
GPUStack v0.4:文生图模型、语音模型、推理引擎版本管理、离线支持和部署本地模型
 千呼万唤,GPUStack 迄今最受用户关注、超多新功能的版本重磅发布!
千呼万唤,GPUStack 迄今最受用户关注、超多新功能的版本重磅发布!
GPUStack 是一个专为运行 AI 模型设计的开源 GPU 集群管理器,致力于支持基于任何品牌的异构 GPU 构建统一管理的算力集群。无论这些 GPU 运行在 Apple Mac、Windows PC 还是 Linux 服务器上,GPUStack 都能将它们纳入统一的算力集群中。管理员可以轻松地从 Hugging Face 等流行的模型仓库中部署 AI 模型,开发人员则能够通过 OpenAI 兼容的 API 访问这些私有模型服务,就像使用 OpenAI 或 Microsoft Azure 提供的公共模型服务 API 一样便捷。
随着越来越多的用户在 RAG、AI Agents 和其他多样化场景中应用 GPUStack,用户需求不断增加。基于用户的高优先级需求,我们推出了功能强大的 GPUStack v0.4 版本。
GPUStack v0.4 版本的核心更新包括:
- 新增三种模型类型支持:文生图模型、Speech-to-Text(STT)语音模型和 Text-to-Speech(TTS)语音模型。
- 推理引擎版本管理:支持为每个模型固定任意推理引擎版本。
- 新增 Playground UI:提供 STT、TTS、文生图、Embedding 和 Rerank 的 Playground 调试 UI。
- 离线支持:支持离线安装、离线容器镜像及离线部署本地模型。
- 扩展兼容性:进一步扩展了对操作系统的支持,包括一些遗留操作系统和国产操作系统。
- 问题修复与优化:针对社区用户反馈的问题进行了大量改进和增强。
这一版本提升了 GPUStack 的适用性和稳定性,更好地满足多样化的使用需求。
有关 GPUStack 的详细信息,可以访问:
GitHub 仓库地址: https://github.com/gpustack/gpustack
GPUStack 用户文档: https://docs.gpustack.ai
重点特性介绍
支持文生图模型
GPUStack 新增了对文生图模型的支持!在 llama-box 推理引擎中,我们集成了 stable-diffusion.cpp,从而实现对文生图模型的支持,我们还提供了对 昇腾 NPU 和 摩尔线程 GPU 的支持。GPUStack 可以运行在 Linux、macOS 和 Windows 操作系统上,利用 NVIDIA GPU、Apple Metal GPU、昇腾 NPU 和 摩尔线程 GPU 来运行 Stable Diffusion、FLUX 等文生图模型。

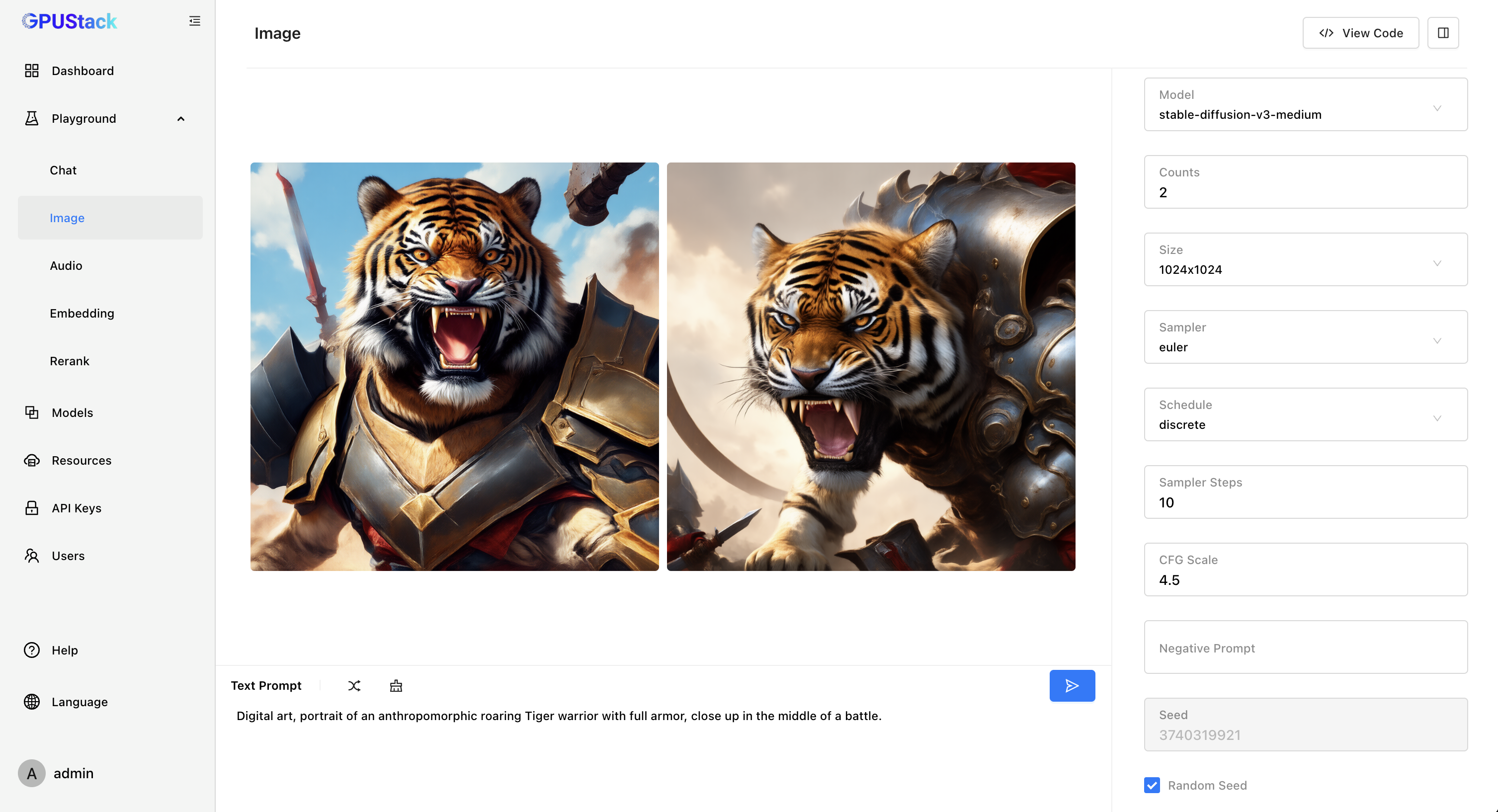
此外,我们还提供了经过调优的 All-in-one 文生图模型,模型列表可查看:
https://huggingface.co/collections/gpustack/image-672dafeb2fa0d02dbe2539a9
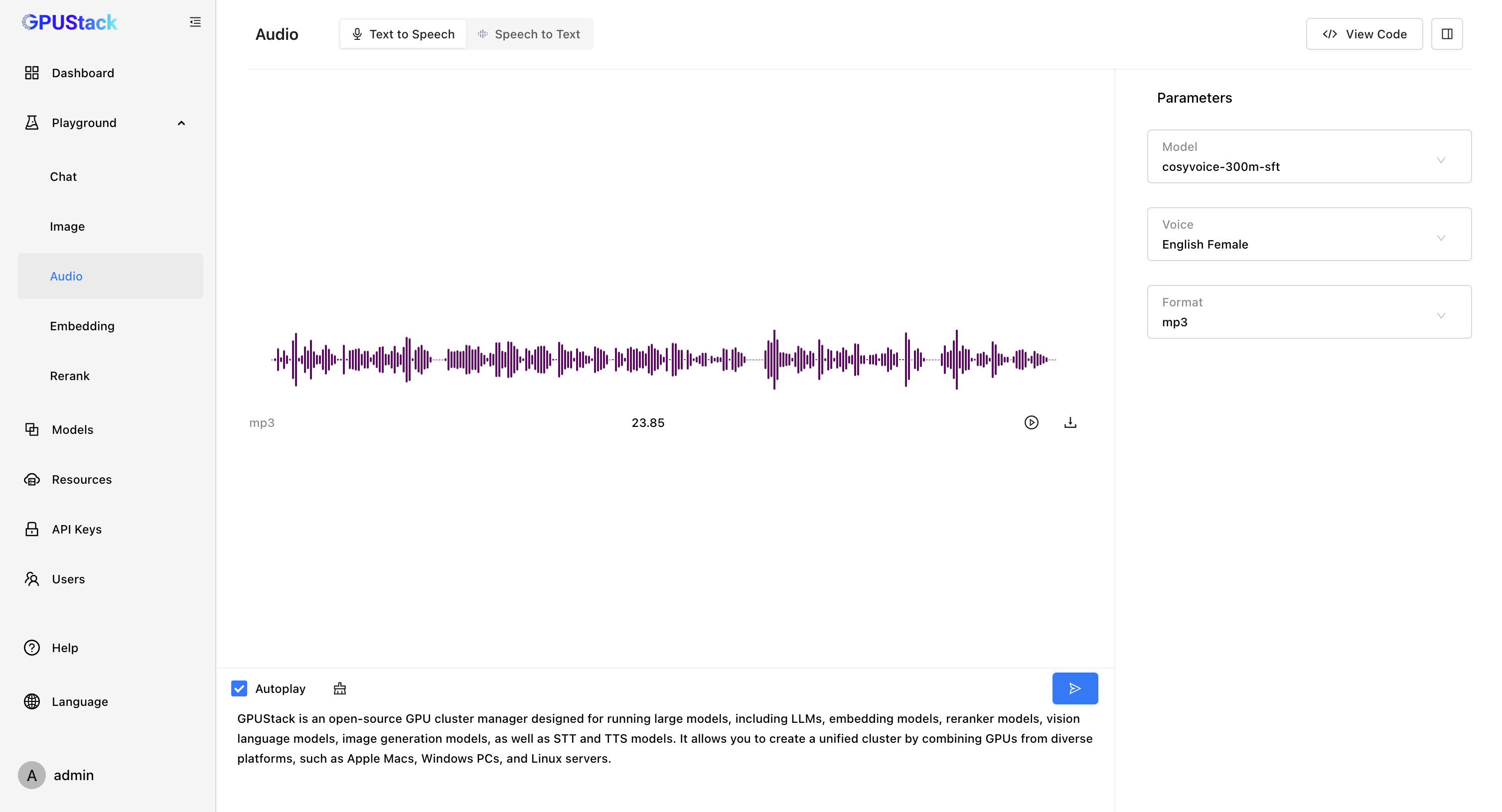
支持语音模型
GPUStack 新增了对语音模型的支持!我们推出了语音模型推理引擎 vox-box [ https://github.com/gpustack/vox-box ],vox-box 是一个支持推理 Text To Speech 和 Speech To Text 模型并提供 OpenAI API 的推理引擎,目前对接了 Whisper、FunASR、Bark 和 CosyVoice 后端。
- Text To Speech
- Speech To Text
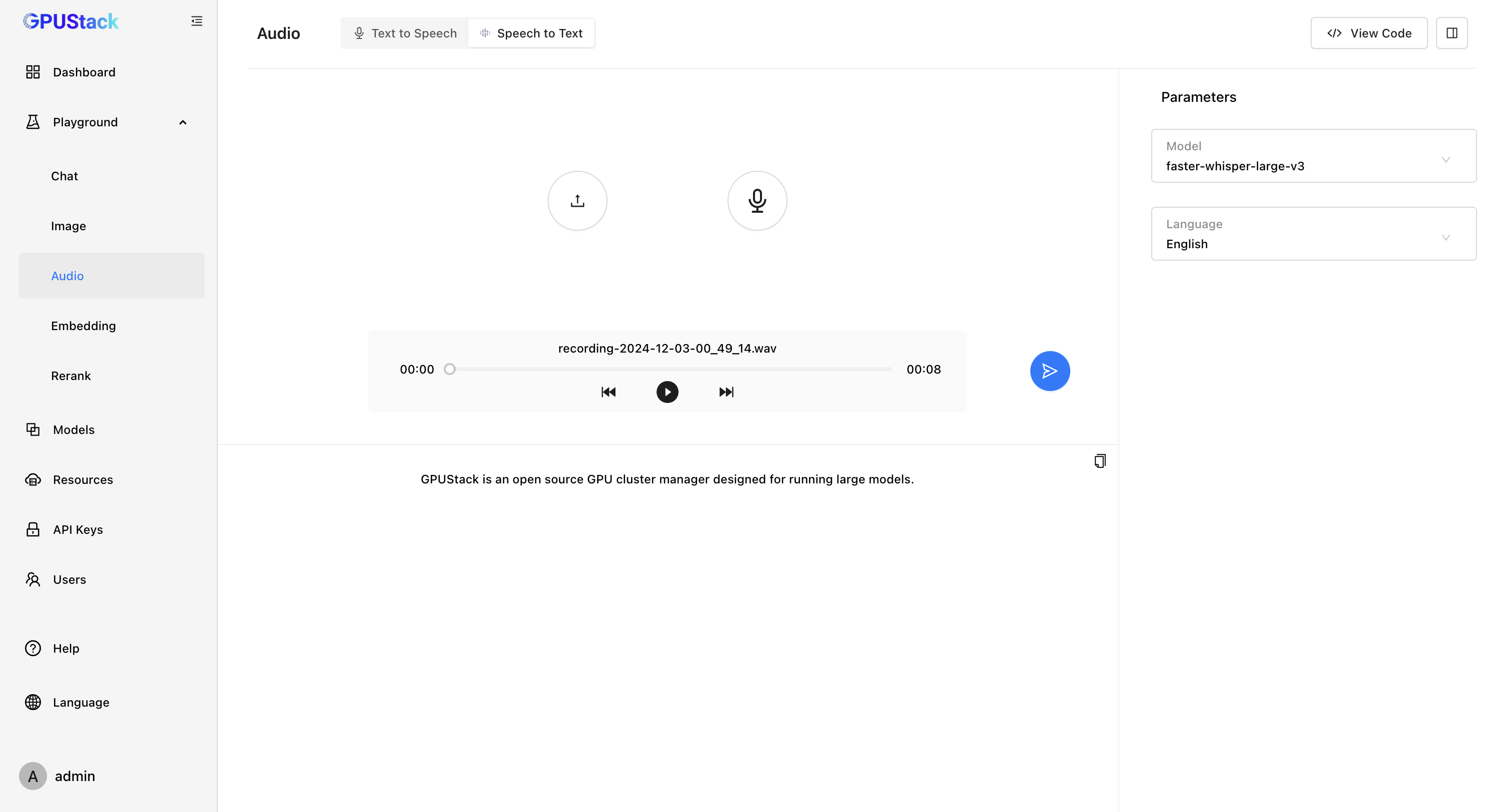
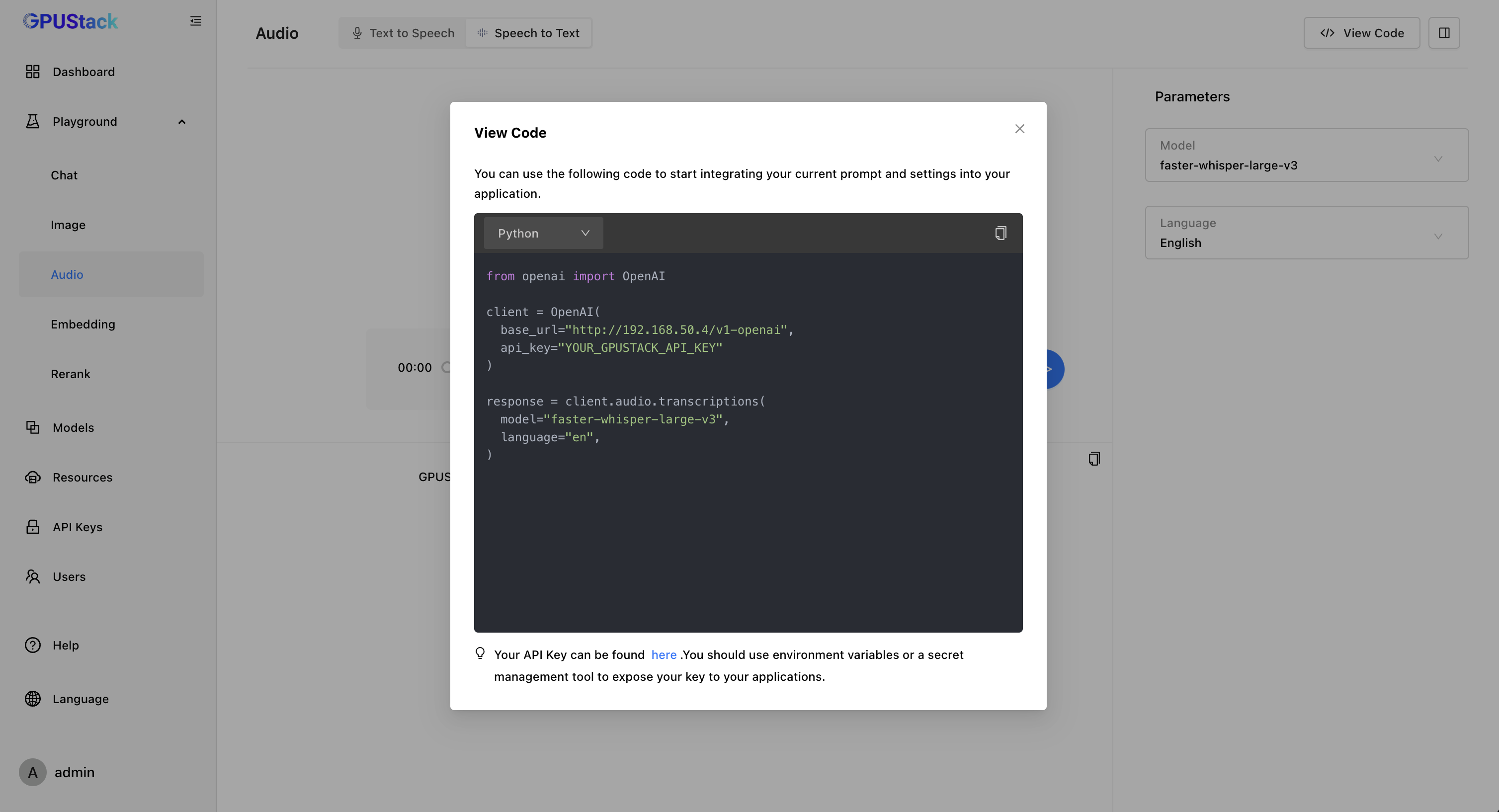
通过 vox-box ,GPUStack 可以支持 Whisper、Paraformer、Conformer、SenseVoice 等 Speech To Text 模型和 Bark、CosyVoice 等 Text To Speech 模型,我们将持续扩展对各种语音模型的支持,包括优化各种语音模型的效果和性能。当前支持的模型列表可查看:
https://github.com/gpustack/vox-box#supported-models
推理引擎版本管理
AI 领域迭代速度极快,各类新模型层出不穷,为适配这些新模型,推理引擎的更新频率也随之提高。然而,新版本的引入并非总能保持稳定,有时会带来新的 Bug,甚至导致与旧模型不兼容。这给模型部署带来了两难选择:升级推理引擎以支持新模型可能影响旧模型的稳定运行,而维持旧版本又难以体验新模型。
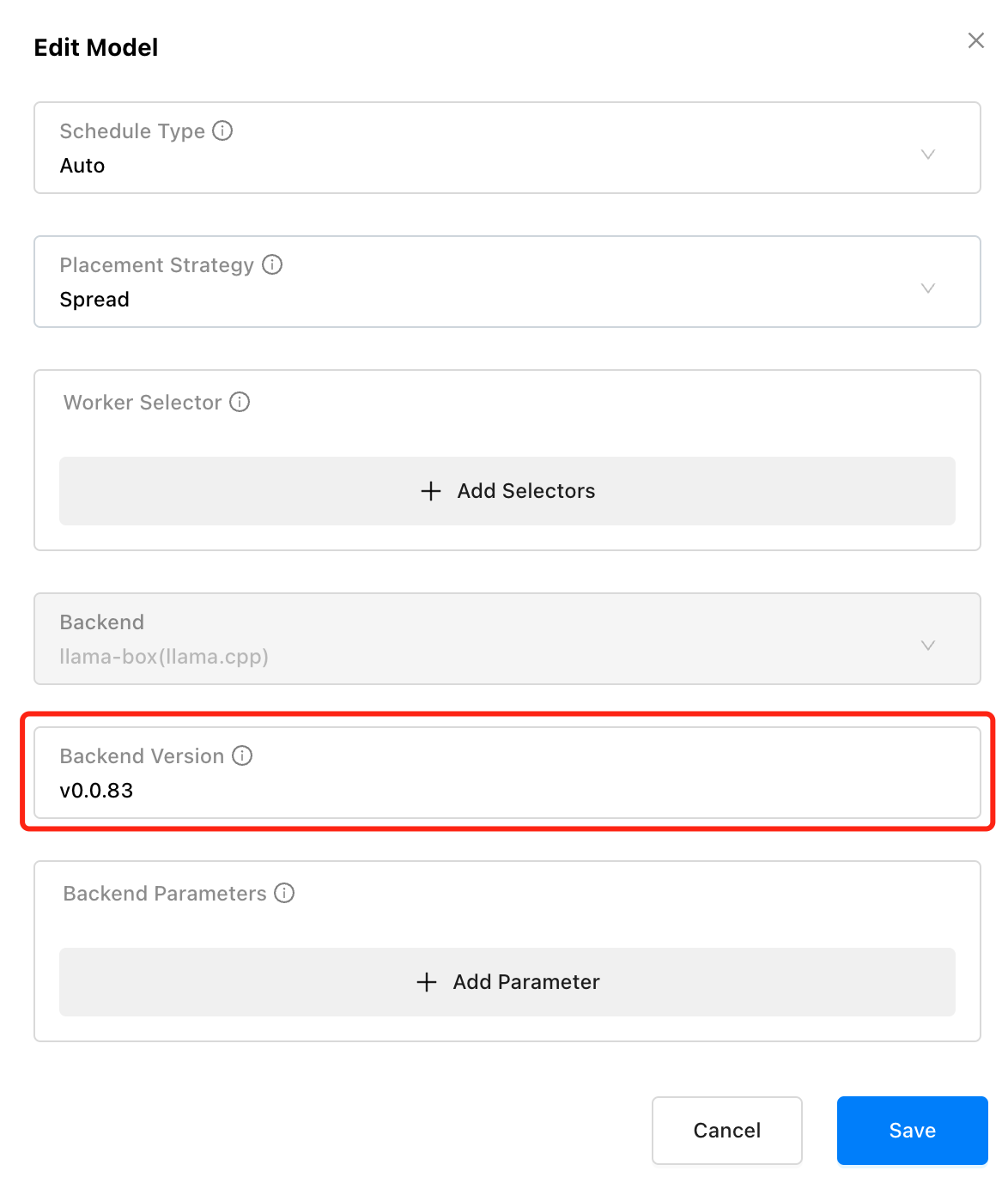
为了解决这一问题,我们设计了一个松耦合的架构,将 GPUStack 与底层推理引擎版本解耦,提供了推理引擎的版本管理能力。在部署模型时,可以为每个模型固定任意可用的推理引擎版本,GPUStack 会自动使用相应版本运行模型。这样一来,既可以同时支持多个推理引擎版本,又能在 GPUStack 升级时保持旧模型的稳定运行。解决了单一推理引擎版本无法同时适配新旧模型的难题,满足了稳定性与灵活性的双重需求。
新增 Playground UI
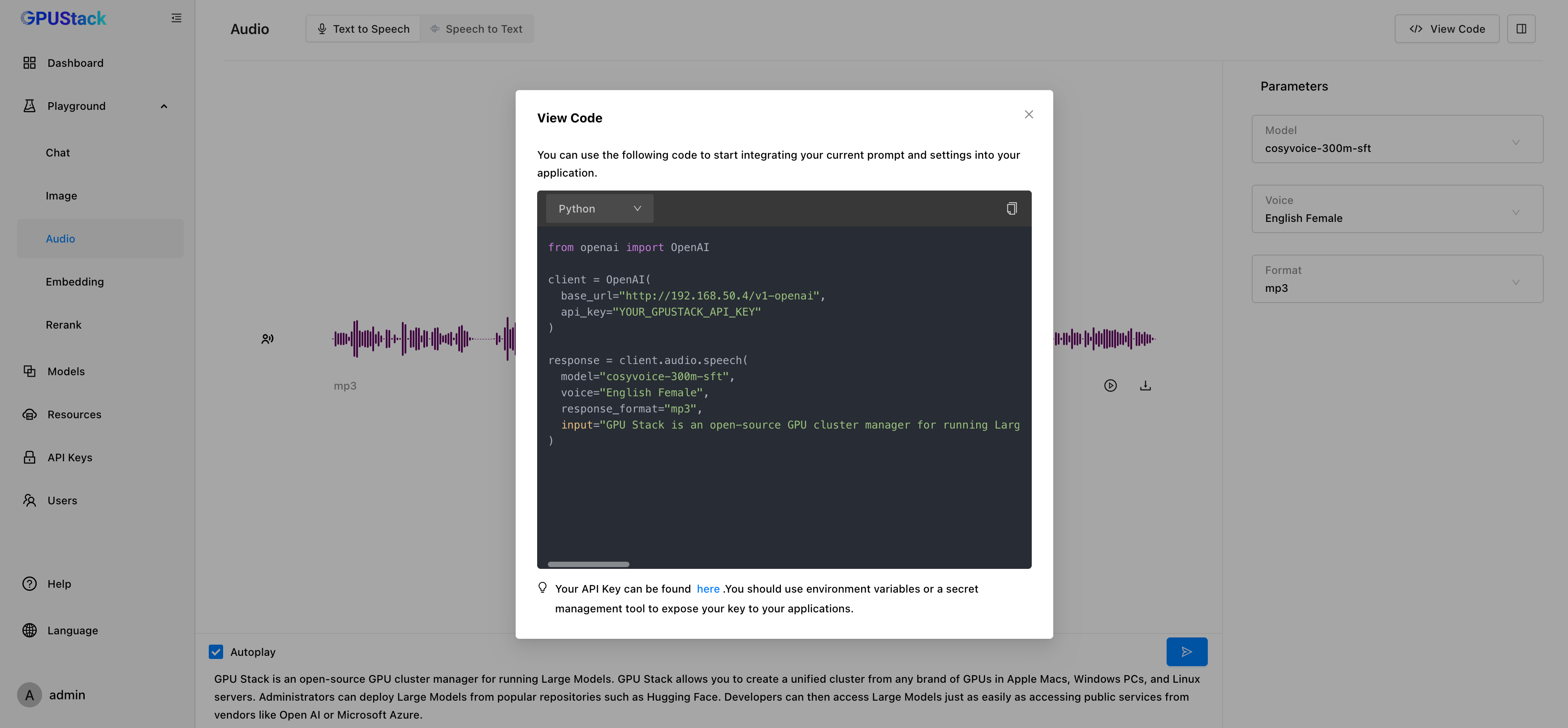
之前 Playground 只支持 Chat 模型的调试。在新版本中,GPUStack 新增了对文生图、Speech-to-Text(STT)、Text-to-Speech(TTS)、Embedding 和 Reranker 模型的 Playground UI。用户在部署模型后,可以通过 Playground 测试模型效果并进行调优。
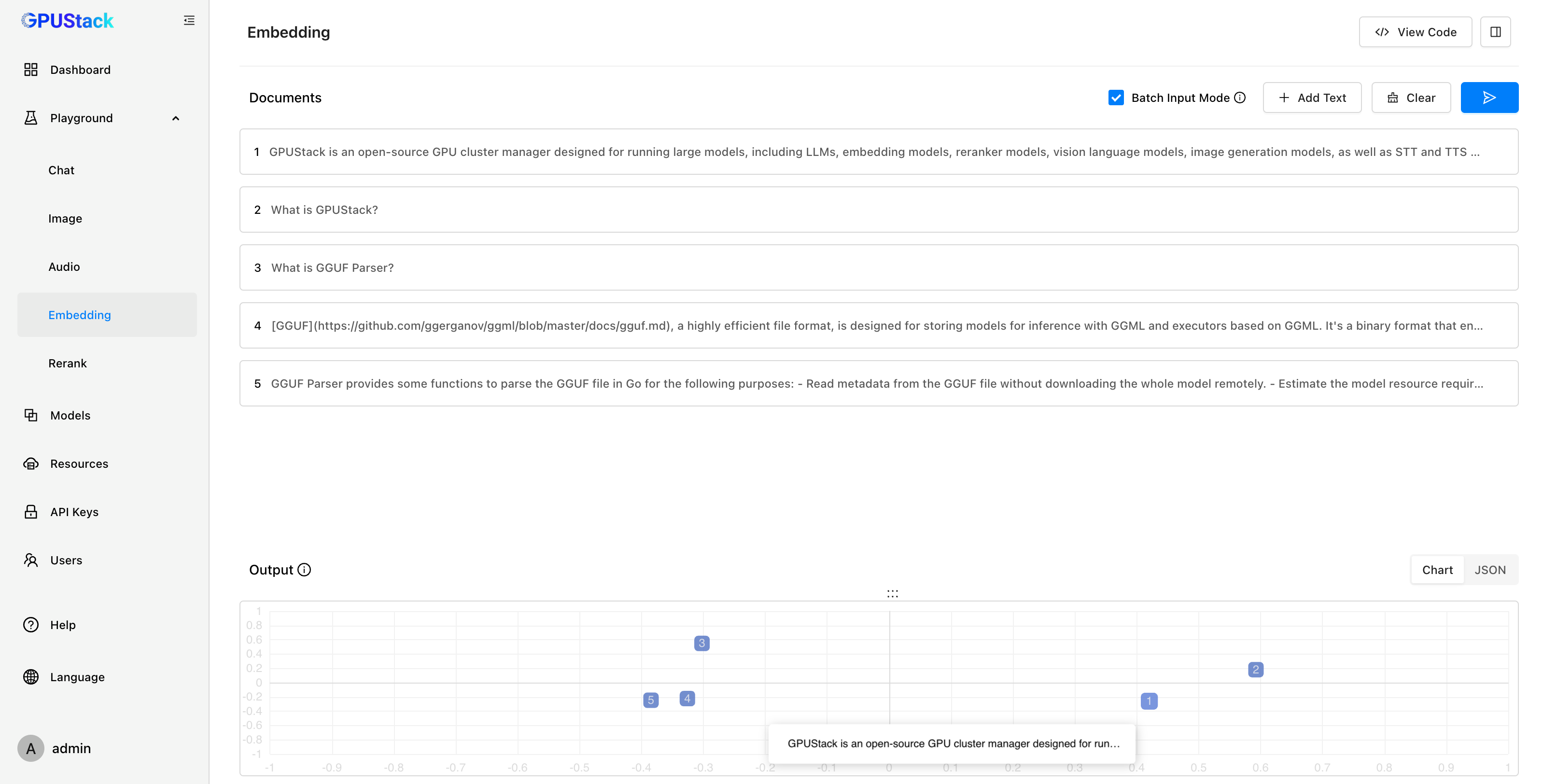
在测试 Embedding 模型时,Playground 可以提供直观的可视化分析。通过对嵌入向量进行 PCA(主成分分析)降维,用户能够在降维坐标空间中对比多段文本的距离,直观判断向量距离和文本相似度。完成调测后,可以通过 View Code 按钮查看调用模型 API 的代码示例。
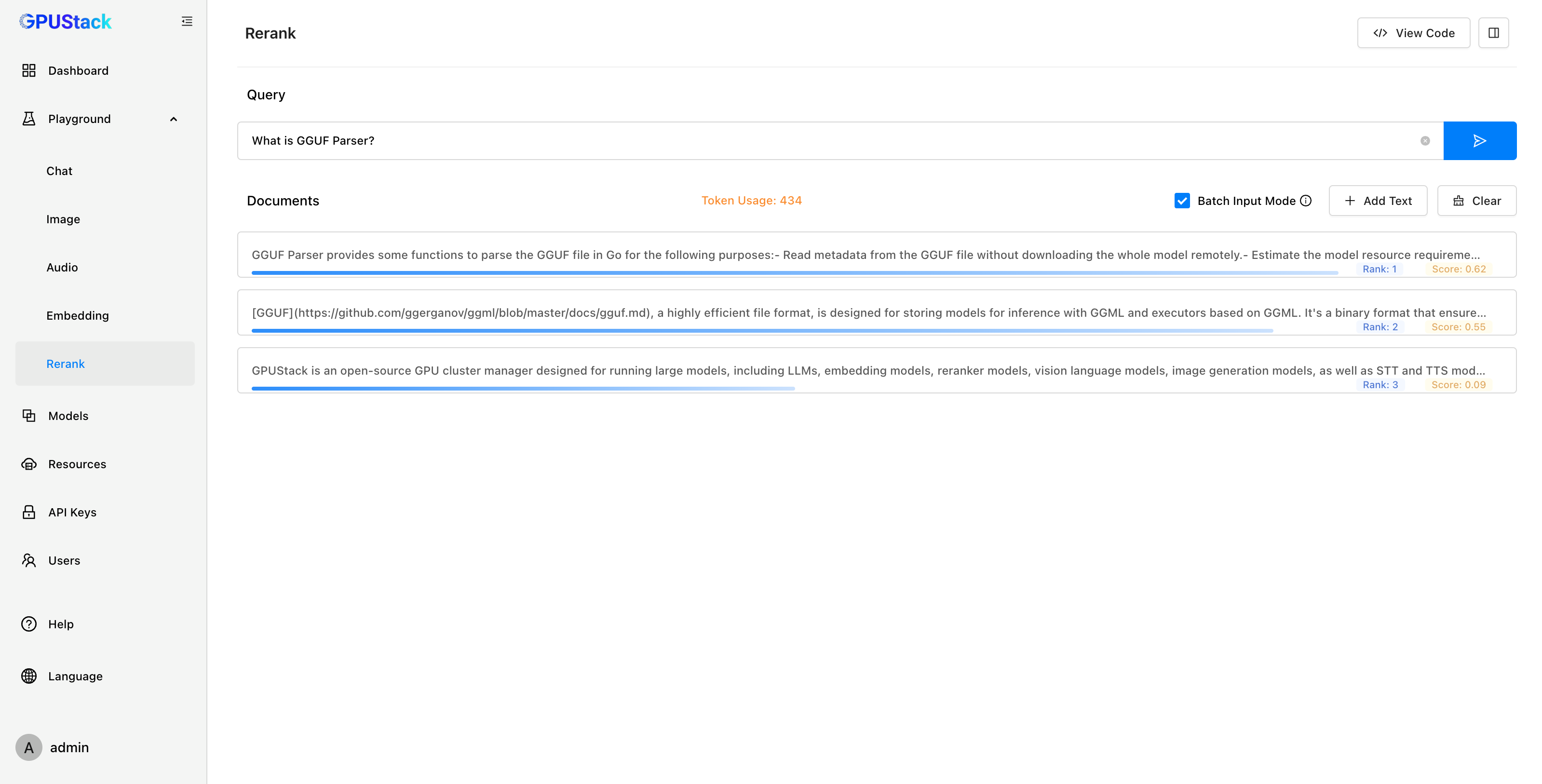
在测试 Rerank 模型时,Playground 可以提供直观的重排结果展示。用户可以输入 Query 和一组 Documents,模型会根据 Query 的内容对 Documents 进行排序,并返回每个文档的相关性得分。用户可以通过结果判断模型对输入的理解和排序的准确性。完成调测后,可以通过 View Code 按钮查看调用模型 API 的代码示例。
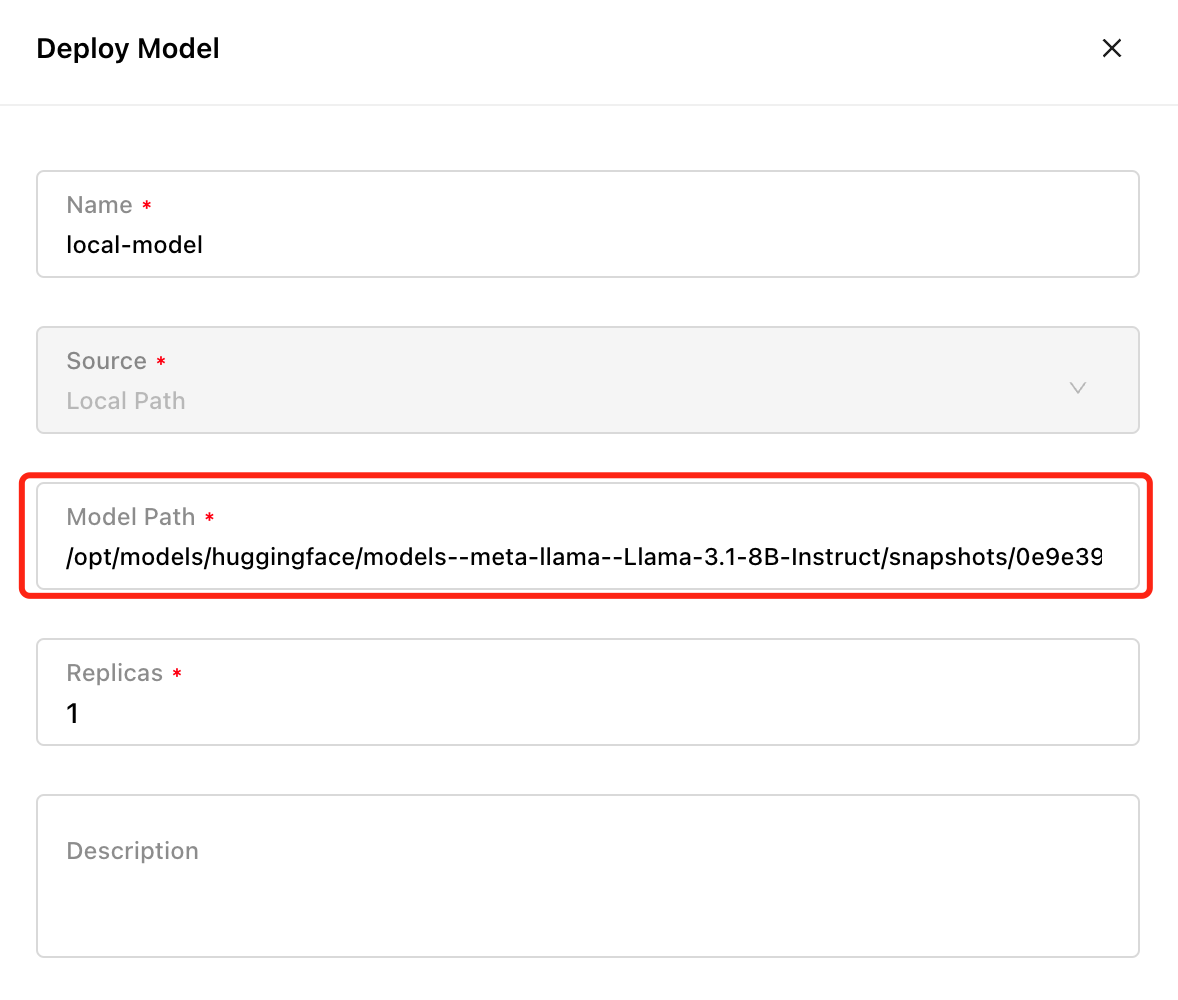
支持从本地路径部署模型
为了支持离线场景、重复利用用户已下载的模型文件以及运行用户经过微调的本地模型,新版本在部署模型时,除了支持从 Hugging Face、ModelScope 和 Ollama Registry 部署模型外,还新增了 Local Path 选项,可直接加载本地路径中的模型文件进行部署。
用户可以通过 huggingface-cli、modelscope CLI 或其他工具提前下载模型,并将模型文件上传到对应的节点。在部署时,选择 Local Path 选项,并填写模型文件的绝对路径即可部署。注意,用户需要调整调度选项,将模型固定调度到包含模型文件的节点。或者需要确保所有节点上均存在该模型文件,以便模型调度到任何节点都能够正常加载和运行。
支持离线安装和运行
GPUStack 现在支持离线安装和运行,提供了两种离线安装方式:Python 原生安装和Docker 安装。
对于 Python 原生安装,新版本提供了离线安装所需的指令和详细文档,用户可以在没有网络连接的环境中按照文档进行安装。
对于 Docker 安装,GPUStack v0.4 版本提供了多个分发版本的离线容器镜像,包括 CUDA、NPU(CANN)、MUSA 和 CPU 等。以下是运行命令的示例:
- CUDA 12( NVIDIA Driver 12.4 以上 )需要配置 NVIDIA Container Runtime
docker run -d --gpus all -p 80:80 --ipc=host \
-v gpustack-data:/var/lib/gpustack gpustack/gpustack:latest
- 昇腾 NPU( NPU Driver 24.1 rc2 以上 )需要配置 Ascend Container Runtime
docker run -d -p 80:80 --ipc=host \
-e ASCEND_VISIBLE_DEVICES=0-7 \
-v gpustack-data:/var/lib/gpustack gpustack/gpustack:latest-npu
- 摩尔线程 MUSA ( rc3.10 以上)需要配置 MT Container Toolkits
docker run -d -p 80:80 --ipc=host \
-v gpustack-data:/var/lib/gpustack gpustack/gpustack:latest-musa
- CPU ( AVX2 或 NEON )
docker run -d -p 80:80 -v gpustack-data:/var/lib/gpustack gpustack/gpustack:latest-cpu
具体的配置细节,请参考 GPUStack 以及各硬件厂商的官方文档,以确保正确的配置和兼容性。
手动控制 GGUF 模型分配的 GPU 数量和多卡切分比例
GPUStack 提供了模型自动化调度的功能,能够根据调度算法自动决定为模型分配多少块 GPU 卡。在之前的版本中,部署 GGUF 模型时,调度规则会自动根据当前可用的 GPU 数量以及每块 GPU 的剩余显存来计算和分配 GPU 资源。
为了应对一些 GPUStack 无法覆盖的使用场景,在 v0.4 版本中,我们新增了支持手动分配 GPU 数量和配置模型在多张 GPU 卡上的切分比例的功能。用户可以通过 --tensor-split 参数来手动指定 GPU 数量和切分比例,从而实现更精细化的控制和动态切分:
--tensor-split=1,1:分配 2 卡,按1:1的比例切分模型--tensor-split=2,1,1:分配 3 卡,按2:1:1的比例切分模型--tensor-split=10,16,20,20:分配 4 卡,按每块卡的剩余显存大小10:16:20:20的比例切分模型
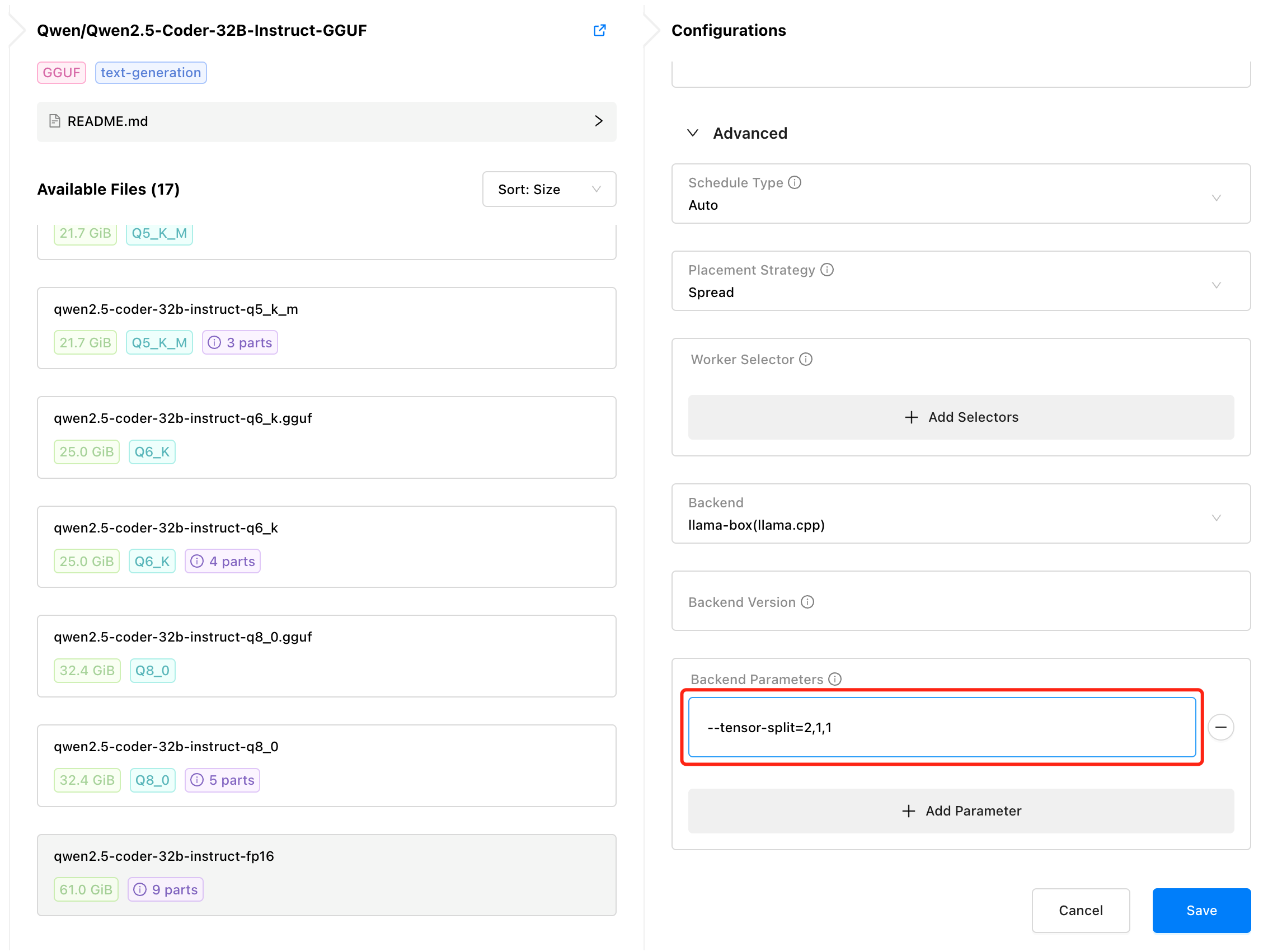
优化 GGUF 模型资源分配和调度
GPUStack v0.4 版本对 gguf-parser 进行了优化,能够更准确地计算模型的资源需求。此版本还支持根据管理员在部署模型时自定义的上下文大小来计算实际的显存占用,从而优化调度决策,减少资源竞争时发生 OOM 的概率,提升模型服务的稳定性。
支持从 HuggingFace 镜像源部署模型
GPUStack 支持从 Hugging Face、ModelScope 和 Ollama Registry 模型仓库部署模型。由于网络限制,国内用户无法直接从 Hugging Face 部署模型,尽管可以选择从 ModelScope 和 Ollama Registry 部署,但其支持的模型库相较于 Hugging Face 较为有限。
为了改善这一问题,GPUStack 在新版本中引入了 HF_ENDPOINT 环境变量,允许用户配置 Hugging Face 的镜像源。通过该配置,用户可以在部署模型时从 Hugging Face 镜像源检索和下载所需模型。
当启动 GPUStack 的 systemd 或 launchd 服务时,系统会从 /etc/default/gpustack 文件中读取环境变量。在该文件中,用户可以添加所需的环境变量设置来配置镜像源。
在所有节点编辑 /etc/default/gpustack 文件,配置 HF_ENDPOINT 环境变量:
vim /etc/default/gpustack
例如,添加以下配置,以使用 https://hf-mirror.com 作为 Hugging Face 镜像源:
HF_ENDPOINT=https://hf-mirror.com
重启服务生效:
systemctl restart gpustack
重启 GPUStack 后,在界面选择从 Hugging Face 部署模型时,系统将从配置的 Hugging Face 镜像源检索和下载模型。请注意,所有节点都需要配置该环境变量,确保统一从镜像源下载模型:
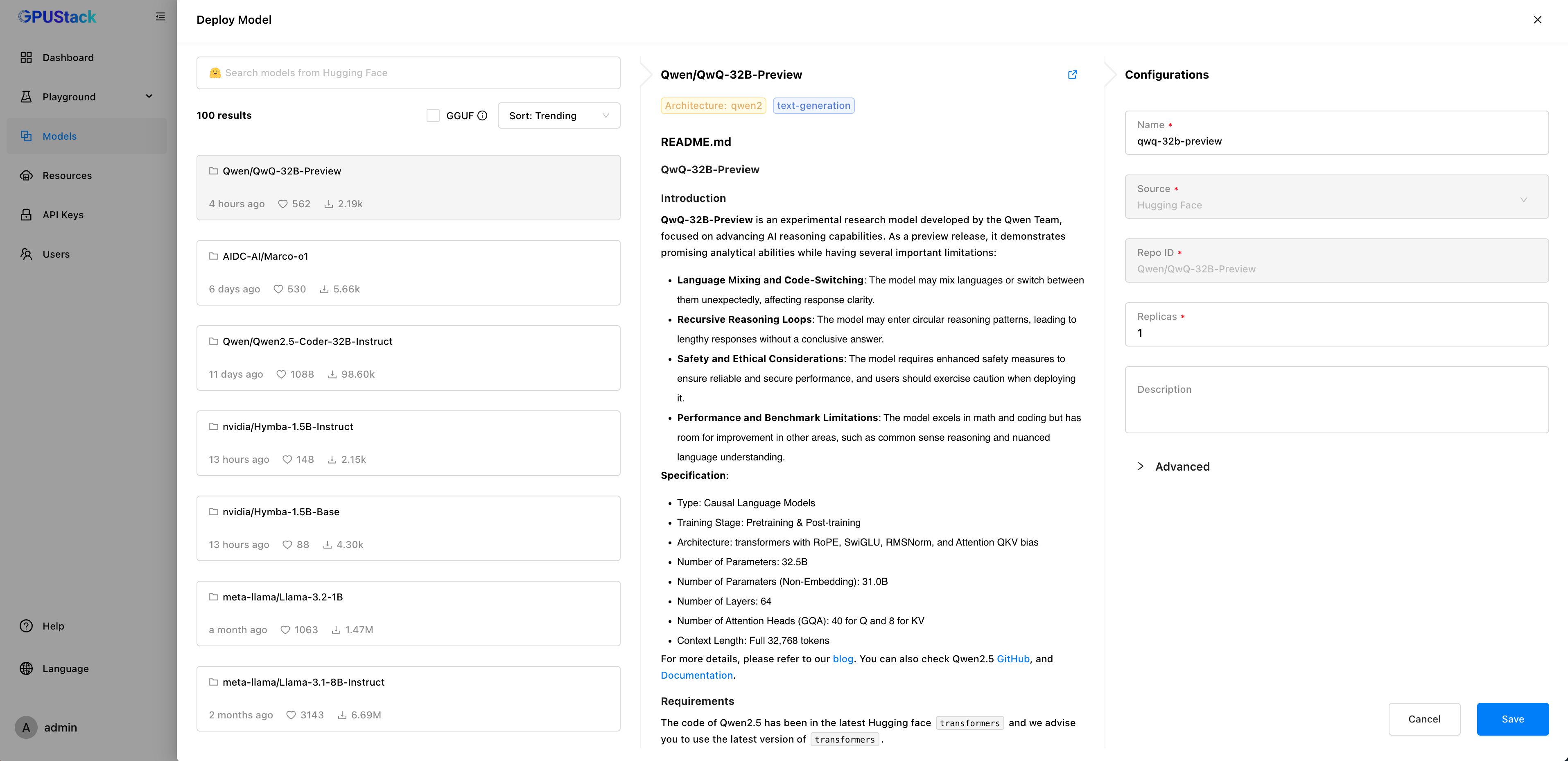
其它环境变量也可以使用该方式进行配置。
更高兼容性的 API 对接方式
在之前,一些第三方项目,如 OneAPI 和 RAGFlow,在对接 GPUStack 时,由于这些框架不支持自定义 OpenAI API 路径,需要通过额外的 Proxy(如 Nginx)将 /v1 接口代理到 GPUStack 的 /v1-openai 接口,这样的额外步骤增加了配置的复杂性。
为了提升用户的使用体验并提供更高的兼容性,GPUStack v0.4 版本将多个 OpenAI 接口的路径从 /v1-openai 别名到 /v1。因此,像 OneAPI 和 RAGFlow 等不支持自定义路径的框架,现在可以直接使用 /v1 路径的 OpenAI API 对接 GPUStack,无需再配置额外的代理步骤。
支持 PostgreSQL 数据库
之前,GPUStack 使用 SQLite 进行数据存储,这使其更适合轻量级和边缘部署,能够快速启用 GPUStack。为了更好地支持生产环境部署、第三方数据采集和数据集成,GPUStack 现在提供了将数据存储到 PostgreSQL 数据库的选项。
在安装 GPUStack 时,可以使用 --database-url 参数来指定 PostgreSQL 数据库的连接地址,例如:
curl -sfL https://get.gpustack.ai | sh -s - --database-url "postgresql://username:password@host:port/database_name"
GPUStack 将使用指定的 PostgreSQL 数据库来存储数据,提供更强的数据处理能力和更高的可扩展性。
适配更多操作系统
GPUStack v0.4 版本提供了多个分发版本的容器镜像,包括 CUDA、NPU(CANN)、MUSA、CPU 等。通过容器化方式运行,GPUStack 可以运行在一些遗留的操作系统中,例如 Ubuntu 18.04 以及其他一些 glibc 版本低于 2.29 的操作系统,包括各种国产操作系统。
我们正在持续扩展 GPUStack 的支持范围,目前正在按计划推进对 AMD GPU 和 海光 DCU 等硬件的支持工作。
GPUStack 当前依赖 Pyhon >= 3.10,若主机的 Python 版本低于 3.10,建议使用 Conda 创建符合版本要求的 Python 环境。
其他特性和修复
GPUStack v0.4.0 版本针对用户反馈的问题进行了大量改进和修复,包括:
• 优化部署模型的状态显示,提供具体的原因信息。
• 修复了高网络延迟情况下,访问 Hugging Face 和 ModelScope 模型仓库时出现的加载超时问题。
• 改进了大日志量下模型日志的显示,提升了查看体验。
• 提供了重置管理员密码的指令 gpustack reset-admin-password
等等。这些改进增强了系统的易用性和稳定性,进一步改善了用户的使用体验。
其他增强和修复请查看完整变更日志:
https://github.com/gpustack/gpustack/releases/tag/v0.4.0
加入社区
想要了解更多关于 GPUStack 的信息,可以访问我们的网站:https://gpustack.ai。
如果在使用过程中遇到任何问题,或者对 GPUStack 有任何建议,欢迎随时加入我们的 Discord 社区:[ https://discord.gg/VXYJzuaqwD ],也可以 添加 GPUStack 微信小助手(微信号:GPUStack)加入 GPUStack 微信交流群,获得 GPUStack 团队的技术支持,或与社区爱好者共同探讨交流。
我们正在快速迭代 GPUStack 项目,欢迎在体验 GPUStack 之前,在我们的 GitHub 仓库 gpustack/gpustack 上点亮⭐️关注我们,及时接收 GPUStack 未来的新版本通知。我们非常欢迎大家一起参与到这个开源项目中,为开源贡献力量!
如果觉得对你有帮助,欢迎点赞、转发、关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号