个十进制值 |
| ${name} | 包括替换字符串中由 (?<name> ) 指定的命名组所匹配的最后一个子字符串 |
| $$ | 包括替换字符串中的单个“$”文本 |
| $& | 包括替换字符串中整个匹配项的副本 |
| $` | 包括替换字符串中的匹配项前的输入字符串的所有文本 |
| $’ | 包括替换字符串中的匹配项后的输入字符串的所有文本 |
| $+ | 包括在替换字符串中捕获的最后一个组 |
| $_ | 包括替换字符串中的整个输入字符串 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号