Nginx+Gunicorn+Flask+Supervisor+Tritonserver 实战部署个人经验
Nginx+Gunicorn+Flask+Supervisor+Tritonserver
写在前面:
之前部署video swin Transformer的时候,只是考虑到了能不能使用,但是一旦上线使用之后,就暴露出很多的问题,尤其是速度问题,为了优化这个速度问题,头疼了好久,各种百度,对于部署方面是小白的我来说,这篇文章并不专业,记录一下优化过程,给我自己做个技术沉淀,也希望能个各位看官一个启发。
之前方案的总结
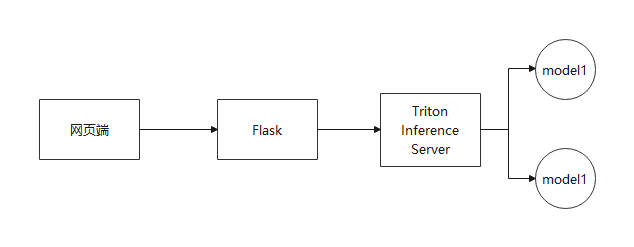
之前的方案无比简陋,先从网页端听取请求,然后flask做中转请求,顺便报错上传的文件,然后把请求传递给Triton,让Triton去调用模型仓库里的模型,大致脉络没什么大问题,但是实际使用起来还有许多地方需要优化:
- 前面用Flask的时候没有开多进程,导致只能一个请求一个请求处理
- Flask到Triton的请求是走的网络协议,由于我传递的是视频文件,数据量比较大,一来二去,网络协议速度上的劣势就非常明显,原本Video Swin Transformer就要5-6s处理一个视频,现在还得加上1-2s的传输时间
- 之前将Video Swin Transformer从pytorch转为onnx然后转为TensorRT,可能速度并没有直接使用pytorch来的快。(因为之前比较着急,没有保存pytorch的权重,所以没法进行速度的比较,但是后续我在物色新的模型的时候,逛github的issue发现,有人提到过他用了TensorRT之后比原先的慢了8倍左右)
- 视频文件和图片文件在推理的时候存在着很大的区别,图片只需要做一个Resize,而视频文件需要先读取然后抽帧(这两部分非常耗时)
- CPU密集型和IO密集型。我认为这也是视频推理的一个容易忽视的点,视频推理的预处理,即抽帧、resize等transform,或许是IO密集型,配合异步处理有奇效。
解决方案
更换模型
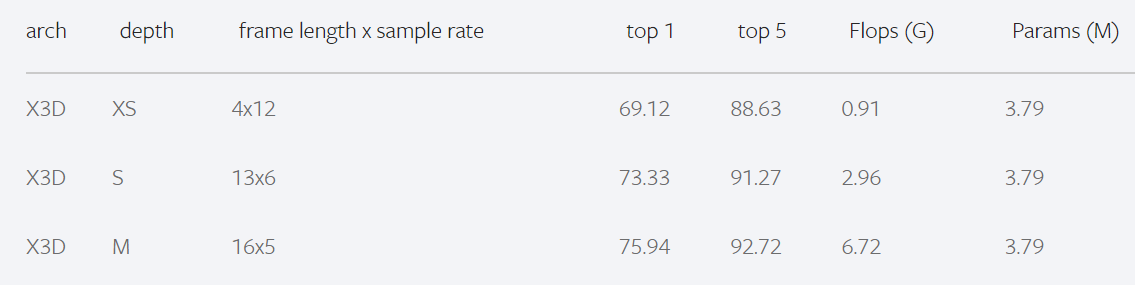
视频模型千千万,又不是非得逮着Video Swin Transformer不放,SOTA虽好,但是还得在我们自己的数据集上训练,所以挑一个速度快,精度差不多的就行。最后我把目光落在了X3D上——卷积+mobilenet架构,GPU对Transformer不太友善,卷积则非常高效。再看一眼它的精度(在我自己的数据集上都能跑到90以上),还是很不错的。
更换视频流读取库
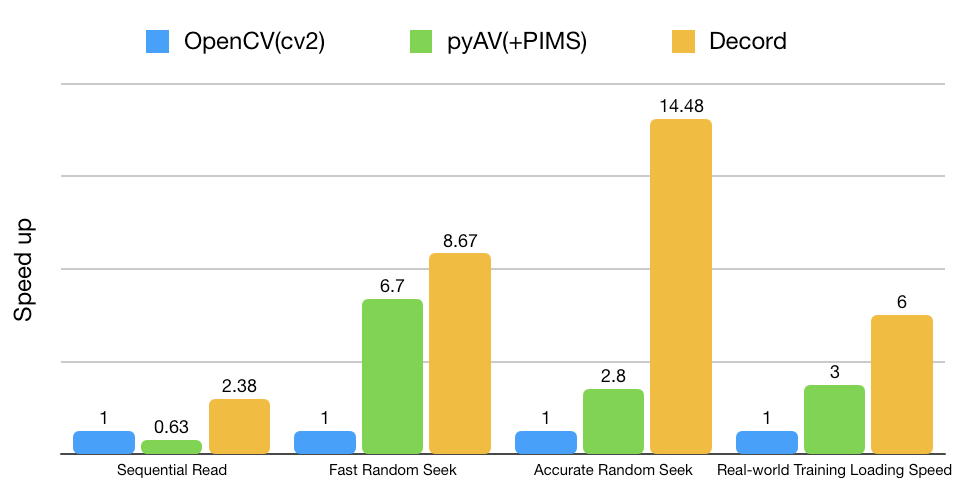
原先用的是torchvision和pyAV(opencv就不考虑了,太慢了),后来是无意间发现的decord这个库,速度相比其它的视频流读取库来说,快了不止一点两点,用起来也很方便,在Github上有详细的教学,代码也很简单。不过需要注意的是,decord是有 GPU版本和CPU版本的,GPU版本是需要从源码开始编译的。按理来说GPU读取会快一点,但是在我的视频数据集上表现得不是很明显,可能在长视频上优势会明显一点,所以我就不去折腾GPU版本了。
更换网站部署架构
为什么要在这里先提整体架构呢,因为这部分是涉及多线程和多进程管理的,对后续的pipeline优化很关键。
当前成熟的配置是:Nginx+Gunicorn+Flask+Supervisor
Gunicorn撑起Flask的多进程业务,方便管理,能在Flask单个进程出错的时候重启,防止业务一直失效。Nginx则弥补了部分Gunicorn的不足之处,至于具体是哪些不足没去深究。Supervisor则是负责管理Nginx和Gunicorn,让这两个出错的时候重启或者其它自定义操作。
Flask到Triton的请求转发优化
走网络协议速度太慢,X3D处理一段视频只需要36ms,而浪费在HTTP协议的时间就要2s,好在NVIDIA官方提供了和Triton用共享内存通信的接口,走gRPC协议,调用一下就行,具体代码可以看这个链接:gRPC + 共享内存
优化pipeline
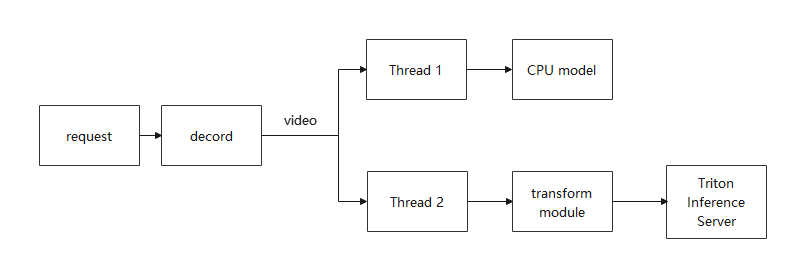
在更改pipeline的结构之前,我先粗略统计了各个处理单元的处理时间,我的CPU model平均一个视频需要2-3s,transform module也是2-3s,而得益于X3D模型的速度和共享内存的转发,推理部分平均一个视频只要0.04s左右。
有人可能此时会使用多进程去并行处理CPU model和transform module,我也考虑过,但是很可惜,在Gunicorn下用多进程似乎不是一个好主意,至少在我的场景下,运行的时候一直在空转,然后等到了设置好的超时时间自动退出,这一点我去Google和baidu的时候也有人遇到这个问题,解释是在单进程中开启多进程报错的可能性很大,这其实相当于说了等于没说。
正当我要放弃多进程的设计时,看到了一篇文章是关于CPU密集和IO密集的介绍,其中有一个观点引起了我的注意:IO密集型不止包括硬盘的IO还包括内存的访问,而我的CPU model和transform module不正由于视频文件比较大,访存开销会比较大吗?带着这个猜想,我用asyncio这个包简单实现了异步,这时奇迹发生了,速度快了将近一倍!
至此,服务端优化差不多结束了,剩下的就是客户端了,文件上传就吃掉了很大一部分的处理时间,因此我也在考虑要不要在客户端压缩上传的视频文件,但是这部分增加的处理时间是否会超过上传时间的增益呢?视频的画质损失是否会导致模型准确率下降呢?还需要一步步慢慢探索。
最后的碎碎念:nginx的进程拥有的权限是不同的,可能会导致网页访问的时候无法获取资源出现403错误,可以用ps -aux | grep nginx查看进程的拥有者是否和文件资源的访问权限相对应。
