制作并量化GGUF模型上传到HuggingFace和ModelScope
 使用 llama.cpp 制作并量化 GGUF 模型,并将模型上传到 HuggingFace 和 ModelScope 模型仓库
使用 llama.cpp 制作并量化 GGUF 模型,并将模型上传到 HuggingFace 和 ModelScope 模型仓库
llama.cpp 是 Ollama、LMStudio 和其他很多热门项目的底层实现,也是 GPUStack 所支持的推理引擎之一,它提供了 GGUF 模型文件格式。GGUF (General Gaussian U-Net Format) 是一种用于存储模型以进行推理的文件格式,旨在针对推理进行优化,可以快速加载和运行模型。
llama.cpp 还支持量化模型,在保持较高的模型精度的同时,减少模型的存储和计算需求,使大模型能够在桌面端、嵌入式设备和资源受限的环境中高效部署,并提高推理速度。
今天带来一篇介绍如何制作并量化 GGUF 模型,将模型上传到 HuggingFace 和 ModelScope 模型仓库的操作教程。
注册与配置 HuggingFace 和 ModelScope
- 注册 HuggingFace
访问 https://huggingface.co/join 注册 HuggingFace 账号(需要某上网条件)
- 配置 HuggingFace SSH 公钥
将本地环境的 SSH 公钥添加到 HuggingFace,查看本地环境的 SSH 公钥(如果没有可以用 ssh-keygen -t rsa -b 4096 命令生成):
cat ~/.ssh/id_rsa.pub
在 HuggingFace 的右上角点击头像,选择 Settings - SSH and GPG Keys,添加上面的公钥,用于后面上传模型时的认证。
- 注册 ModelScope
访问 https://www.modelscope.cn/register?back=%2Fhome 注册 ModelScope 账号
- 获取 ModelScope Token
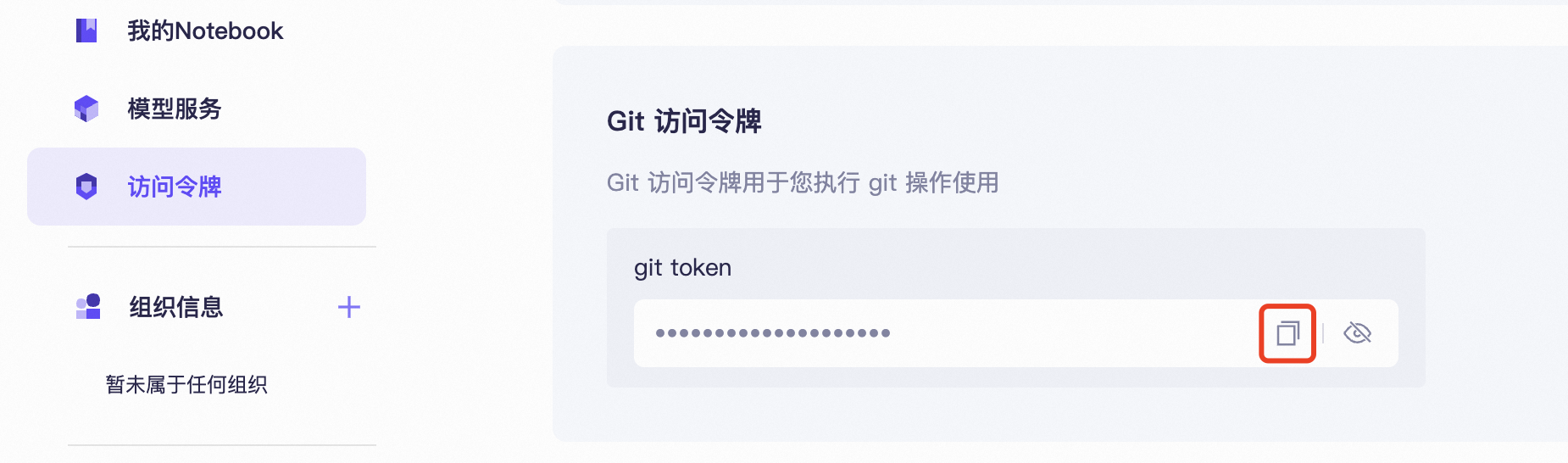
访问 https://www.modelscope.cn/my/myaccesstoken,将 Git 访问令牌复制保存,用于后面上传模型时的认证。
准备 llama.cpp 环境
创建并激活 Conda 环境(没有安装的参考 Miniconda 安装:https://docs.anaconda.com/miniconda/):
conda create -n llama-cpp python=3.12 -y
conda activate llama-cpp
which python
pip -V
克隆 llama.cpp 的最新分支代码,编译量化所需的二进制文件:
cd ~
git clone -b b4034 https://github.com/ggerganov/llama.cpp.git
cd llama.cpp/
pip install -r requirements.txt
brew install cmake
make

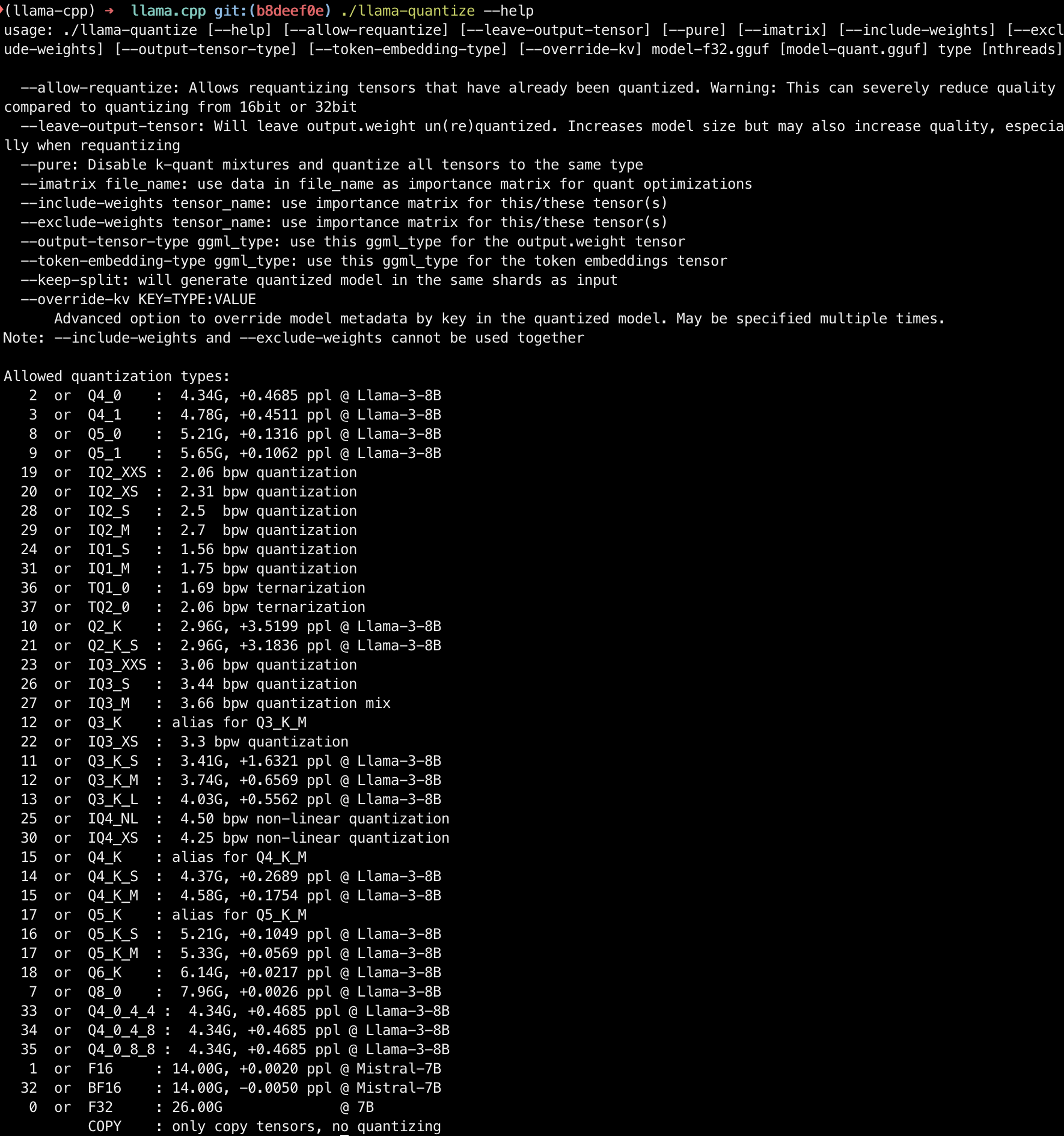
编译完成后,可以运行以下命令确认量化所需要的二进制文件 llama-quantize 是否可用:
./llama-quantize --help
下载原始模型
下载需要转换为 GGUF 格式并量化的原始模型。
从 HuggingFace 下载模型,通过 HuggingFace 提供的 huggingface-cli 命令下载,首先安装依赖:
pip install -U huggingface_hub
国内网络配置下载镜像源:
export HF_ENDPOINT=https://hf-mirror.com
这里下载 meta-llama/Llama-3.2-3B-Instruct 模型,该模型是 Gated model,需要在 HuggingFace 填写申请并确认获得访问授权:
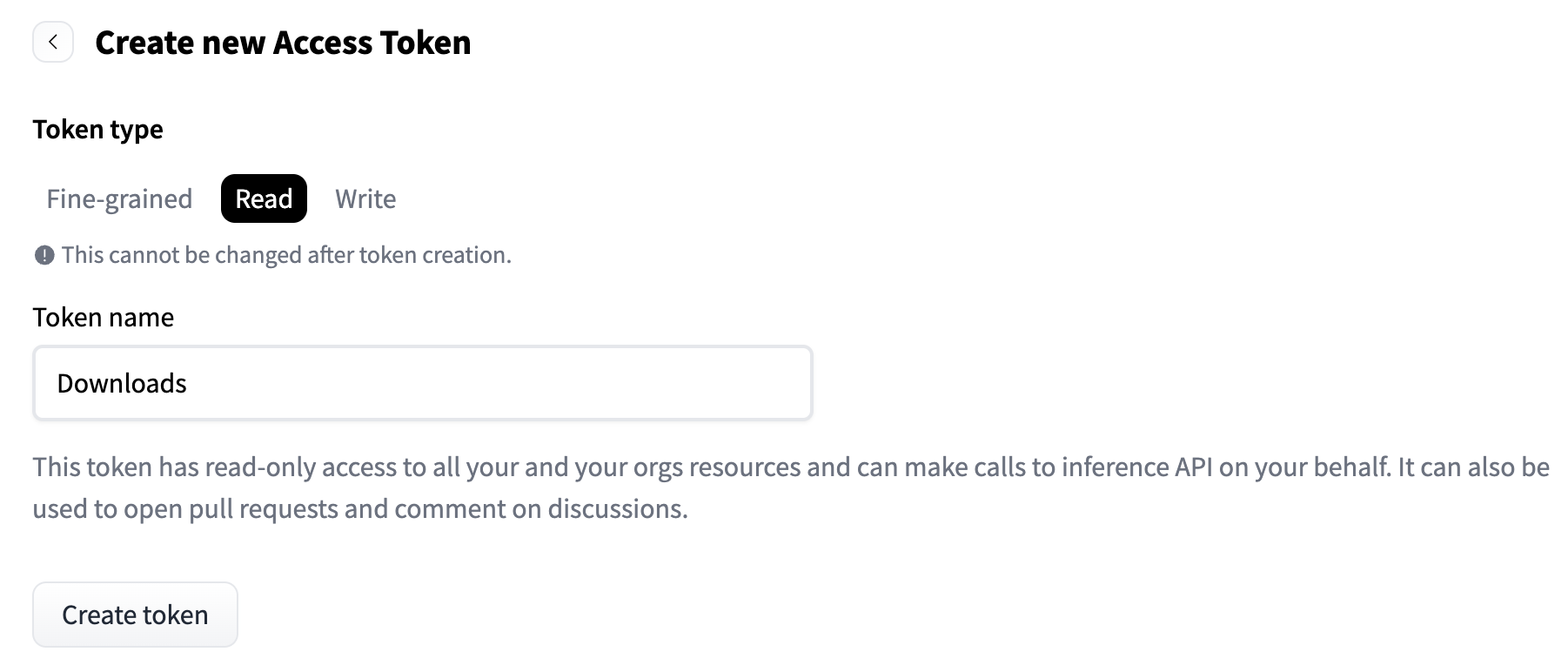
在 HuggingFace 的右上角点击头像,选择 Access Tokens,创建一个 Read 权限的 Token,保存下来:
下载 meta-llama/Llama-3.2-3B-Instruct 模型,--local-dir 指定保存到当前目录,--token 指定上面创建的访问 Token:
mkdir ~/huggingface.co
cd ~/huggingface.co/
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --local-dir Llama-3.2-3B-Instruct --token hf_abcdefghijklmnopqrstuvwxyz
转换为 GGUF 格式与量化模型
创建 GGUF 格式与量化模型的脚本:
cd ~/huggingface.co/
vim quantize.sh
填入以下脚本内容,并把 llama.cpp 和 huggingface.co 的目录路径修改为当前环境的实际路径,需要为绝对路径,将 d 变量中的 gpustack 修改为 HuggingFace 用户名:
#!/usr/bin/env bash
llama_cpp="/Users/gpustack/llama.cpp"
b="/Users/gpustack/huggingface.co"
export PATH="$PATH:${llama_cpp}"
s="$1"
n="$(echo "${s}" | cut -d'/' -f2)"
d="gpustack/${n}-GGUF"
# prepare
mkdir -p ${b}/${d} 1>/dev/null 2>&1
pushd ${b}/${d} 1>/dev/null 2>&1
git init . 1>/dev/null 2>&1
if [[ ! -f .gitattributes ]]; then
cp -f ${b}/${s}/.gitattributes . 1>/dev/null 2>&1 || true
echo "*.gguf filter=lfs diff=lfs merge=lfs -text" >> .gitattributes
fi
if [[ ! -d assets ]]; then
cp -rf ${b}/${s}/assets . 1>/dev/null 2>&1 || true
fi
if [[ ! -d images ]]; then
cp -rf ${b}/${s}/images . 1>/dev/null 2>&1 || true
fi
if [[ ! -d imgs ]]; then
cp -rf ${b}/${s}/imgs . 1>/dev/null 2>&1 || true
fi
if [[ ! -f README.md ]]; then
cp -f ${b}/${s}/README.md . 1>/dev/null 2>&1 || true
fi
set -e
pushd ${llama_cpp} 1>/dev/null 2>&1
# convert
[[ -f venv/bin/activate ]] && source venv/bin/activate
echo "#### convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf"
python3 convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf
# quantize
qs=(
"Q8_0"
"Q6_K"
"Q5_K_M"
"Q5_0"
"Q4_K_M"
"Q4_0"
"Q3_K"
"Q2_K"
)
for q in "${qs[@]}"; do
echo "#### llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q}"
llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q}
ls -lth ${b}/${d}
sleep 3
done
popd 1>/dev/null 2>&1
set +e
开始将模型转换为 FP16 精度的 GGUF 模型,并分别用 Q8_0、Q6_K、Q5_K_M、Q5_0、Q4_K_M、Q4_0、Q3_K、Q2_K 方法来量化模型:
bash quantize.sh Llama-3.2-3B-Instruct
脚本执行完后,确认成功转换为 FP16 精度的 GGUF 模型和量化后的 GGUF 模型:
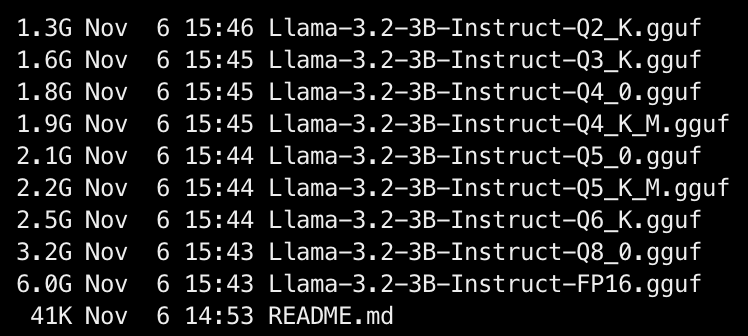
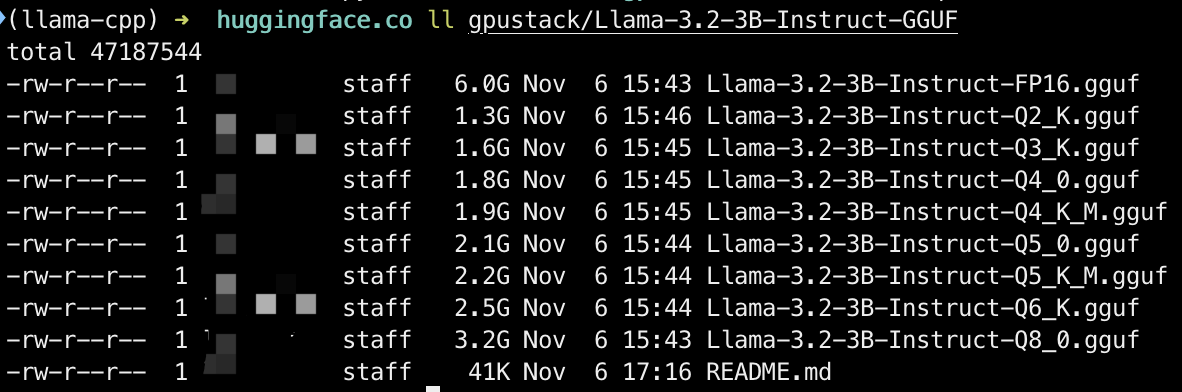
模型被存储在对应用户名的目录下:
ll gpustack/Llama-3.2-3B-Instruct-GGUF/
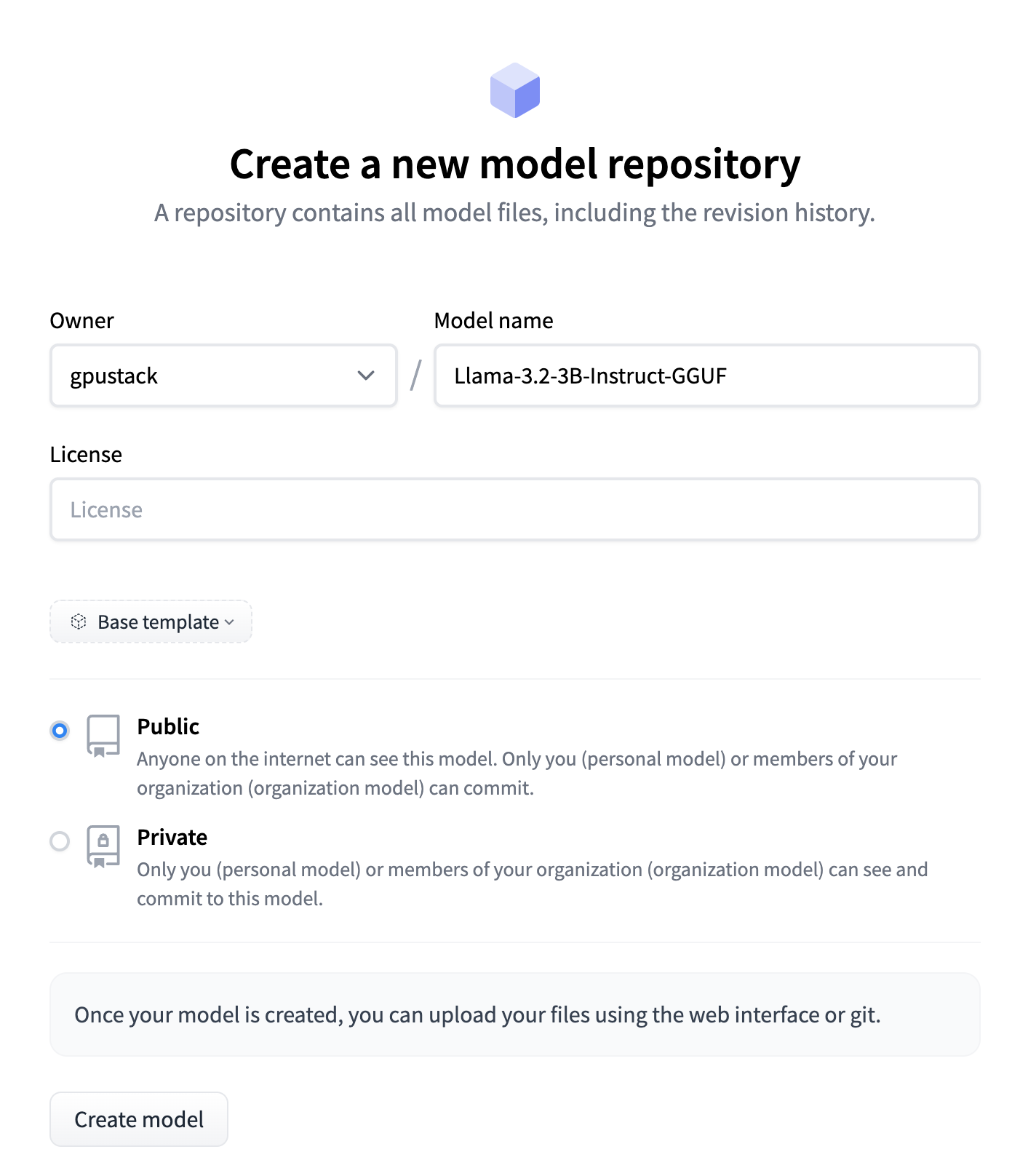
上传模型到 HuggingFace
在 HuggingFace 右上角点击头像,选择 New Model 创建同名的模型仓库,格式为 原始模型名-GGUF:
更新模型的 README:
cd ~/huggingface.co/gpustack/Llama-3.2-3B-Instruct-GGUF
vim README.md
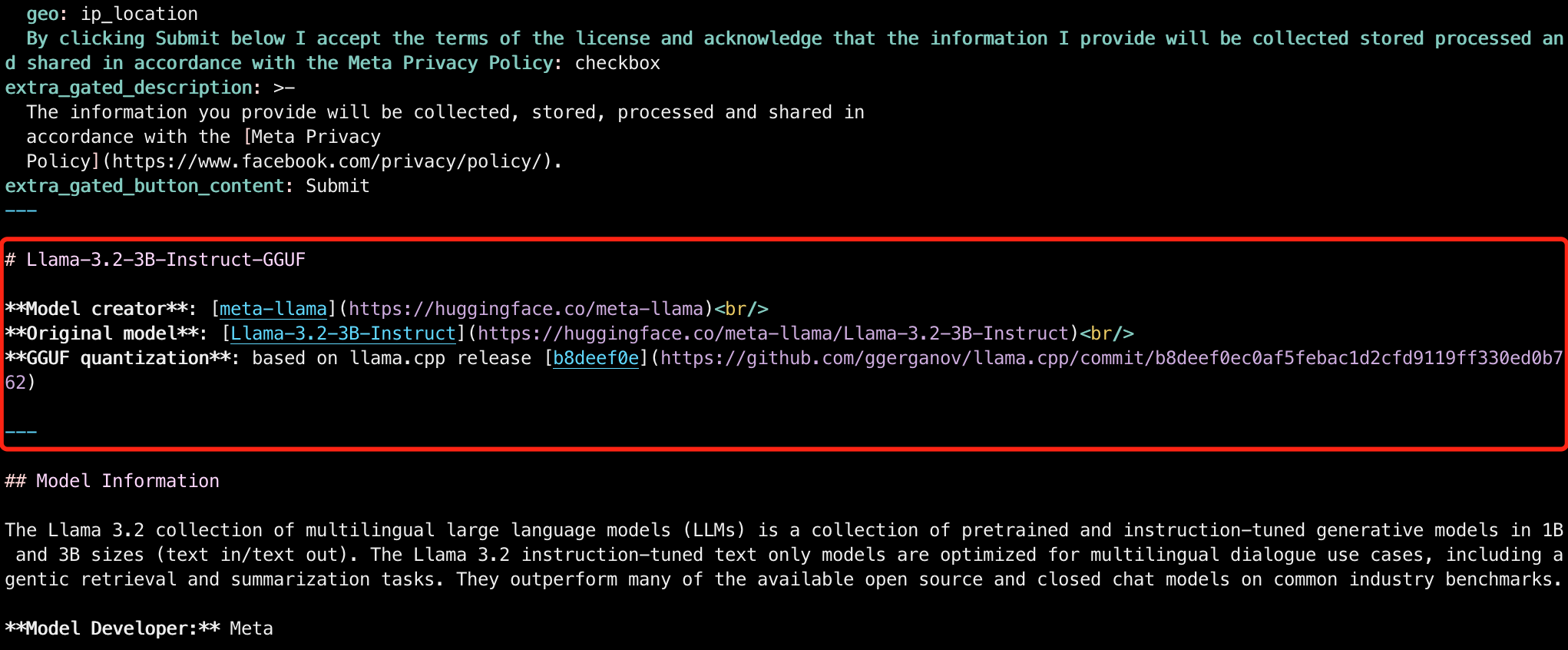
为了维护性,在开头的元数据之后,记录原始模型和 llama.cpp 的分支代码 Commit 信息,注意按照原始模型的信息和llama.cpp 的分支代码 Commit 信息更改:
# Llama-3.2-3B-Instruct-GGUF
**Model creator**: [meta-llama](https://huggingface.co/meta-llama)<br/>
**Original model**: [Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)<br/>
**GGUF quantization**: based on llama.cpp release [b8deef0e](https://github.com/ggerganov/llama.cpp/commit/b8deef0ec0af5febac1d2cfd9119ff330ed0b762)
---
准备上传,安装 Git LFS 用于管理大文件的上传:
brew install git-lfs
添加远程仓库:
git remote add origin git@hf.co:gpustack/Llama-3.2-3B-Instruct-GGUF
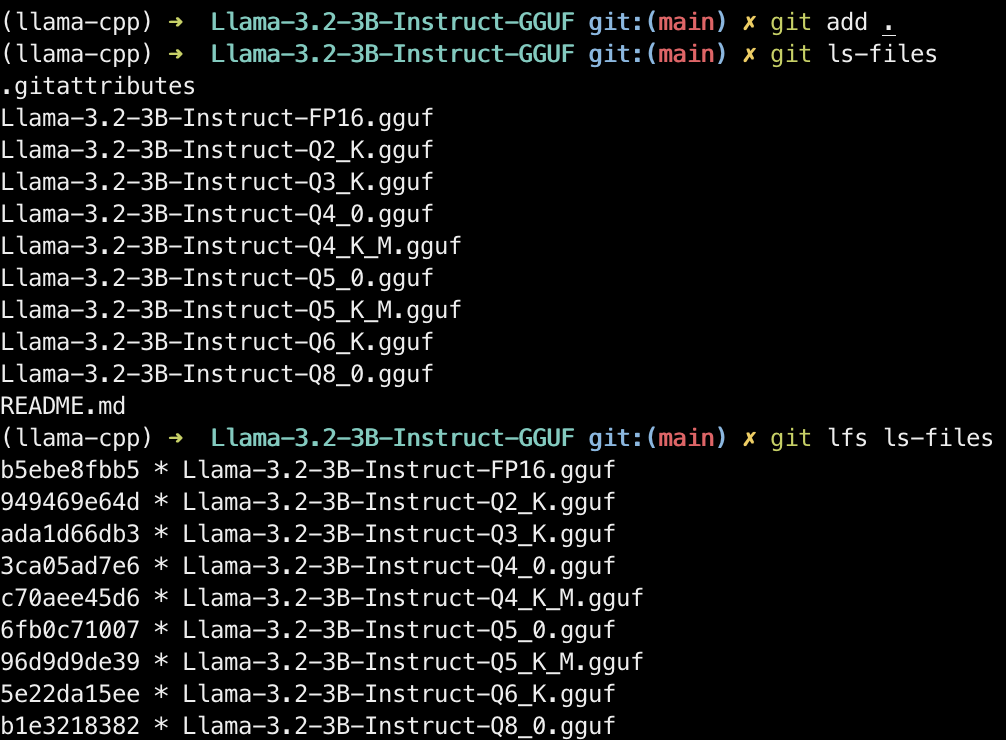
添加文件,并通过 git ls-files 确认提交的文件, git lfs ls-files 确认所有 .gguf 文件被 Git LFS 管理上传:
git add .
git ls-files
git lfs ls-files
上传超过 5GB 大小的文件到 HuggingFace 需开启大文件上传,在命令行登录 HuggingFace,输入上面下载模型章节创建的 Token:
huggingface-cli login
为当前目录开启大文件上传:
huggingface-cli lfs-enable-largefiles .

将模型上传到 HuggingFace 仓库:
git commit -m "feat: first commit" --signoff
git push origin main -f
上传完成后,在 HuggingFace 确认模型文件成功上传。
上传模型到 ModelScope
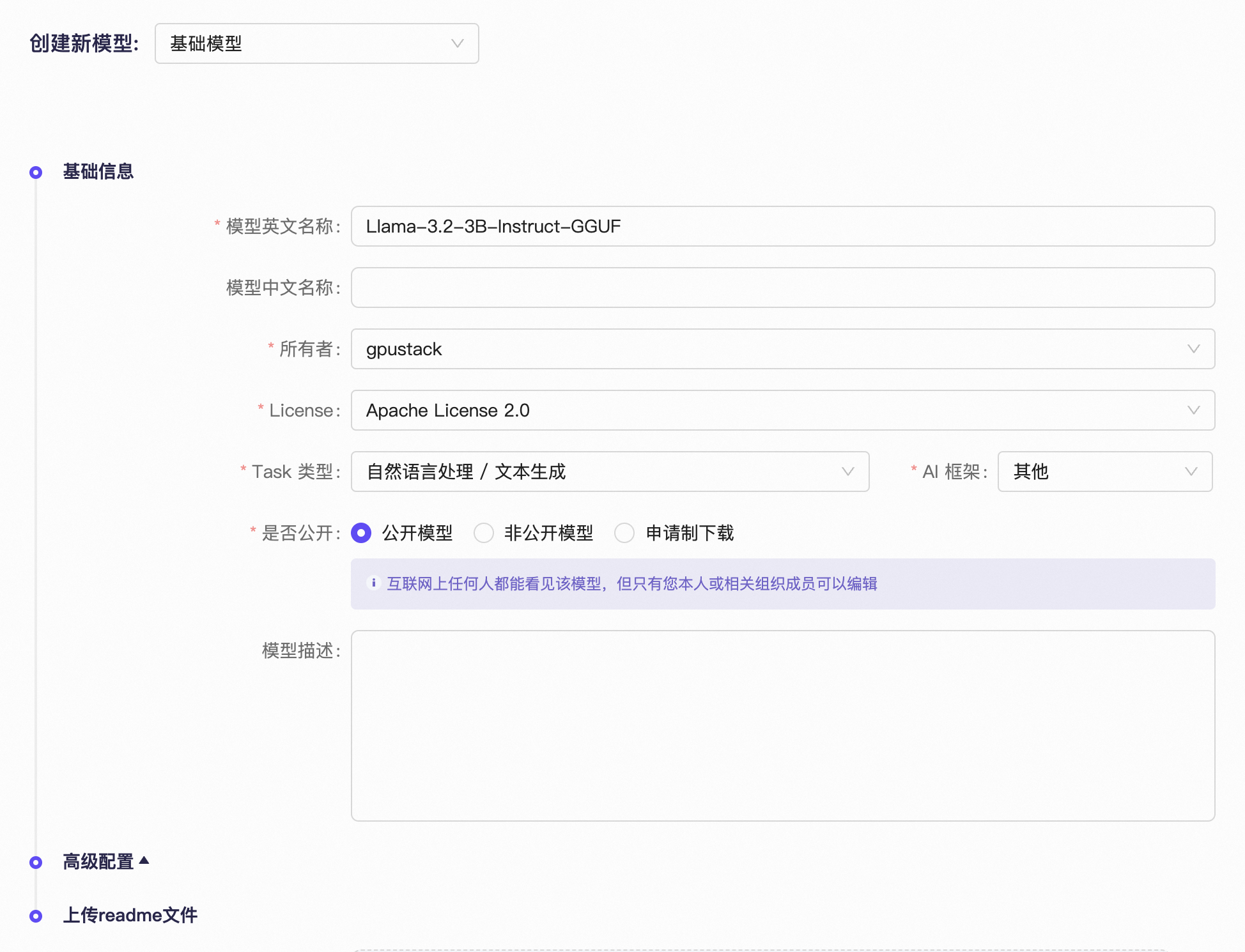
在 ModelScope 右上角点击头像,选择 创建模型 创建同名的模型仓库,格式为 原始模型名-GGUF,并填写 License、模型类型、AI 框架、是否公开模型等其他配置:
上传本地仓库的 README.md 文件并创建:

添加远程仓库,需要使用本文最开始获得的 ModelScope Git 访问令牌提供上传模型时的认证:
git remote add modelscope https://oauth2:xxxxxxxxxxxxxxxxxxxx@www.modelscope.cn/gpustack/Llama-3.2-3B-Instruct-GGUF.git
获取远端仓库已存在的文件:
git fetch modelscope master
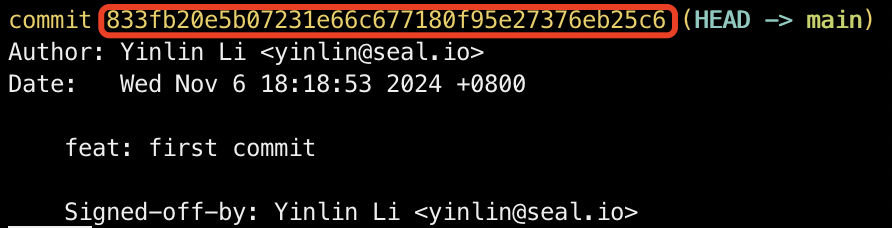
由于 ModelScope 使用 master 分支而非 main 分支,需要切换到 master 分支并通过 cherry-pick 将main 下的文件移到 master 分支,先查看并记下当前的 Commit ID:
git log
切换到 master 分支,并通过 main 分支的 Commit ID 将main 分支下的文件移到 master 分支:
git checkout FETCH_HEAD -b master
git cherry-pick -n 833fb20e5b07231e66c677180f95e27376eb25c6
修改冲突文件,解决冲突(可以用原始模型的 .gitattributes 合并 *.gguf filter=lfs diff=lfs merge=lfs -text,参考 quantize.sh 脚本相关逻辑 ):
vim .gitattributes
添加文件,并通过 git ls-files 确认提交的文件, git lfs ls-files 确认所有 .gguf 文件被 Git LFS 管理上传:
git add .
git ls-files
git lfs ls-files
将模型上传到 ModelScope 仓库:
git commit -m "feat: first commit" --signoff
git push modelscope master -f
上传完成后,在 ModelScope 确认模型文件成功上传。
总结
以上为使用 llama.cpp 制作并量化 GGUF 模型,并将模型上传到 HuggingFace 和 ModelScope 模型仓库的操作教程。
llama.cpp 的灵活性和高效性使得其成为资源有限场景下模型推理的理想选择,应用十分广泛,GGUF 是 llama.cpp 运行模型所需的模型文件格式,希望以上教程能对如何管理 GGUF 模型文件有所帮助。
如果觉得写得不错,欢迎点赞、转发、关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号