字节码文件解剖
#### 前提提要:
.java文件通过java -c 生成.class文件,这部分并非是JVM需要处理的部分,JVM处理的部分是基于生成的class文件,生成的部分是由编译器来负责
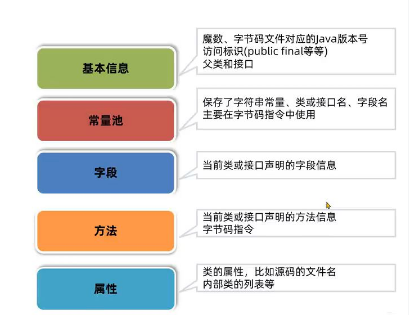
一个字节码文件的主要组成部分
使用工具说明
idea的JclassLib插件
使用步骤:
- 运行代码(只要你更新了代码就需要,或者build)

基础信息介绍
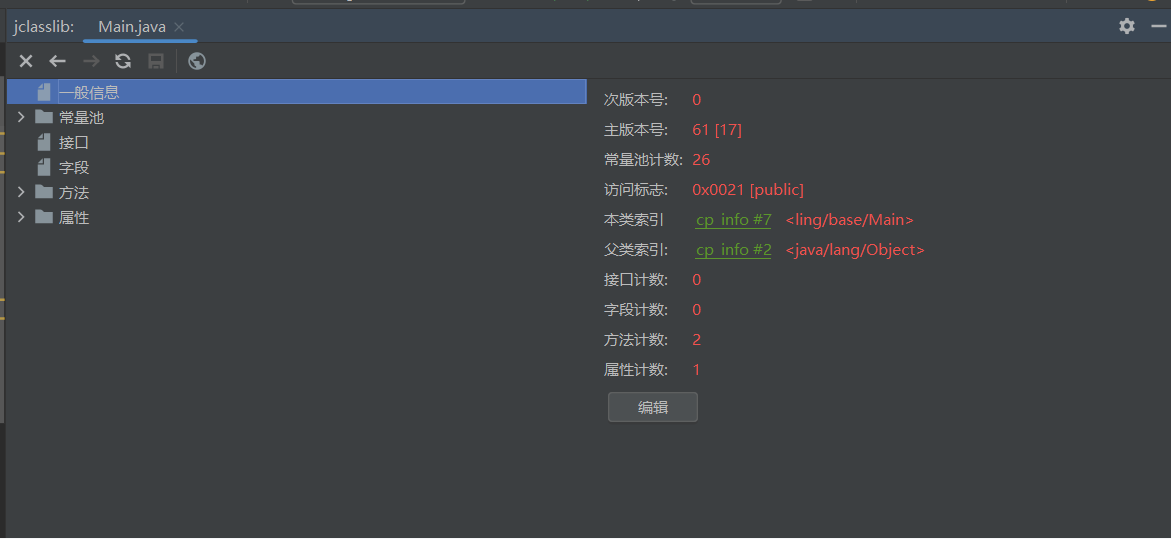
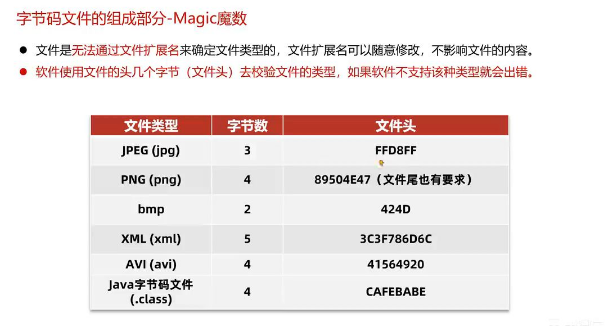
魔数
魔数并非在这里展示,魔数其实有点类似一个文件的格式中的一部分,所有的软件开发中关于打开文件都会这么设计,用于识别说我们能否成功打开
java中是开头是cafebabe
其他文件如下:
主版本号
1.2后大版本对应的公式是主版本号-44

关于版本号可能遇到的problem及解法
- 版本不匹配
- 提高java版本
- 降低依赖版本

在这之中可能还会遇到的问题:jdk版本存在bug,虽然很多人都说什么永远jdk8,但是实际使用上jdk8在性能上以及开发上可能会比jdk17多不少工作量,例如我之前尝试转为http2,而在jdk8需要引入其他依赖,而jdk9则可以直接转
常量池介绍以及属性介绍
此常量池非JVM中的字符串常量池,仅仅是当前class文件中为了降低一定的空间占用和加快JVM解析class文件而使用的常量池而已
下列讨论也仅局限于字节码文件中的常量池,不会涉及JVM部分
在此先给常量池定论:为了节省空间而使用的池化技术
首先从字段入手:
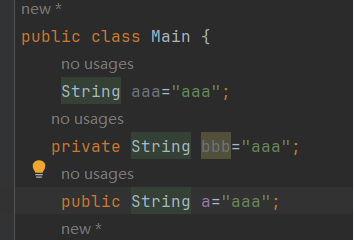
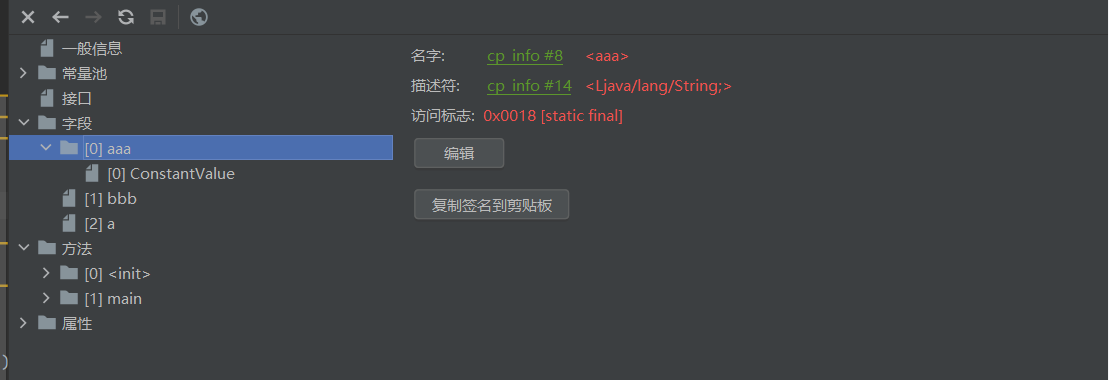
Problem1:为什么aaa变量可以打开?而其他的不行?
解答:是因为他使用的是static和final同时修饰
所有以cp开头的都最终指向了常量池中的一个记录,例如aaa这个变量名,以及对应的aaa的类型string,具体内容如下:
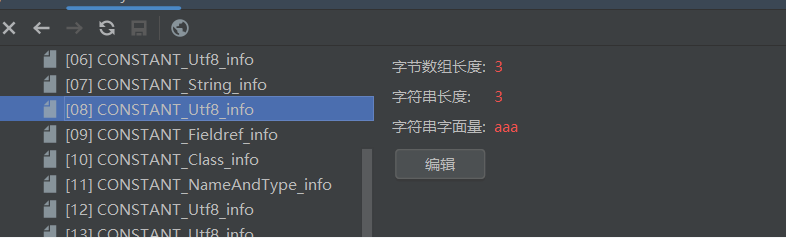
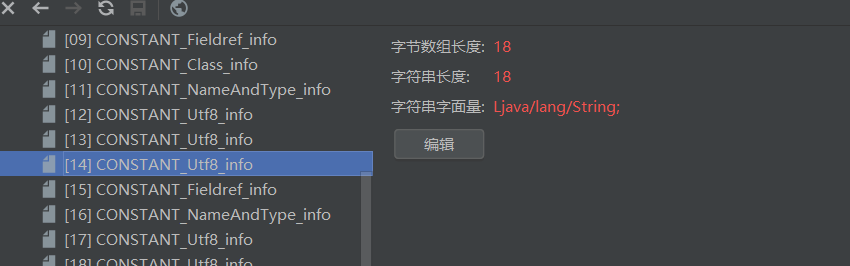
我们再看看ConstantValue的信息:
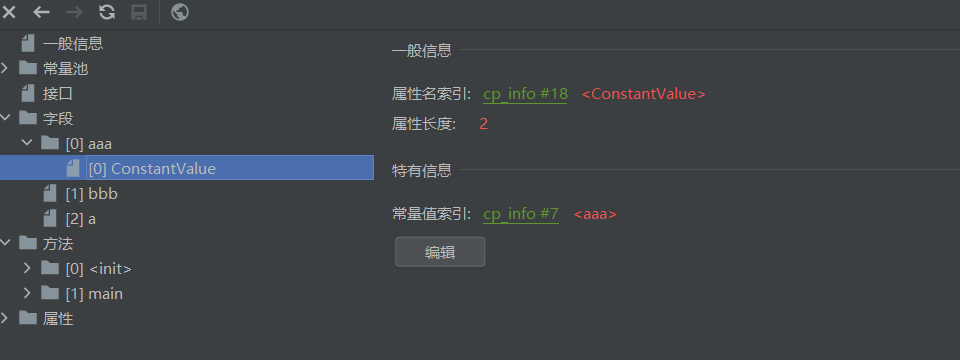
problem2:这个属性名索引为何存在且为什么要是constantValue?
首先回答一下为什么要有constantvalue,这是由于我们使用final修饰了,所以最终的效果就是有了一个指向constantValue的引用,也就是我们java,字节码层面实现我们final修饰不可改变的效果,如下图所示,而这个属性值为什么存在也不言而喻了
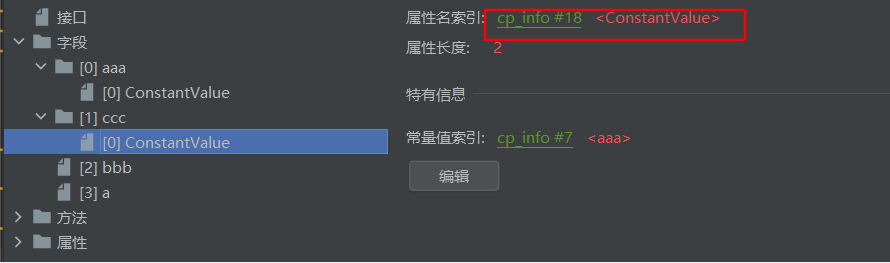
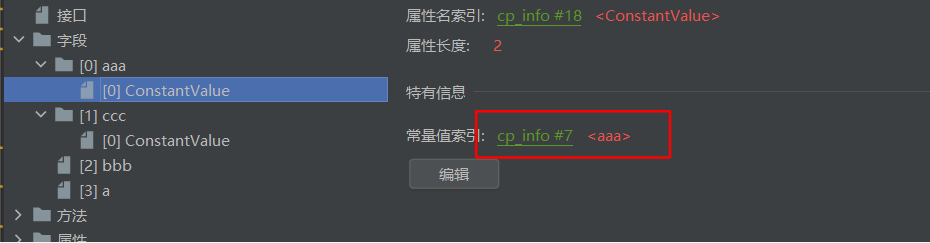
最后回到正题:我们可以发现当String aaa和Stirng ccc都="aaa"时,他的常量值索引都指向7
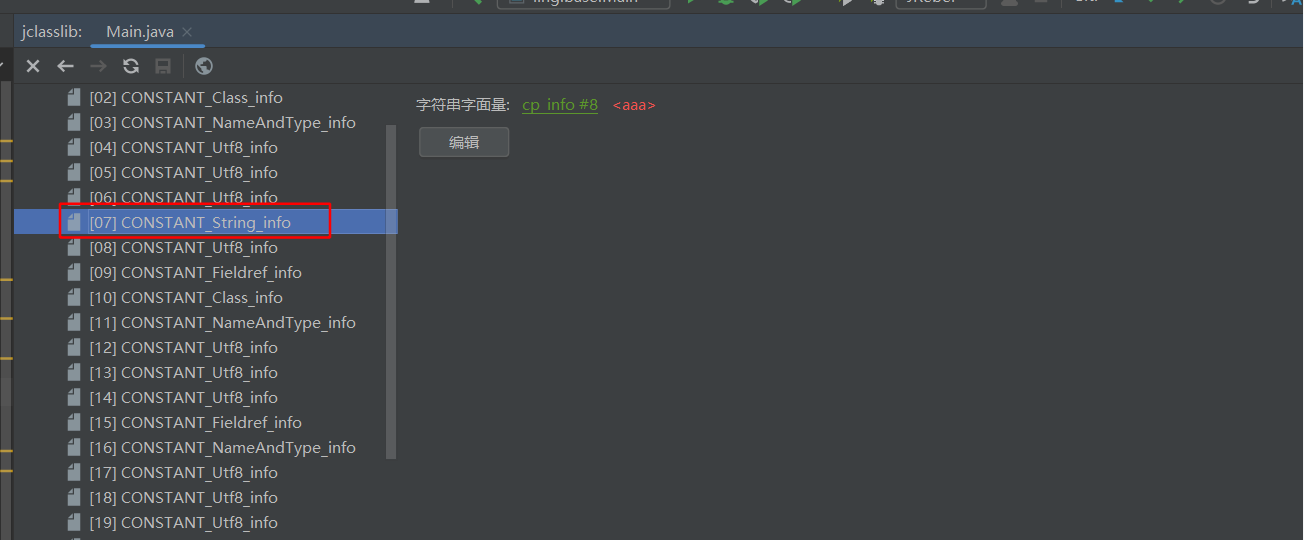
那么7的内容是什么?7的类型是string_info,而之中又指向了8?
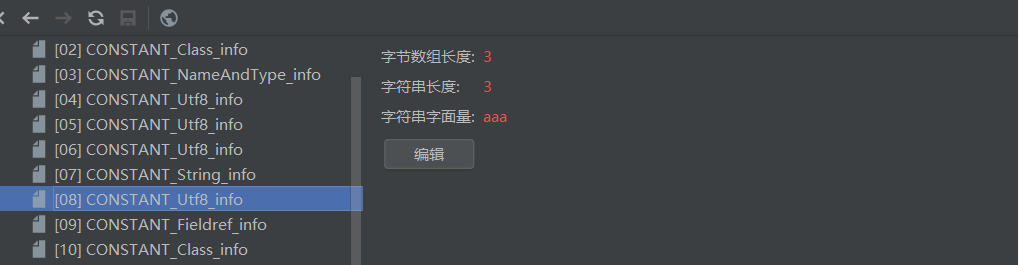
8才是真正的aaa
那么问题来了?
为什么要这么设计?
关于字段中的constant_value为什么要指向string?然后string再指向其中的一个具体的utf8_info呢?
因为最终jvm会有一个string常量池,我们要保存string和utf8_info中保存的值的关系,好方便之后我们将其存储到常量池中
追问:那为什么不直接保存在对应的string中,也即我们string不存符号引用而是直接存对应的常量?
这样的话如果有其他变量也纸箱这里应该也没问题吧?
没错,但是例如string abc="abc",对应的变量名也要存储,而java中采用的变量名的引用就指向对应的utf_8的"abc"
那么abc直接指向这个string不行吗?
可以,不过这样的话,能够更节省一些空间复杂度,但是会消耗更多的时间,尤其对于变量之后运行中的处理
总结
常量池是把对应的我们会使用到的常量抽出来,无论是各个参数或者变量名类名等等,他的核心之一就是要复用
而字段在目前阶段只会对于final static修饰的,因为目前能够处理的也只有些final和static修饰的值,其他是不行的,也就是编译阶段能处理的也就这一些了
其他字段的赋值需要之后类的生命周期在各个阶段再进行赋值
方法介绍
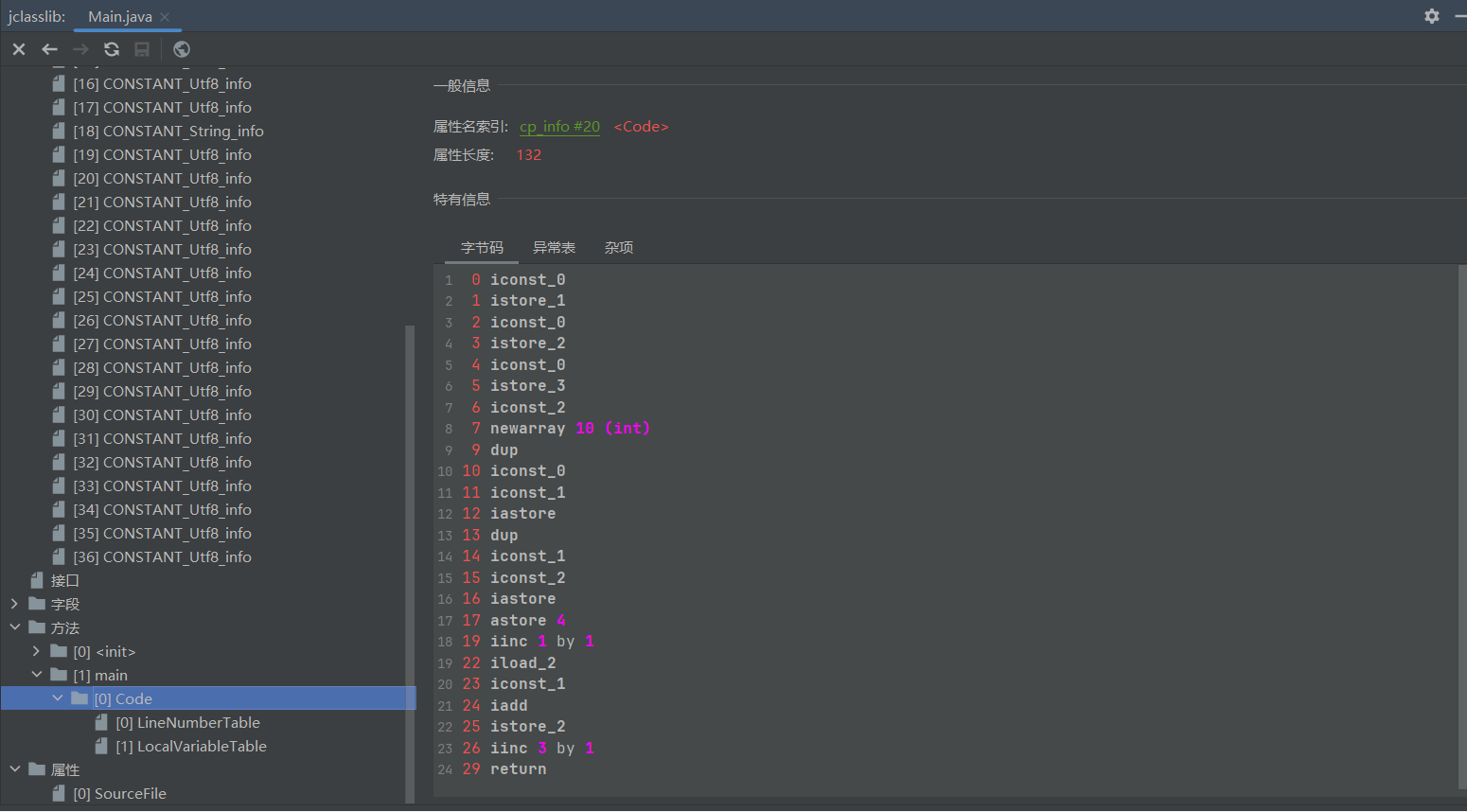
其中字节码部分就是对应方法的执行流程
而异常表主要是trycatch才会有的
而杂项对应的操作数栈的深度是字节码运行之中对于操作数栈使用的时候会使用到的栈的深度(与数据结构无异,而最大深度是因为在这之中便可以计算出来)
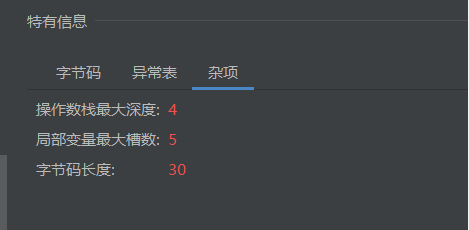
局部变量最大槽数是这里:也就是方法中使用的局部变量,包括参数等等
关于属性就不赘述了,意义不大

 浙公网安备 33010602011771号
浙公网安备 33010602011771号