
在昇腾Ascend 910B上运行Qwen2.5推理
 使用 GPUStack 在昇腾 Ascend 910B 上运行 Qwen2.5 全系列的推理性能表现
使用 GPUStack 在昇腾 Ascend 910B 上运行 Qwen2.5 全系列的推理性能表现
目前在国产 AI 芯片,例如昇腾 NPU 上运行大模型是一项广泛且迫切的需求,然而当前的生态还远未成熟。从底层芯片的算力性能、计算架构的算子优化,到上层推理框架对各种模型的支持及推理加速,仍有很多需要完善的地方。
今天带来一篇在昇腾 910B 上运行 Qwen 2.5 执行推理的操作实践。
配置昇腾环境
在昇腾 NPU 服务器上,确认昇腾 NPU 驱动已安装:
npu-smi info
根据架构下载对应的 CANN Toolkit 包(开发套件)和对应芯片的 Kernel 包(CANN 算子) https://www.hiascend.com/zh/software/cann/community-history:
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C19SPC703/Ascend-cann-toolkit_8.0.RC3.alpha003_linux-aarch64.run
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C19SPC703/Ascend-cann-kernels-910b_8.0.RC3.alpha003_linux-aarch64.run
安装 Toolkit,按提示操作:
sudo sed -i 's/user=true/user=false/' ~/.pip/pip.conf
sudo chmod +x Ascend-cann-toolkit_8.0.RC3.alpha003_linux-aarch64.run && sudo ./Ascend-cann-toolkit_8.0.RC3.alpha003_linux-aarch64.run --install --install-for-all
安装 Kernel,按提示操作:
sudo chmod +x Ascend-cann-kernels-910b_8.0.RC3.alpha003_linux-aarch64.run && sudo ./Ascend-cann-kernels-910b_8.0.RC3.alpha003_linux-aarch64.run --install --install-for-all
配置环境变量:
sudo echo "source /usr/local/Ascend/ascend-toolkit/set_env.sh" >> /etc/profile
source /usr/local/Ascend/ascend-toolkit/set_env.sh
昇腾环境已经配置完成,接下来准备运行 Qwen 2.5 模型的私有大模型服务平台。
安装 GPUStack
GPUStack 是一个开源的大模型即服务平台,支持 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种类型的 GPU/NPU,可以在昇腾 910B 上运行包括 Qwen 2.5 在内的各种大模型,安装步骤如下。
通过以下命令在昇腾 NPU 服务器上在线安装 GPUStack,在安装过程中需要输入 sudo 密码:
curl -sfL https://get.gpustack.ai | sh -
如果环境连接不了 GitHub,无法下载一些二进制文件,使用以下命令安装,用 --tools-download-base-url 参数指定从腾讯云对象存储下载:
curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
接下来按照脚本输出的指引,拿到登录 GPUStack 的初始密码,执行以下命令:
cat /var/lib/gpustack/initial_admin_password
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。
重新设置密码后,进入 GPUStack:
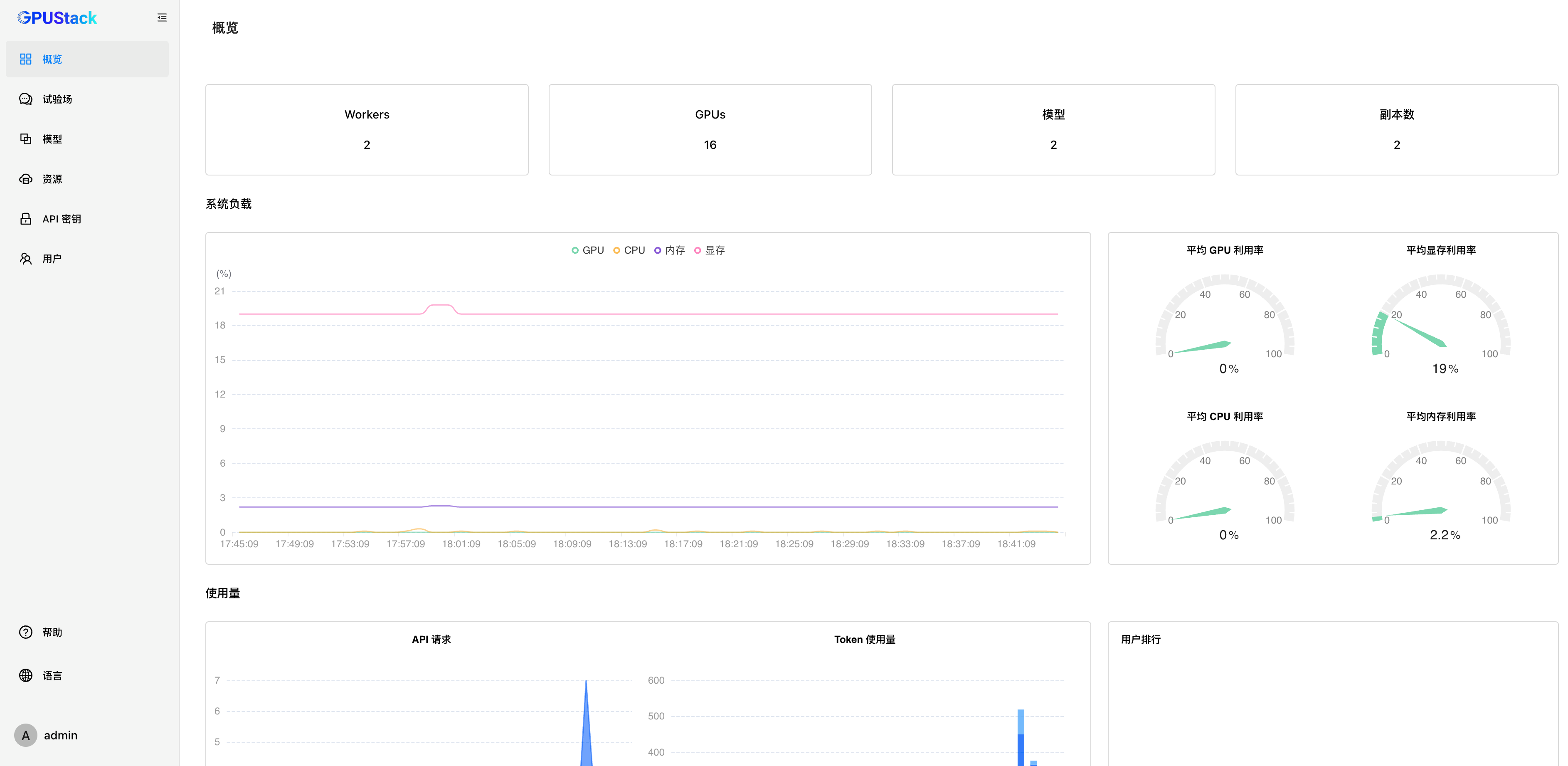
纳管昇腾 NPU 资源
GPUStack 支持纳管 Linux、Windows 和 macOS 设备的 GPU 资源,如果有多台昇腾 NPU 服务器,通过以下步骤来纳管这些 NPU 资源。
其他节点需要通过认证 Token 加入 GPUStack 集群,在 GPUStack Server 节点执行以下命令获取 Token:
cat /var/lib/gpustack/token
拿到 Token 后,在其他节点上运行以下命令添加 Worker 到 GPUStack,纳管这些节点的 NPU(将其中的 http://YOUR_IP_ADDRESS 替换为 GPUStack 访问地址,将 YOUR_TOKEN 替换为用于添加 Worker 的认证 Token):
curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
纳管的昇腾 NPU 服务器资源如下:
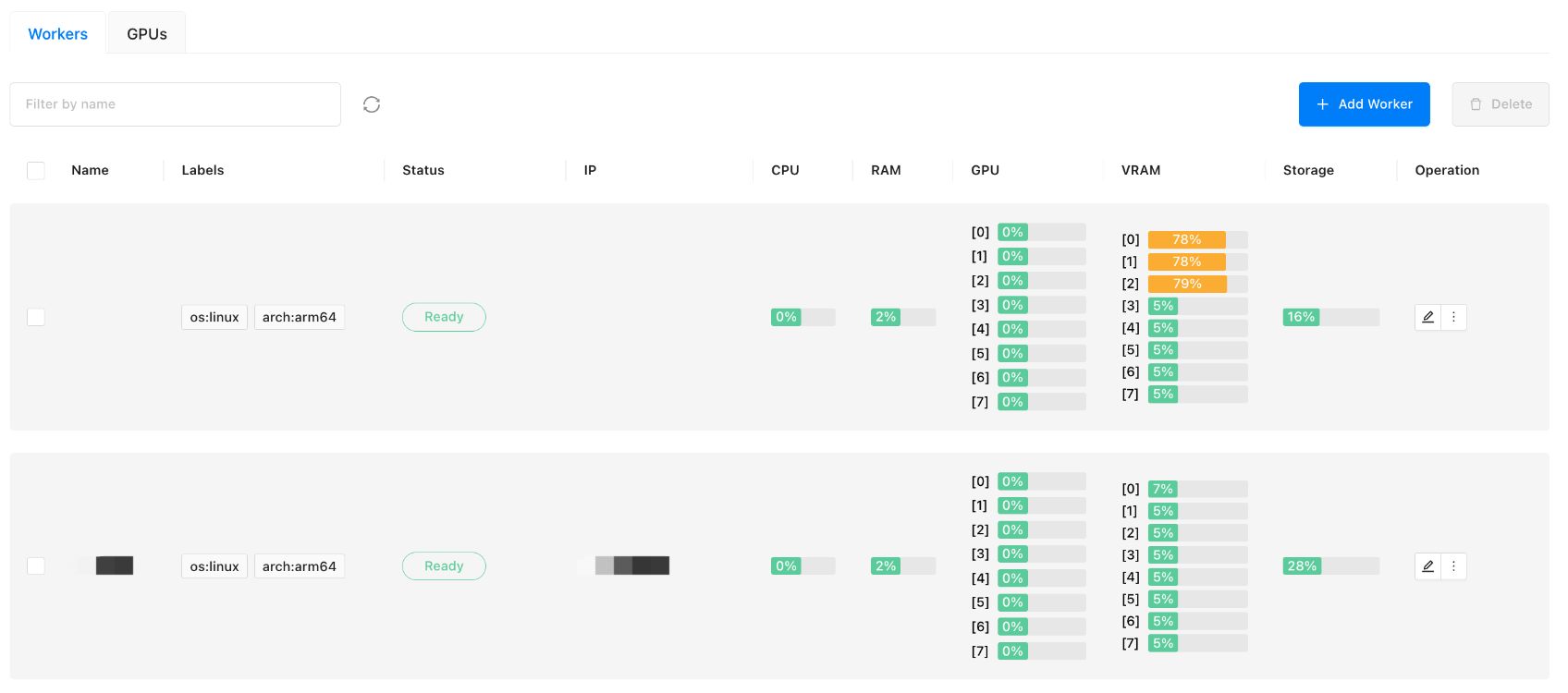
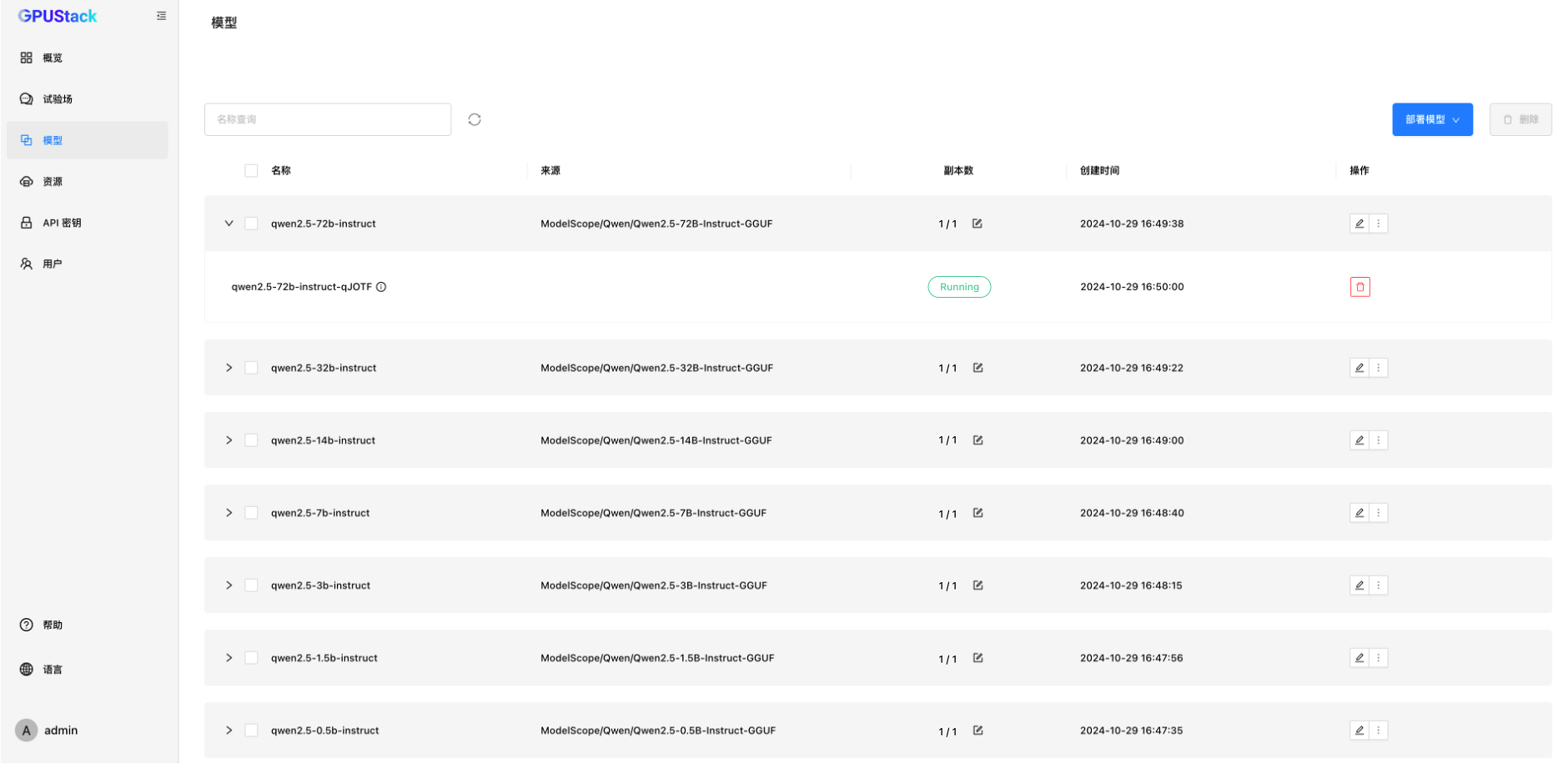
部署 Qwen 2.5 模型
在 GPUStack 的模型菜单中部署模型。GPUStack 支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型,国内网络建议从 ModelScope 部署。
GPUStack 支持 vLLM 和 llama-box 推理后端,llama-box 是 llama.cpp 的优化版本,对性能和稳定性进行了针对性的优化。目前 GPUStack 中基于 llama-box 提供对昇腾 NPU 的支持,在昇腾 NPU 上部署模型需要模型为 GGUF 格式。
从 ModelScope 部署 Qwen 2.5 的全系列模型,目前 CANN 算子的支持完整度方面还有不足,目前只能运行 FP16 精度、Q8_0 和 Q4_0 量化的模型,建议运行 FP16 精度的模型:
- Qwen2.5-0.5B-Instruct-GGUF FP16
- Qwen2.5-1.5B-Instruct-GGUF FP16
- Qwen2.5-3B-Instruct-GGUF FP16
- Qwen2.5-7B-Instruct-GGUF FP16
- Qwen2.5-14B-Instruct-GGUF FP16
- Qwen2.5-32B-Instruct-GGUF FP16
- Qwen2.5-72B-Instruct-GGUF FP16
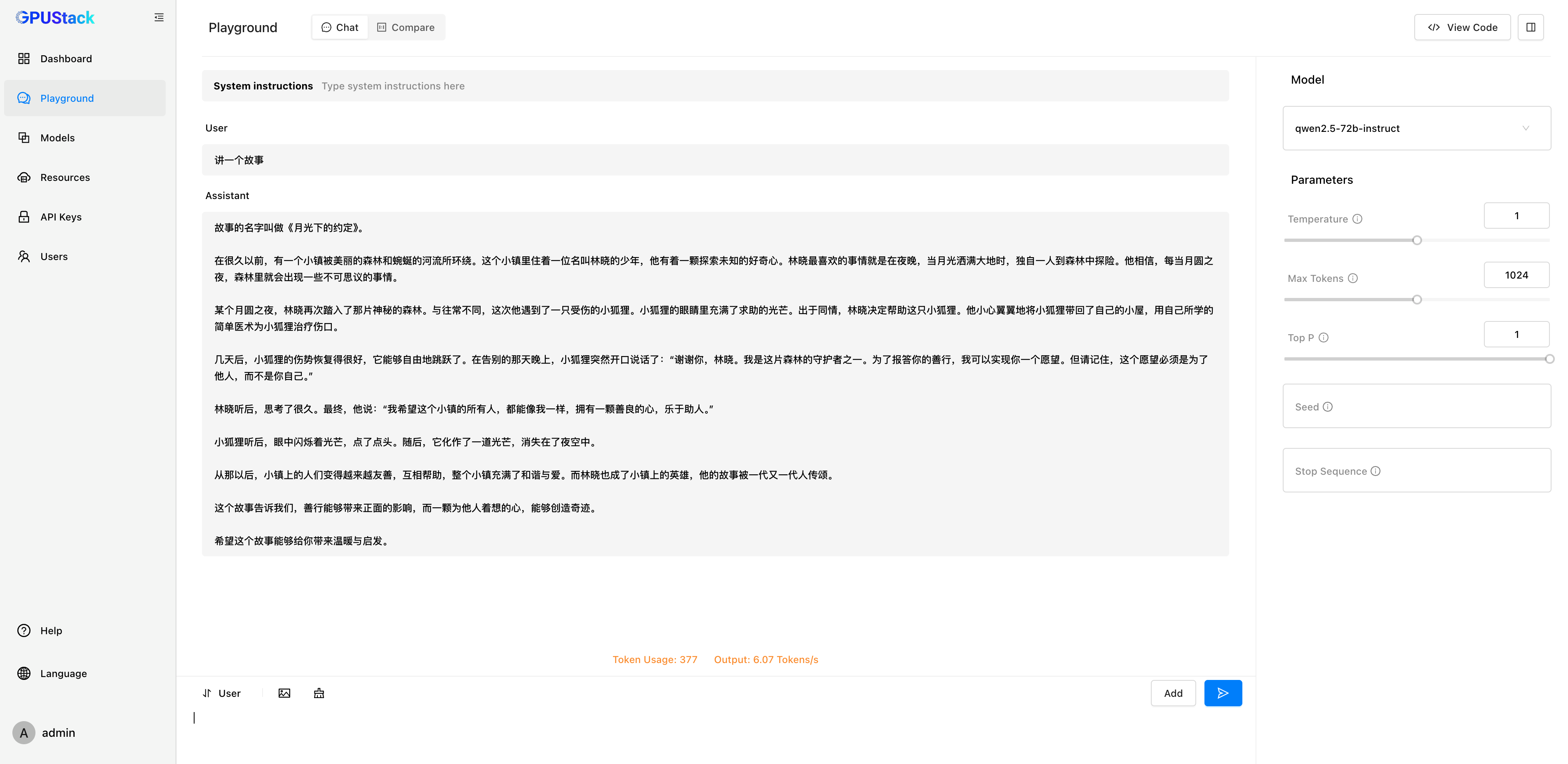
来看其中 Qwen 2.5 72B 模型的具体运行情况,Qwen 2.5 72B 被调度到 3 块 910B 上运行:

在 Dashboard 可以看到 Qwen 2.5 72B 被分配了 140.1 GiB 显存和 8.1 GiB 内存:

从 Playground 的实际测试来看,使用 llama-box 在昇腾 910B 上运行 Qwen 2.5 72B 的推理性能表现为 6 Tokens/s 左右,NPU 利用率在 10~30%左右:
以下为 Qwen 2.5 全系列模型在昇腾 910B 上的推理性能表现汇总数据,包括 Qwen2.5 0.5B、1.5B、3B 的 Q8_0 和 Q4_0 量化的推理性能数据作为对比参考:
| Model | Tokes / Second | NPU Util | NPU Mem | NPUs |
|---|---|---|---|---|
| Qwen2.5 0.5B FP16 | 42 tokens/second | Util 6~7% | Mem 7% | 单卡 |
| Qwen2.5 1.5B FP16 | 35 tokens/second | Util 11~13% | Mem 10% | 单卡 |
| Qwen2.5 3B FP16 | 29 tokens/second | Util 15~16% | Mem 15% | 单卡 |
| Qwen2.5 7B FP16 | 32 tokens/second | Util 16~21% | Mem 16% | 单卡 |
| Qwen2.5 14B FP16 | 19 tokens/second | Util 19~22% | Mem 28% | 单卡 |
| Qwen2.5 32B FP16 | 10.5 tokens/second | Util 10~45% | Mem 54% | 双卡 |
| Qwen2.5 72B FP16 | 6 tokens/second | Util 10~60% | Mem 78% | 三卡 |
| Qwen2.5 0.5B Q8_0 | 6.5 tokens/second | Util 2~5% | Mem 6% | 单卡 |
| Qwen2.5 0.5B Q4_0 | 6 tokens/second | Util 4~5% | Mem 6% | 单卡 |
| Qwen2.5 1.5B Q8_0 | 3.5 tokens/second | Util 4~11% | Mem 8% | 单卡 |
| Qwen2.5 1.5B Q4_0 | 17~18 tokens/second | Util 9~12% | Mem 7% | 单卡 |
| Qwen2.5 3B Q8_0 | 3.2 tokens/second | Util 10~15% | Mem 10% | 单卡 |
| Qwen2.5 3B Q4_0 | 14.5 tokens/second | Util 8~15% | Mem 8% | 单卡 |
对其中的 Qwen 2.5 0.5B FP16 模型进行并发测试的性能表现如下:
| CC | Tokens / Second | TP | NPU Util | NPU Mem |
|---|---|---|---|---|
| 1 | 39 tokens/second | 39 | Util 6~7% | Mem 7% |
| 2 | 38 tokens/second | 76 | Util 6~7% | Mem 7% |
| 3 | 37.66 tokens/second | 113 | Util 6~7% | Mem 7% |
| 4 | 34.25 tokens/second | 137 | Util 6~7% | Mem 7% |
| 5 | 31 tokens/second | 155 | Util 6~7% | Mem 7% |
| 6 | 28.16 tokens/second | 169 | Util 6~7% | Mem 7% |
| 7 | 27.57 tokens/second | 193 | Util 6~7% | Mem 7% |
| 8 | 26.87 tokens/second | 215 | Util 6~7% | Mem 7% |
| 9 | 26 tokens/second | 234 | Util 6~7% | Mem 7% |
| 10 | 26.9 tokens/second | 269 | Util 6~7% | Mem 7% |
| 20 | 20.3 tokens/second | 406 | Util 6~7% | Mem 8% |
| 50 | 10.34 tokens/second | 517 | Util 3~5% | Mem 8% |
| 100 | 4.17 tokens/second | 417 | Util 2~5% | Mem 9% |
从测试结果来看,目前硬件性能未得到充分发挥,CANN 算子优化方面还有可观的优化空间,推理引擎层面也还有一些可以优化的推理加速技术,也期待后续 GPUStack 的另外一个高性能推理后端 vLLM 对昇腾 NPU 的支持,提供更佳的推理性能表现。
以上为使用 GPUStack 在昇腾 910B 上运行 Qwen 2.5 推理的操作实践。GPUStack 是一个开源的大模型即服务平台,以下为 GPUStack 功能的简单介绍。
GPUStack 功能介绍
-
异构 GPU 支持:支持异构 GPU 资源,当前支持 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种类型的 GPU/NPU
-
多推理后端支持:支持 vLLM 和 llama-box (llama.cpp) 推理后端,兼顾生产性能需求与多平台兼容性需求
-
多平台支持:支持 Linux、Windows 和 macOS 平台,覆盖 amd64 和 arm64 架构
-
多模型类型支持:支持 LLM 文本模型、VLM 多模态模型、Embedding 文本嵌入模型 和 Reranker 重排序模型等各种类型的模型
-
多模型仓库支持:支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型
-
丰富的自动/手动调度策略:支持紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等各种调度策略
-
分布式推理:如果单个 GPU 无法运行较大的模型,可以通过 GPUStack 的分布式推理功能,自动将模型运行在跨主机的多个 GPU 上
-
CPU 推理:如果没有 GPU 或 GPU 资源不足,GPUStack 可以用 CPU 资源来运行大模型,支持 GPU&CPU 混合推理和纯 CPU 推理两种 CPU 推理模式
-
多模型对比:GPUStack 在 Playground 中提供了多模型对比视图,可以同时对比多个模型的问答内容和性能数据,以评估不同模型、不同权重、不同 Prompt 参数、不同量化、不同 GPU、不同推理后端的模型 Serving 效果
-
GPU 和 LLM 观测指标:提供全面的性能、利用率、状态监控和使用数据指标,以评估 GPU 和 LLM 的利用情况
GPUStack 作为一个开源项目,只需要非常简单的安装设置,就可以开箱即用地构建企业私有大模型即服务平台。
总结
以上为使用 GPUStack 在昇腾 910B 上运行 Qwen 2.5 的操作实践,项目的开源地址为:https://github.com/gpustack/gpustack。
期待后续国产 AI 芯片在算子优化上更加完善,同时也期待上层推理引擎对国产 AI 芯片的更多支持,充分发挥国产 AI 芯片的硬件性能,提供更佳的推理性能表现。
如果觉得写得不错,欢迎点赞、转发、关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号