Tritonserver+TensorRT实现服务端部署
Tritonserver+TensorRT实现服务端部署
写在前面
项目需要,因此要完成模型训练到实际服务端部署的全过程,但是之前只是专注于模型的训练,未接触过实战,就借此机会将训练好的模型部署全过程做一个记录
工具和环境需求
我本地的电脑环境如下:
Python 3.8
PyTorch 1.12.1
GPU RTX 3060 Laptop
CUDA 11.2
Tritonserver 和 TensorRT 都是 Docker 拉取的镜像,使用的命令如下表:
docker pull nvcr.io/nvidia/tritonserver:21.08-py3
docker pull nvcr.io/nvidia/tensorrt:21.08-py3
细心的应该已经注意到了,我拉取的Tritonserver 和 TensorRT 后缀都是一样的21.08,这是因为Tritonserver对能够使用的tensorrt文件是有要求的,如果运气不好,版本不对应有可能会导致Tritonserver运行不起来,为了避免踩坑,干脆就直接拉同样的即可。
如果嫌弃Docker的文件太大,也可以不拉取TensorRT的镜像,我给出下面的链接,可以自己对照表格去下载对应的版本。
https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/rel_22-07.html#rel_22-07
工具介绍
本来是想着直接用简单的Flask+TensorRT去做服务端的,但是奈何我比较懒,现在已经沉溺于Python,再去花费时间学一个Flask我估摸着时间不够,于是百度之后发现了Tritonserver,这个是NVIDIA自己做的开源产品,支持GRPC和HTTP,还说支持C API直接访问(这部分不了解,相关视频后续在官方教程里会给出)
最关键的是,官方在B站给了一个中文的教程,实战+框架理解,蛮详细的,下面是链接:
https://space.bilibili.com/1320140761/channel/collectiondetail?sid=493256
最后说一下为什么要选择TensorRT
因为如果要实际应用就要考虑模型的吞吐量,TensorRT对模型的加速是有很大的优化的,而且PyTorch到ONNX,再到TensorRT网上基本都有完善的教程和相关问题的解决方案。当前在我的笔记本上使用跑的还是蛮快的,我跑的是Video Swin-Transformer。
开搞
PyTorch转ONNX
我的模型是Video Swin-Transformer,模型代码是基于mmaction2框架做的。mmaction2是open-mmlab的项目之一,比较有名的应该就是mmdetection吧,我之前用过mmpose,数据处理模块用的时候真的爽的不要不要的,但是源码看起来也是绕迷宫一样的,多看几遍才能理清整个框架的运作流程。
然而官方的实现里没有给出Pytorch转ONNX的代码,只适用于其它模型,只好自己动手了咯。这部分并不难,给Recognizer3D.py文件添加一个forward函数,简化一下推理流程即可,就不详细描述了。
P.S. 如果你也要导出Video Swin-Transformer的ONNX模型,不建议在本地上跑,当然,如果你的内存足够大20G以上,当我没说,这东西就是内存怪物。
ONNX优化——ONNXSIM
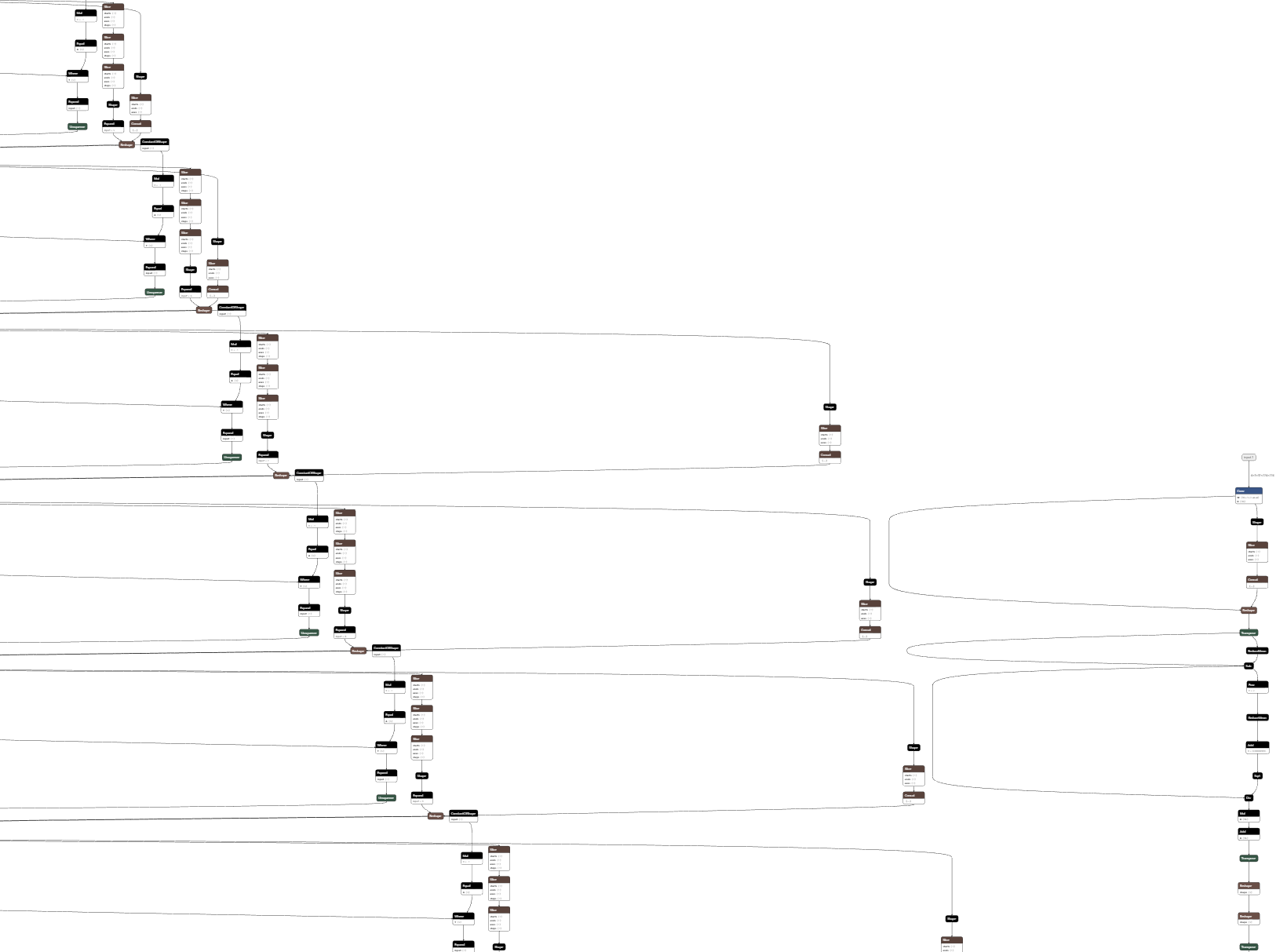
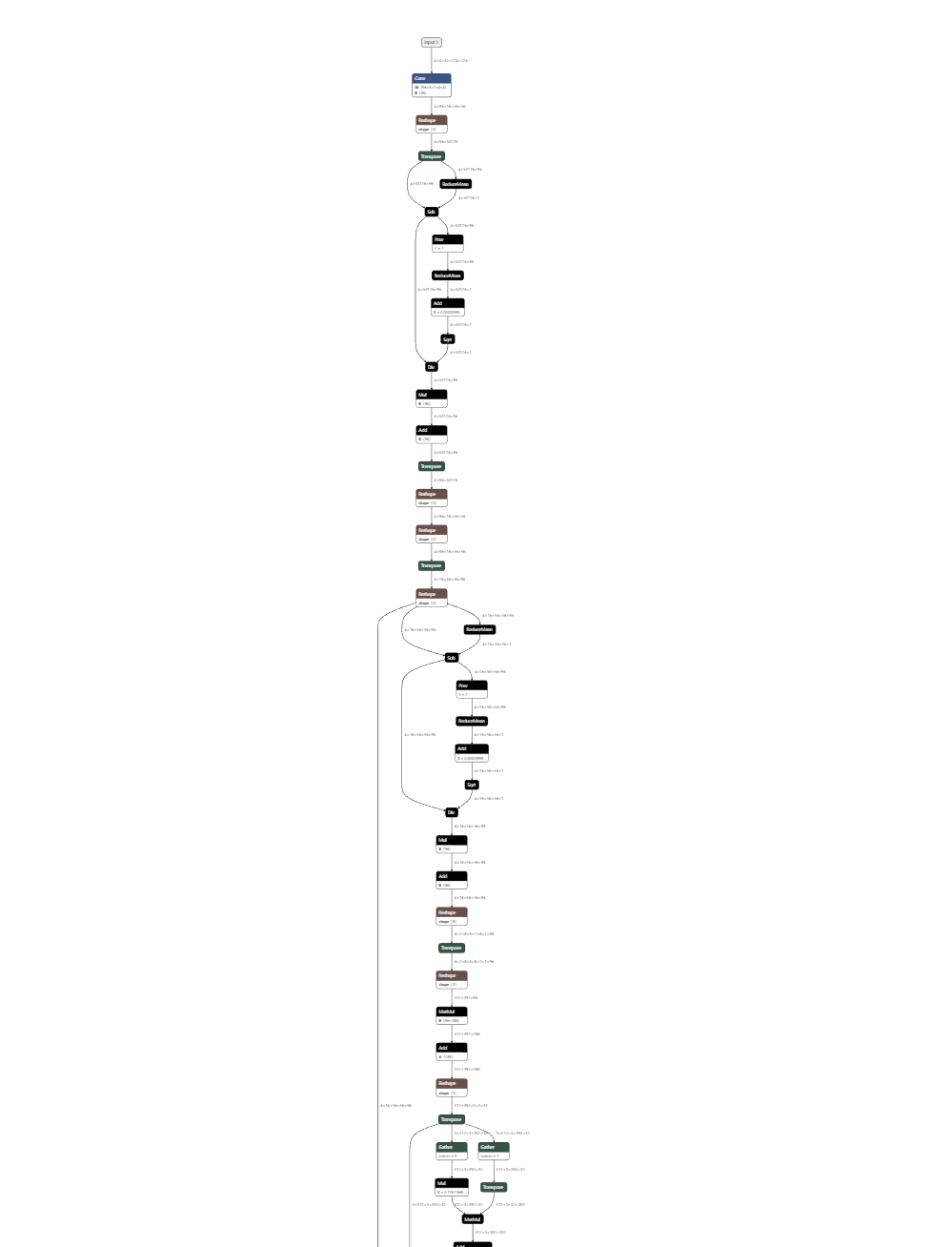
ONNXSIM对ONNX做了进一步的改进,想看模型在优化结构的前后对比可以用这个网站——netron.app,很方便。Video Swin-Transformer应用ONNXSIM之后效果出奇的好,原先的网络结构有点纷乱,优化后都快变成一条直线了。
给你们看一下效果图,非常直观,不,非常夸张
优化前:
优化后:
优化的代码很简单
python -m onnxsim input.onnx output.onnx
如果你有精力,想要进一步优化,可以选择去手动修改ONNX的结构,这个就不属于本文讨论的范围了。
P.S. 我在Linux的GPU服务器上做ONNXSIM的时候,总是会显示Simplifying然后卡死,很奇怪,在自己本地就没这种事情
ONNX转TensorRT
到了这一步,先别急着上手操作,先检查一下你的ONNX模型中涉及的算子有哪些,我推荐使用onnxexplorer
pip install onnxexplorer
然后用它查看onnx模型需要哪些算子
onnxexp glance -m input.onnx
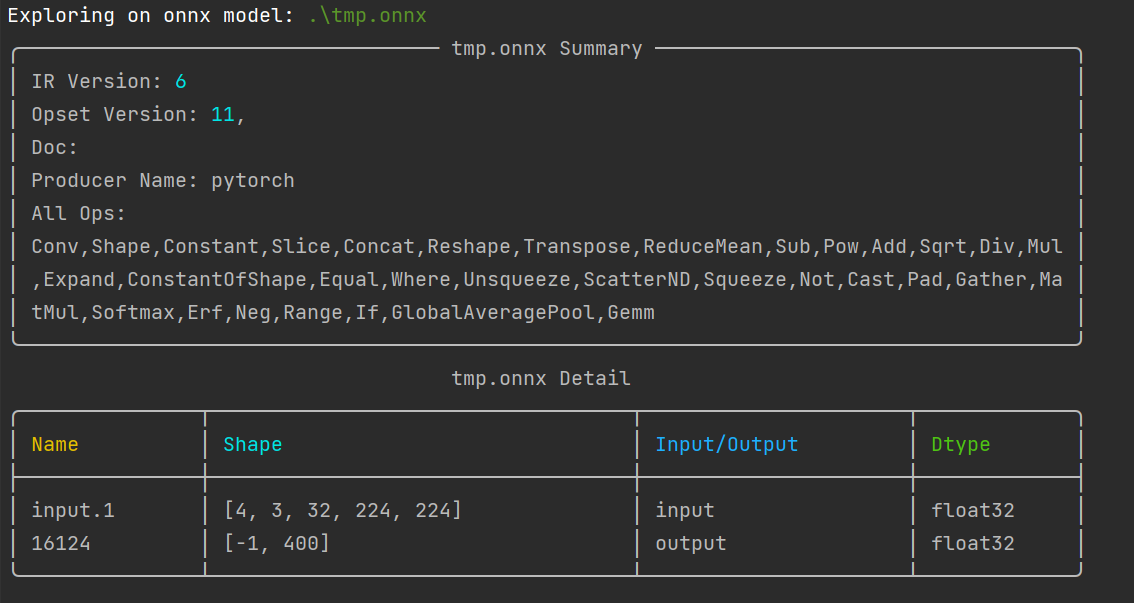
需要注意的是,上面的模型我是经过处理的,在处理前,是有一个算子叫做Mod,也就是取余操作,这个操作在TensorRT中是不支持的,你可以通过自己重新写一个算子,在TensorRT中叫Plugin,来解决这个问题,但是奈何我比较懒,我选择直接从根源解决问题,在Video Swin-Transformer源码中找到%这个运算符,用下面的函数代替:
def mod(x,y):
res = x - (x // y)*y
return res
至于如何查看ONNX转TensorRT支持的算子有哪些,请看下面的链接,Y是支持,N是不支持
https://github.com/onnx/onnx-tensorrt/blob/main/docs/operators.md
上述准备工作完成之后,即可上手转换,将ONNX文件转换为plan文件,这个因为Tritonserver似乎是只认这个.plan后缀,没试过其它后缀行不行。
trtexec --onnx=input.onnx --saveEngine=output.plan --buildOnly
这个trtexec工具是一个测试用的工具,非常好用,TensorRT自带的,去下载好的TensorRT文件夹下面的bin目录下就能找到。后面的--buildOnly选项表示跳过测试阶段,直接输出模型,如果你们想看自己模型的吞吐量,时延等等参数可以选择不加这个选项。
最后补充一点,TensorRT似乎是不支持F.pad()这个张量操作的,会导致转TensorRT失败,官方的论坛里说用另一个工具做一个常量折叠就可以解决问题了,相关代码在下面
polygraphy surgeon sanitize --fold-constants input.onnx -o folded.onnx
Tritonserver
到这里已经是最后一步了,但是仍然需要小心一点,就比如下面的命令
docker run --gpus all -it --rm --name triton_server \
-p8001:8001 -p8002:8002 -p8003:8003 \
-v D:\文档\dockerRepo:/workspace/dockerRepo \
nvcr.io/nvidia/tritonserver:21.08-py3
仔细看官方的教学视频可以发现,他有一个多余的选项--net host,但是这个选项会导致后面的-p失效,你可以尝试一下,然后就会发现错误提醒。在我自己的电脑上8000端口被占用了,于是我就只好搞一个重映射,最好前后的端口号保持一致,这样子方便后续设置,也方便记忆。
-v选项是将本地仓库映射到docker中去,Repository的结构也有所要求,由于使用了TensorRT格式的模型,这一部分可以简便很多,可以不用写配置文件。大致的仓库架构如下:
-dockerRepo
--model_1
---1
----model_1.plan
---model_1_labels.txt
--model_2
其中数字代表着版本号,这是约定俗成的,也方便server做版本管理,然后运行下面的代码即可运行服务器了
tritonserver --model-repository=./dockerRepo --strict-model-config=false --http-port 8001 --grpc-port 8002 --metrics-port 8003
如果运行起来显示Model那一栏是空的,很有可能是TensorRT的版本和Tritonserver的版本不兼容,请仔细检查。
为了快速检验是否成功,可以使用curl去检查一下
curl -v localhost:8001/v2/health/ready
成功返回的话就是正常运行了,接下来编写client端即可,client的编写官方已经给出样例,自己学习即可,仔细展开篇幅太长不合适。
https://github.com/triton-inference-server
以上就是完整搭建推理服务器的全过程了,虽然简单,但是基本涵盖了大部分内容,进阶的部分请参考官方文档和官方教程,Tritonserver有很多有用的选项可以设置,比如batch的合成,队列的等待时间等等。
写在后面
好久没写博客了,论文终于写完了,后面有时间的话就陆陆续续把以前的一些笔记整理一下发上来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号