数据挖掘导论
导论
数据挖掘,单纯从字面意思理解,可能会存在误区,认为只是像爬虫一样做着简单重复劳动,而这只是冰山一角,更加全面的解释我认为应该是从数据中挖掘到价值和规律。
数据矿——数据集
总结一下数据来源

- data.gov 美国政府公开数据集
- kaggle
- open-EI
- UCI公开数据库
“挖掘机”——数据挖掘算法
- 决策树
- KNN
- 神经网络
- SVM
模型的评估
accuracy的计算
accuracy = 预测与事实相符合的数量 / 总数
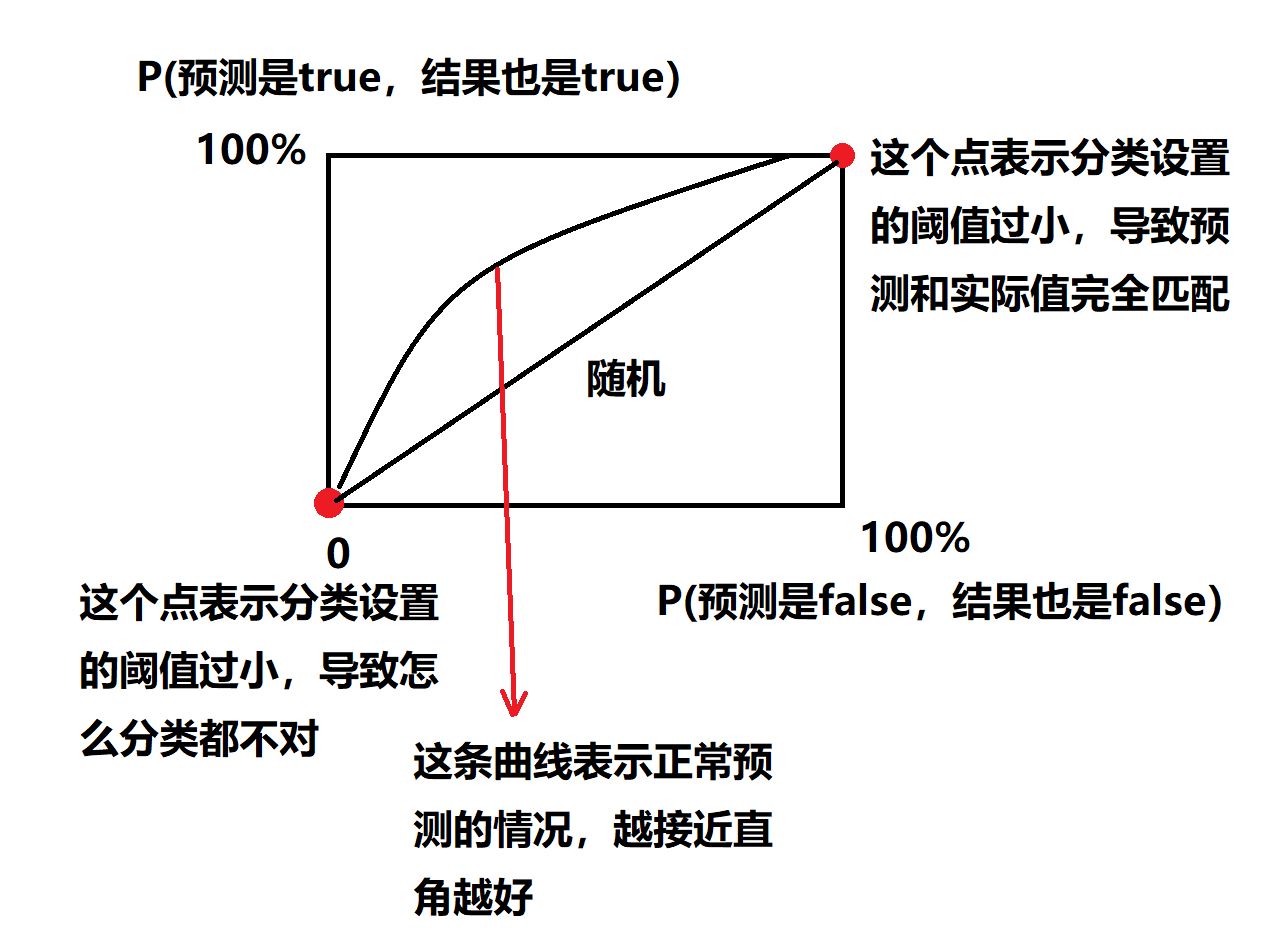
AUC的计算
AUC : area under curve
AUC指的就是使用红色箭头注释的曲线下方区域面积,越接近1越可靠
分清什么不能做,怎么做
can not do what
带有随机性的东西,比如说没有人为操控的彩票,受多因素影响的股市
how to do
- 不能纸上谈兵,仅仅靠几条曲线就凭空得出结论是极其不靠谱的
- 时刻警惕幸存者偏差,由于专业限制等因素的存在,无法跳出固有的逻辑思维(二战飞机的例子)
- 寻找数据之间的内在联系,挖掘数据的价值,前提是这些价值不是常识或稍加思考就能得到的
数据挖掘流程
1.数据收集
来自不同的渠道,不同的文件,文件的格式也可能不同,因此需要一个通用的平台对这些不同的文件,不同的文件格式进行统一的处理
2.数据预处理
这一步在实际应用的过程中,难度比较大,因为可能存在一些dirty数据,数据缺失等问题很常见
3.数据建模
4.模型评估
5.线上部署
有关数据隐私
以问卷搜集敏感问题为例子
基础版:
一个问题拆分成两个:
Q1:你买过毒品
Q2:你没买过毒品
给一个不公平的硬币(硬币投到正面的概率是p,则反面的概率是1-p)
正面回答Q1,反面则回答Q2
因此,平均的买过毒品的概率为:
P = p * P(Q1的答案为true) + (1-p) * P(Q2的答案为false)
变换一下,
P(Q1的答案为true) = (P + p - 1) / (2p-1)
进阶版:
问题Q:你是否购买过毒品?
为了鼓励问卷填写者的积极性,我们给予金钱的奖励,同时问卷填写的人使用一枚不太公平的硬币来决定是否如实回答问题(硬币投到正面的概率是p,则反面的概率是1-p)
正面:如实回答;
反面:再投一次硬币,如果是正面就写Q1,如果是反面就写Q2;
Q1:你买过毒品
Q2:你没买过毒品
以上方法的好处就在于,如果抛硬币的人抛到了正面,但是又不想如实回答,他可以在不被别人发现的情况下,为了掩人耳目再抛一次硬币
