MySQL InnoDB“一篇就够”
一、MySQL架构
1、架构及设计模式

连接器:用于server与client之间的通信
缓存:对于一些查询命令进行缓存,以提高性能(8.0版本后删除,因为实际作用不大)
分析器:分析sql语句的语法、词法、句法
优化器:对sql语句的执行顺序、执行过程、使用索引等方面进行优化
执行器:校验用户权限,作出执行计划,调用存储引擎。在没有索引的情况下,会遍历所有的行
存储引擎:把执行计划转换成对文件系统的读写,数据落盘,实现持久化存储。
总体顺序是:分析→优化→执行→落盘
采用了多种设计模式:分层架构,微核架构,职责链
2、MySQL的TCP报文
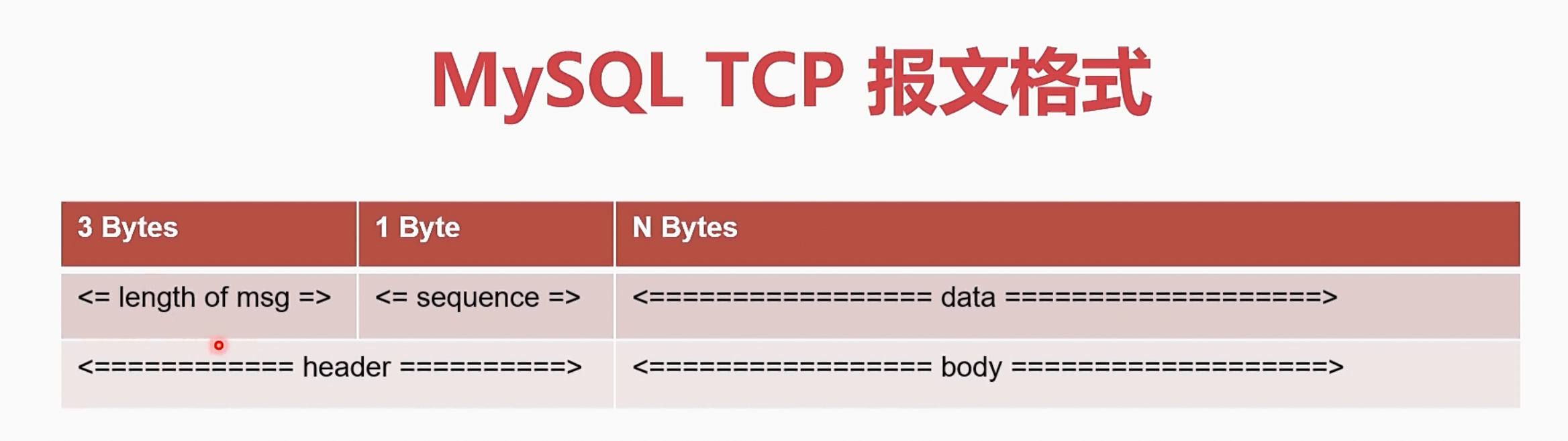
- 消息头:3字节的报文长度域,1字节的序号
- 消息体:1字节的指令,其余全书参数
- 指令举例:(0x02)切换数据库、(0x03)查询
3、常见MySQL存储引擎
①MyIsam
- MySQL 5.5之前默认的存储引擎
- 数据插入速度快
- 空间利用率高
- 不支持事务、外键
②Innodb
- MySQL 5.5之后的默认存储引擎
- 支持事务、外键
- 支持崩溃修复和并发控制
③Archive
- 对数据进行压缩,空间利用率高
- 插入速度快
- 不支持索引,查询性能差(因为查询只能通过全表遍历)
④Memory
- 所有数据都存储在内存中,速度快,类似Redis。
- 数据安全性差,崩溃后无法修复
- 对机器内存要求高
二、SQL语句的执行
三、innodb数据表
1、常用查找算法
①线性查找
- 容易实现
- 时间开销恒定为O(n)
- 当数据量大时,开销非常大,因此一般不使用
②二叉查找树
- 时间复杂度为O(log n)
- 当高度太大时,会退化为线性查找
③AVL树
- 增删查改时,通过旋转,使整个树平衡
- 因此,不会退化为线性查找
- 只能查找单个数据,如果要查找的数据范围太大,也会退化为线性查找
④B树

- 是线性表和树的组合
- 通过一个节点存储多个数据,降低了树的高度
- 不需要旋转就可以保证平衡
- 支持范围查找,但是,某些特殊情况,例如图中查询 0001至0006,仍要多次查找,不能一次查询得出所有数据
⑤B+树
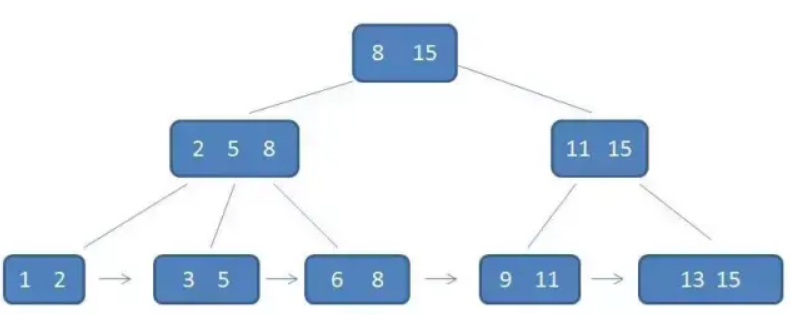
- 是对B树的改进
- 所有数据都存储在叶子结点
- 所有的叶子结点形成一个线性表
- 对范围查询有了更高的效率
2、B+树索引
- InnoDB使用B+树作为索引的数据结构
- 通常情况下,B+树的高度为2 - 4,时间复杂度为O(h + d),h是高度,d是每个叶子节点存储数据的最大个数
- InnoDB分为主索引(聚簇索引)和辅助索引
- 在同层的B+树的节点之间,使用双向链表
- 在B+树节点内的数据之间,使用单向链表
3、数据即索引
①主索引
- 根据主键构造的B+树
- 叶子节点直接存放行数据,而不是指针(因此索引即数据)
- InnoDB的主索引是一个索引组织表(由索引组织起来的表),数据也是B+树的一部分
②辅助索引
- 一张表可以有多个辅助索引
- 索引B+树的叶子节点不包含行数据,只记录行数据的主键
- 查到主键后,需要再回到主索引查询,取出行数据,这个操作叫做“回表”
4、底层数据格式
①逻辑结构

②表空间
- 表空间指数据表在硬盘的存储空间
- 默认情况下,所有表都存储在共享表空间
- 每个表的数据也可以放在独占的表空间(即ibd文件)
③段
- 叶子节点段:数据段
- 非叶子节点段:索引段
- 段由存储引擎管理
④区
- 区是由连续的页组成的空间,大小为1MB
- 通常InnoDB一次会从磁盘申请多个区,避免频繁地进行系统调用
- 一个区有64个页
⑤页
- InnoDB读写硬盘的最小逻辑单位,默认为16KB
- 一个页就是一个B+树节点
- 页是根据硬盘的最小存储单元来决定的。HDD为512B,SSD通常为4K(SSD可以由自己格式化设置)。一个页最好不要小于最小存储单元。
5、变长列
①变长列的数据类型
- 长度不固定的数据类型:VARCHAR、VARBINARY、BLOB、TEXT
2、占用空间大于768B的不变成类型CHAR
3、变长编码下的CHAR(如UTF-8)
②行溢出数据
当变长列过程时,会产生行溢出,因为InnoDB中,数据字段的长度是有限的。当字段过长时,就会使用行溢出机制,把超长字段放入单独开辟的数据页
6、行存储格式

变长字段长度表:用于记录变长字段的长度(固定长度的字段之间存储在表的属性中,而不做行中)
NULL标志位:用于标记null的行,因为null的字段,实际上是不会存储任何数据的
Header:记录列数量、下一行记录的指针等信息
RowID:当没有可用的主键时,使用RowID作为隐式主键
TxID:事务ID
Roll Pointer:回滚指针
字段:数据小于等于40B则直接存储,大于40B则溢出,则存储数据所在的空间的指针
7、联合索引
- 使用两个或以上字段生成的索引
- 联合索引可以加速最左前缀的查询
- 联合索引可以代替最左前缀的单独索引
- 使用联合索引的规则:查询字段的左边前缀索引必须要有,否则无法走索引
四、查询
所需MySQL指令
- explain 用于查看SQL语句的执行计划,使用:
explain + 要执行的SQL语句
具体字段的内容,可以看:MySQL explain详解,笔者就不详细列出来了,毕竟本文主要内容是innodb。 - 查看索引的信息,包括索引的基数
show index from <table_name> - force index 强制使用索引。使用方法:
select <字段> from <表> force index(<索引>) where ………… - 优化索引
analyze table <表名> - rand() 输出一个0 - 1之间的浮点数。可以通过 select rand()查看
1、WHERE
①覆盖索引
- 覆盖索引:执行语句从执行到返回结果,均使用同一个索引,可以有效减少回表。
- 如果查询时,使用不止一个索引,则不是覆盖索引。
- 可以通过优化SQL语句或优化联合索引,来实现覆盖索引。(例如联合索引选取的字段,还有字段的先后顺序等)
②如何确定使用哪一条索引
- MySQL选取索引时,会参考索引的基数(cardinality),索引基数反映索引的好坏
- 索引的基数是MySQL估算的,反映这个字段有多少中取值,基数越大,越容易被选取,因为索引的基数,也是索引的区分度的一种体现
- 索引的基数的计算:选取出几个页算出取值的平均值,再乘以页数,就等于基数。
③不走索引时
- 使用force index,强制使用指定的索引
④优化索引
- 使用analyze table,可以重写统计索引信息,同时重新计算索引基数
2、COUNT
count函数作用
- 用于统计结果集中不为null的数据个数
count函数执行逻辑
- 存储引擎查询出结果集
- server层逐个判断数据是否为null,不为null则加1
count(非索引字段)
- count统计非索引字段时,需要由server层统计每个数据是否为null
- 无法走索引,全表扫描,速度最慢
count(索引字段)
- 可以使用覆盖索引,但仍需server层统计每个数据是否为null
count(1)
- 只扫描索引树,不会进行行数据解析,速度更快
- 但仍需server层去判断“1”是否为null
count(*)
- count(*)用于返回数据表的行数
- MyIsam中,count(*)直接返回数据库中记录的数据表行数
- 虽然InnoDB数据库中不记录数据表的行数,但是MySQL对count(*)进行了优化,直接返回索引树中数据的个数
- 不需进行null判断,理论上速度最快
3、ORDER BY
ORDER BY 执行原理
- 查询出中间结果集(一个中间表)
- 把中间结果放入sort_buffer
- 根据ORDER BY字段,对中间结果集进行排序
- 如果还没查询出最终结果,则需回表生成完整结果集(排序中间表不一定是全部字段都有的,可能仅仅选取要排序的字段和主键)
条件查询
- 对where后要查询的字段,实现覆盖索引,可以改善查询速度
中间结果集
- 当中间结果集比较小,直接放在内存中排序
- 当中间结果集>sort_buffer_size时,在硬盘中排序(通常是归并排序)
- 通过调整sort_buffer_size,可以在内存使用和排序时间进行权衡优化
回表生成完整结果集
- 当 行数 < max_length_for_sort_data,生成全字段中间表
- 大于时,则生成排序字段和主键的中间表,需要回表在获取其他字段
- 增大max_length_for_sort_data,不一定能改善效率,因为增大同时会时中间结果集的大小增大,内存开销增大,原本在内存排序的,变成在硬盘排序,此时效率更慢
排序与索引
- 对于排序时生成的中间表,是不能走索引的
- 索引覆盖可以直接跳过生成中间结果集,直接输出查询结果
- ORDER BY字段需要有索引,或者在联合索引左侧
- 其他相关字段如where条件,和select输出的字段,均要在索引中
4、随机选取
ORDER BY RAND() 原理
实例 select xx, xxx from table order by rand() limit 1 实现随机选取的过程
- 创建一个临时表,字段包括rand和select选取的字段
- 遍历整个表,调用rand()函数,填写rand字段
- 取出rand和主键字段构建临时表,放入sort_buffer,并排序
- 取出第一行,获取主键,查询临时表
这个SQL语句速度是很慢的
- SQL执行过程中,创建了两次中间表,而且两次都是全长行数的中间表
- 经历了不必要的排序
- 多次调用rand()
解决方法
- 查询数据表总行数total
- 在0-total之间选取一个随机数r
- select xx, xxx from table limit r, 1
5、索引基数
6、索引下推
- 存在一个联合索引,索引字段为 z1, z2
- 但是,查询时,只针对索引字段的中间或者右边的字段进行查询,例如 select z1, z2 from table where z2 > xx
- 此时,会使用索引下推,即开启松散索引扫描
松散索引扫描
- 实际上是把这个联合索引,看成多个索引,z1字段的每一个值,就看成是一个索引,然后根据这个索引,对z2进行查询。
- 通常情况下,可以大大减少扫描行数,但是最坏的情况,就是全表扫描
7、不走索引
- 对索引字段做函数操作,优化器会放弃走索引,直接全表扫描。例如 select * from table where a+1 = 2
- 对字段使用时间函数后,无法走索引。例如 select * from table where month(t_date)=5
- 字符串与数字比较,会将字符串转换为数字。例如 z1字段为varchar,select * from table where z1=6。 实际上是相当于 select * from table where CAST(z1 as signed int)=6
- 隐式字符编码转换。utf8与utf8mb4比较时,会将utf8转换为utf8mb4。解决方法,可以用先将查询条件的字符串转换为索引字段的字符编码
8、分页查询
1. 偏移量大,效率低
- 例如 select * from table order by z1 LIMIT 900, 10
- 实际上是执行LIMIT之前的查询,查询出所有结果,再进行分页。
- 从而产生了很多无效数据
2. 优化思路
- 可以先采取索引覆盖,在利用最终ID回表查询
- 例如:先查询出主键,再利用得到的中间表和原表进行join操作
五、更新
1、MySql日志体系
三种日志
- 在数据库更新时,就会产生日志,bin log, redo log, undo log
bin log 归档日志
- server层产生的逻辑日志
- 用于进行数据的复制和传送(例如主从复制)
- bin log完整记录了数据库的每次操作,可以作为数据闪回手段
- bin log记录在专用的文件中
redo log重做日志
- InnoDB产生的物理日志,记录数据页的变化
- InnoDB日志优先于数据,数据写入了redo log,即视为已经更新
- 内存的数据更新后,再写redo log,数据落盘后,则删掉相应的redo log
- redo log存储在4个1GB的文件中,循环写入
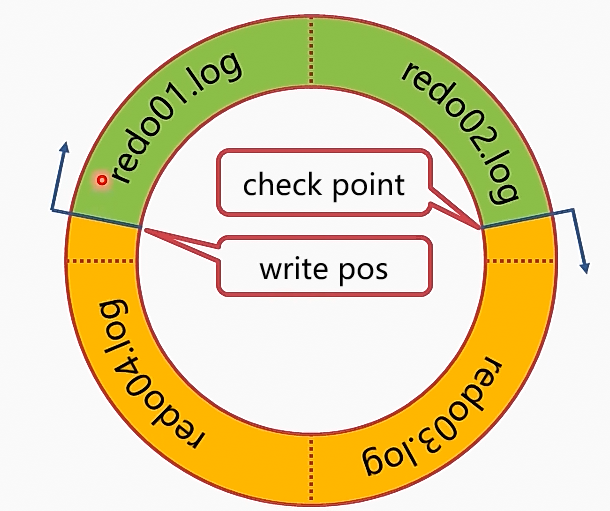
- write pos是当前日志的写入点
- check point是擦除点,数据落盘后被擦除
- 当write pos追上check point时,则说明日志已满,事务无法提交,需要等check point前进后才能提交
- 只要redo log不丢失,那么数据就不会丢失
undo log 回滚日志
- InnoDB产生的逻辑日志,用于事务的回滚和旧版本展示
- 对于任何数据的更新,都先写undo log
- undo log位于表空间的undo segment中
- 对于每一条SQL更新语句,都会在undo log写入一条撤销指令,例如:假设字段z1为321,把其更新成123,
UPDATE z1='123' undo log : UPDATE z1='321'
2、数据更新流程
InnoDB的数据更新流程如图所示
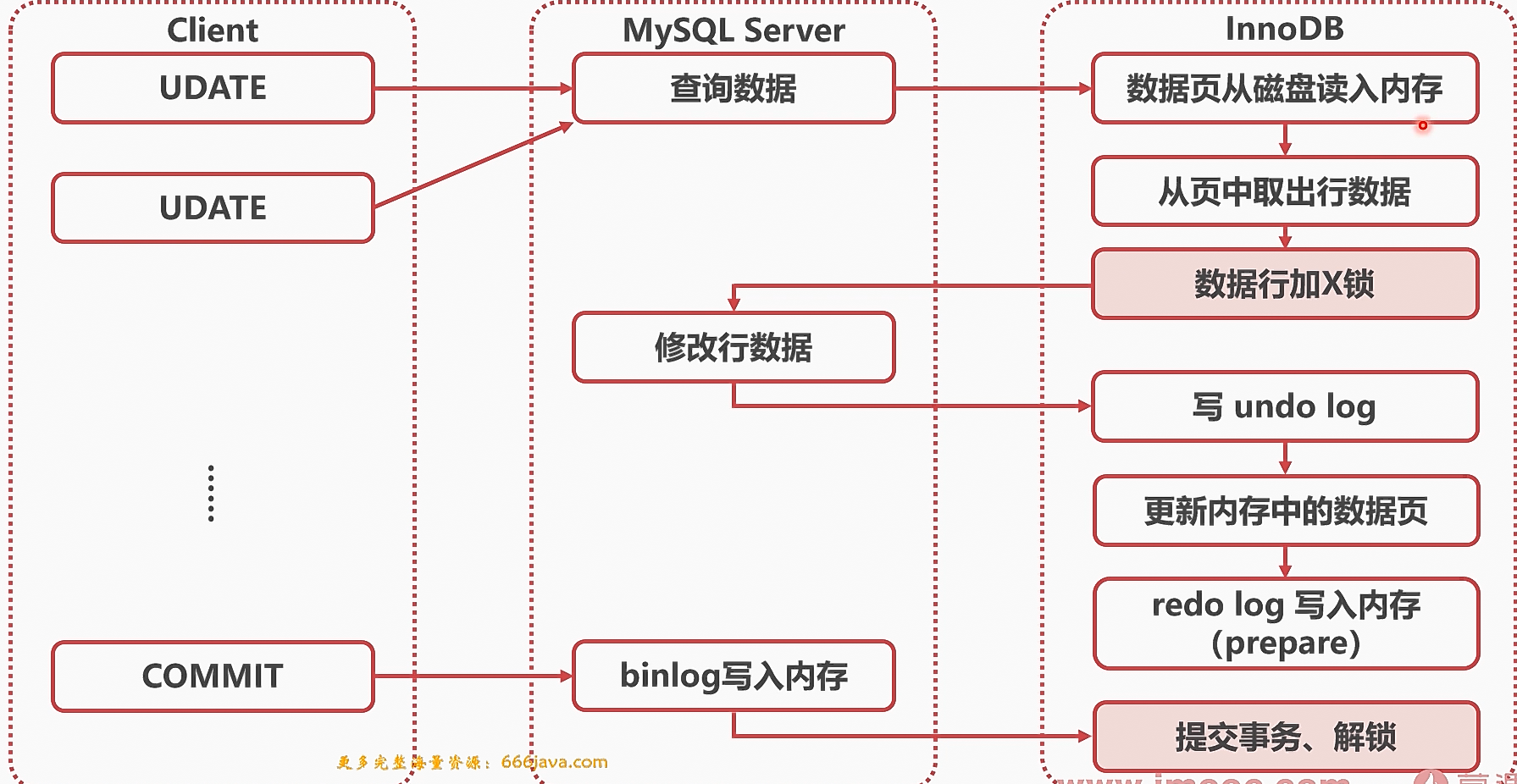
redo log刷盘
- 上图的数据更新流程,更新redo log只是更新其在内存中的页,而并没有真正的写入硬盘。
- 通过参数innodb_flush_log_at_trx_commit控制redo log刷盘。
- 0:异步、每秒刷盘
- 1:每个事务都刷盘
- n:每n个事务刷一次盘
- 通常设定为1
bin log刷盘
- 通过参数sync_binlog控制bin log刷盘
- 0:自动控制刷盘
- 1:每个事务都刷盘
- n:每n个事务刷一次盘
- 通常设定为1
崩溃分析
- redo log刷盘前崩溃:数据丢失
- redo log刷盘后崩溃:重启时,会重新读取redo log,并以此为据对bin log进行重写
- redo log的刷盘,是数据可否恢复的临界点
- redo log在bin log之前写,是因为bin log一旦写入,则有可能被传送至从库,和主库redo log不一致,从而出现业务错误
锁
MySQL锁的种类
- 按粒度划分:全局锁,表锁,行锁
- 全局锁会锁住所有表,即整个mysql数据库
- 表锁又分为数据锁和元数据锁
- 行锁锁住数据行,分为共享锁(S)和独占锁(X)
全局锁
- FTWRL(Flush table with read lock)
- 使整个数据库处于只读状态
- 主要用于保持主从备份一致性
- 通常在从库使用
数据锁
- lock tables XXX read/wirte
- 通常很少在InnoDB中使用
元数据锁(metadata lock)
- 元数据是指表的结构、字段、数据类型、索引等
- 事务访问数据时,会给表加MDL读锁
- 事务修改元数据时,会给表加MDL写锁
3、事务
ACID原则
- 原子性 atomic
- 一致性 consistency
- 隔离性 isolation
- 持久性 durability
4、四个隔离级别
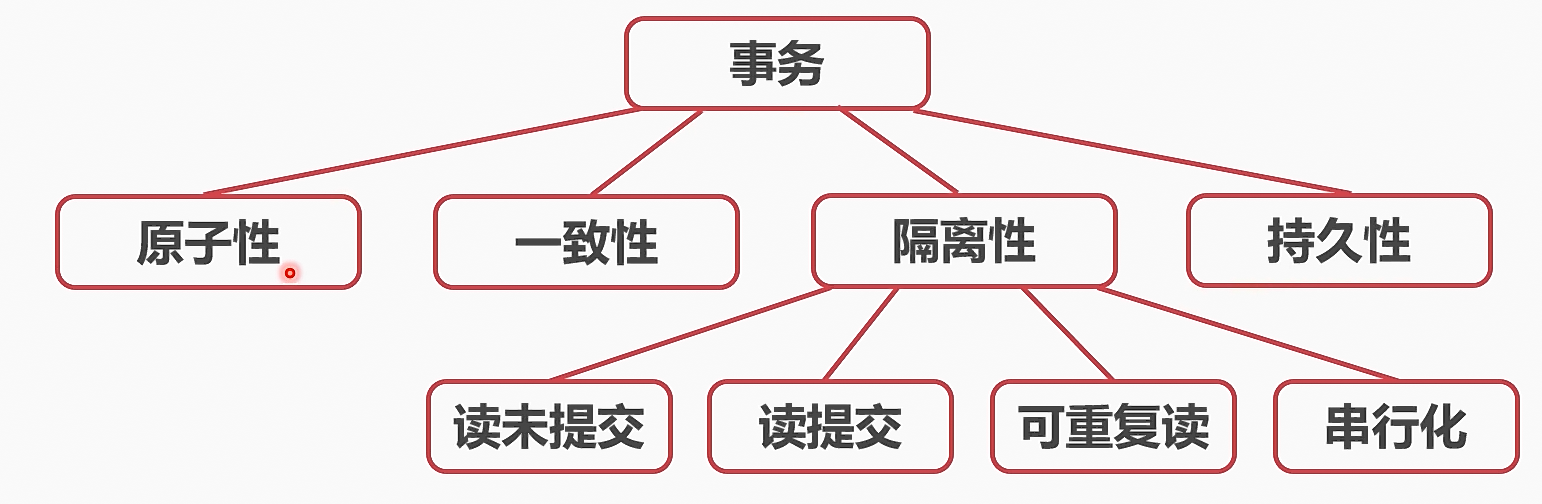
读未提交
- 读写都不加锁,不隔离
- 每次查询到的都是数据的最新版本,包括其他事务中未提交的更新
- 速度最快,但是通常不用
读提交
- 读取已经提交的数据
- 写数据时,添加写锁,提交后释放
可重复读
- 读取事务开始时的数据状态(快照),即使后面该数据正在被其他事务修改,也不会影响数据快照。
- 写数据时,添加写锁,提交后释放
- MySQL的默认隔离级别
- 采样了MVCC,实际上是通过redo log来推算出事务开始时的那个版本的数据
串行化
- 读加读锁,写加写锁
- 对于同一个数据,同时只有一个事务能够进行写
- 隔离级别最高,但是性能最低
6、隔离问题
脏读
- 读到了其他事务未提交的数据
不可重复读
- 同样的查询,读取到的数据内容不一样
幻读
- 同样的查询读取到了更多数据
MySQL对幻读的优化


- MySQL通过间隙锁解决幻读问题
- 间隙锁的功能与行锁相同,只是针对间隙加锁
- 间隙锁不分读写
- 可重复读加锁时,同时锁住数据及其左右间隙,使其无法插入数据
8、刷脏
脏页的产生
- 更新数据时,只更新了内存中的数据页,没有刷盘
- 内存中的数据页,和硬盘中的数据页不一致时,则称之为脏页
刷脏的含义
- 将内存中的数据页落盘
- 删除相关的redo log,并推进check point
为什么要刷脏
- 内存中的脏页太多,内存不够
- redo log写满,需要check point向前移动才能更新
- 系统空闲时,MySQL自动刷脏
- MySQL正常关闭前,保存数据
预防被迫刷脏
- 服务器IO配置:innodb_io_capacity
- 配置脏页比例上限:innodb_max_dirty_pages_pct,默认为75。当脏页比例接近该值时,会加速刷脏
- 顺便刷脏策略:innodb_flush_neighbors,通常SSD设置为0。
9、长事务的危害
锁无法释放
- 导致其他事务长时间等待
- 容易产生死锁
- MDL锁住大量事务,容易造成MySQL崩溃
行级锁长时间无法释放
- 对数据加锁,事务提交前无法释放,导致其他事务更新相同数据时,要长时间等待
解决方法
- 调整innodb_wait_lockt_timeout参数,默认为50。当等待50还无法获取锁,即返回报错
- 主动死锁检测:innodb_deadlock_detect。发现死锁时,回滚代价较小的事务。
10、MDL锁
- 锁的是表的字段
- 即锁住后,不能对表的结构进行调整,包括字段,索引等。
六、ORM框架
ORM框架的架构
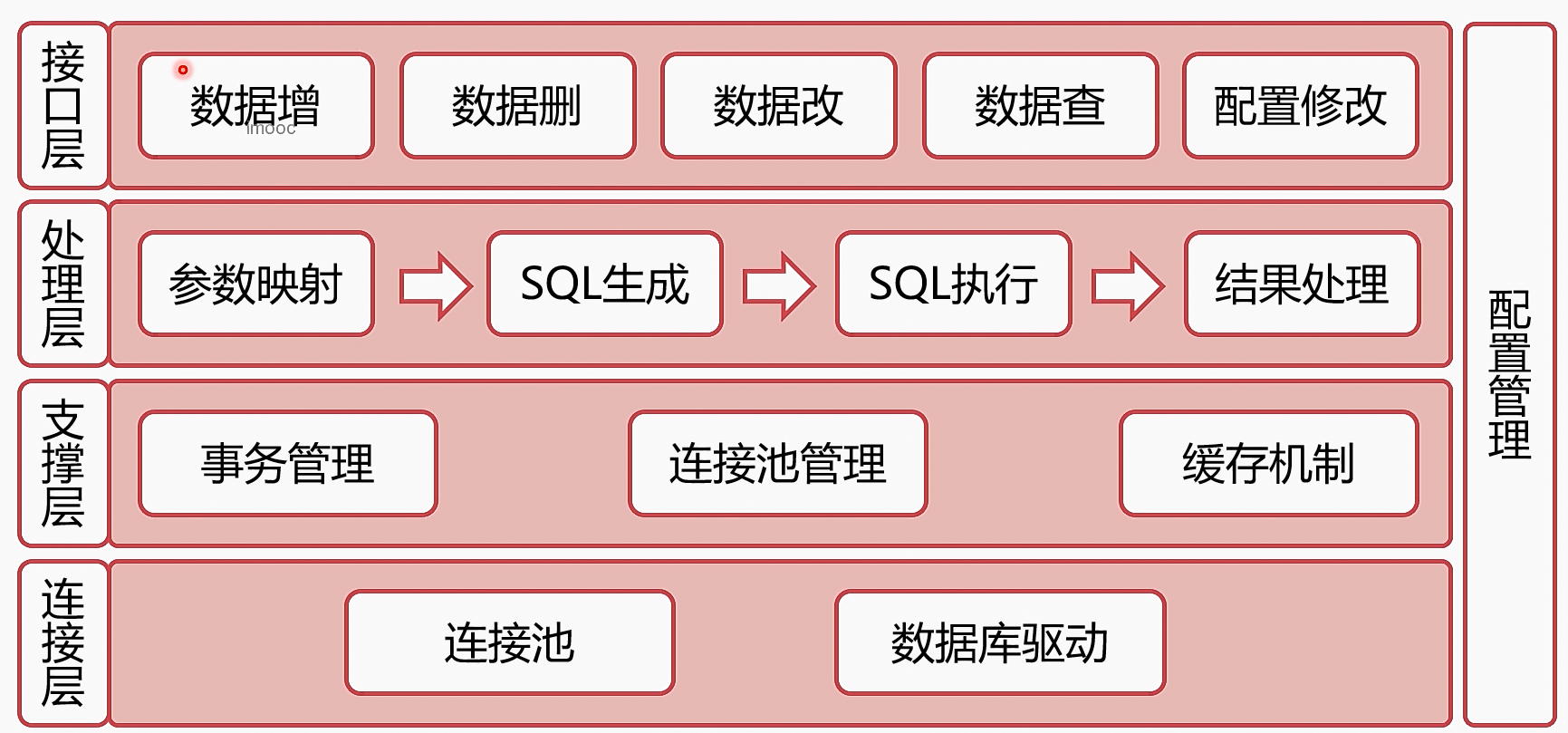
DAO与ORM
- DAO : data access object
- DAO是由ORM生成的
- DAO是ORM框架的接口层,是ORM框架的一部分
ORM框架的缺点
- ORM框架下,SQL是由框架生成的,可能出现性能问题(例如hibernate不走索引)
- 开发时往往更加注重业务逻辑,而忽略了SQL的性能
- 此时更推荐使用可以定制SQL的ORM框架,例如mybatis
七、MySQL三高架构
什么是三高
“三高架构”:
- 高并发:同时可以处理的事务数高,支持的客户端连接数高
- 高性能:SQL语句和事务执行的速度高
- 高可用:系统可用时间占比高
实现三高架构的手段
- 高并发:通过复制和扩展,把数据分散到多个数据库节点
- 高性能:通过复制提升执行速度,扩展提升容量
- 高可用:主从切换,或者cluster集群提高可用性
复制
- 目的:实现冗余数据,支持同时读取
- 实现:同过binlog把主库数据传输的备库
- 优点:提高并发数量,提高可用性
- 缺点:硬件占用高
扩展
- 目的:扩展数据库容量
- 实现:数据分片、分表、分库
- 优点:提高并发数量,提高可用性
- 缺点:可用性降低
切换
- 目的:提高可用性
- 实现:当主库不可用时,通过主从切换,把备库变为主库,必要时可以再开通过容器部署一个备库
- 优点:可用性高,并发量大
- 缺点:如果切换策略有问题,会丢失切换过程中的数据
复制

异步复制
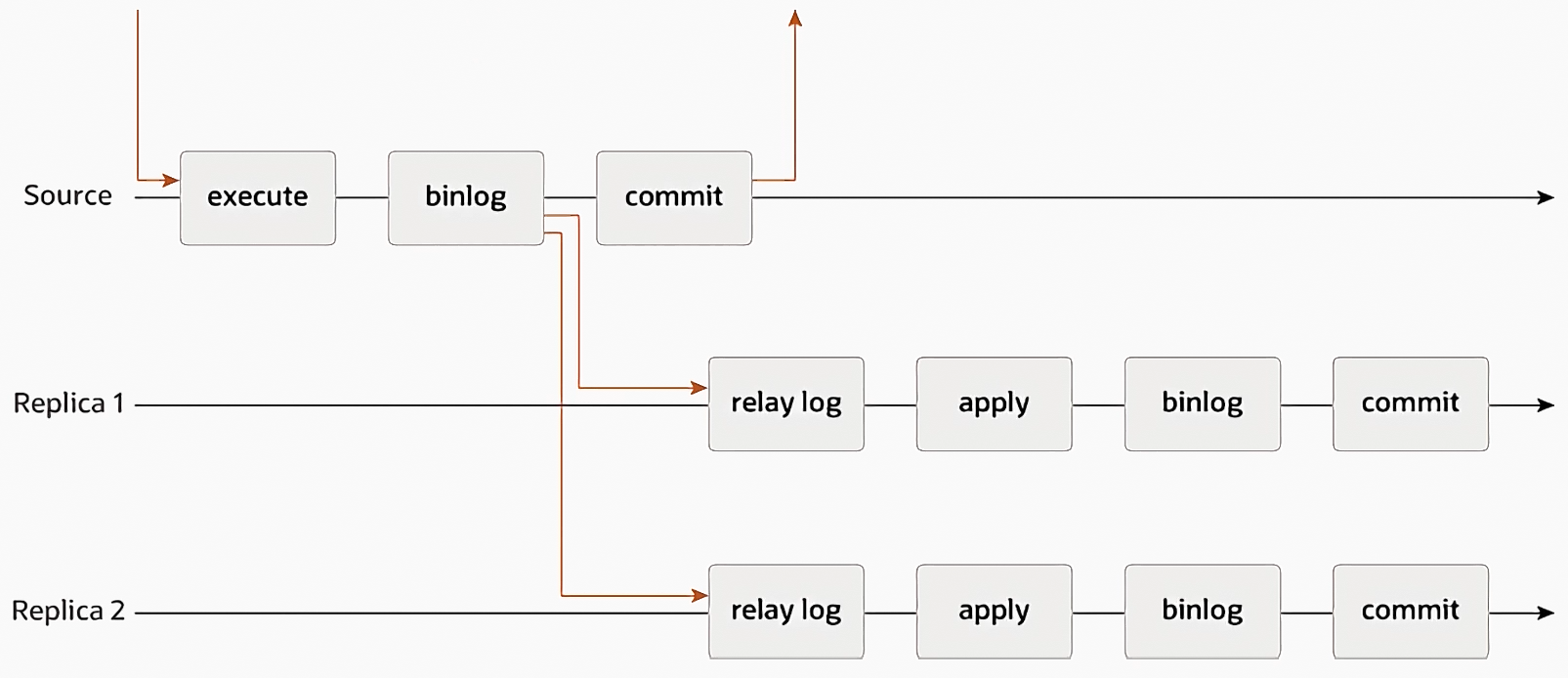
- 原理简单
- 对网络延迟要求小
- 但是不能保证数据已经被备库复制
半同步复制
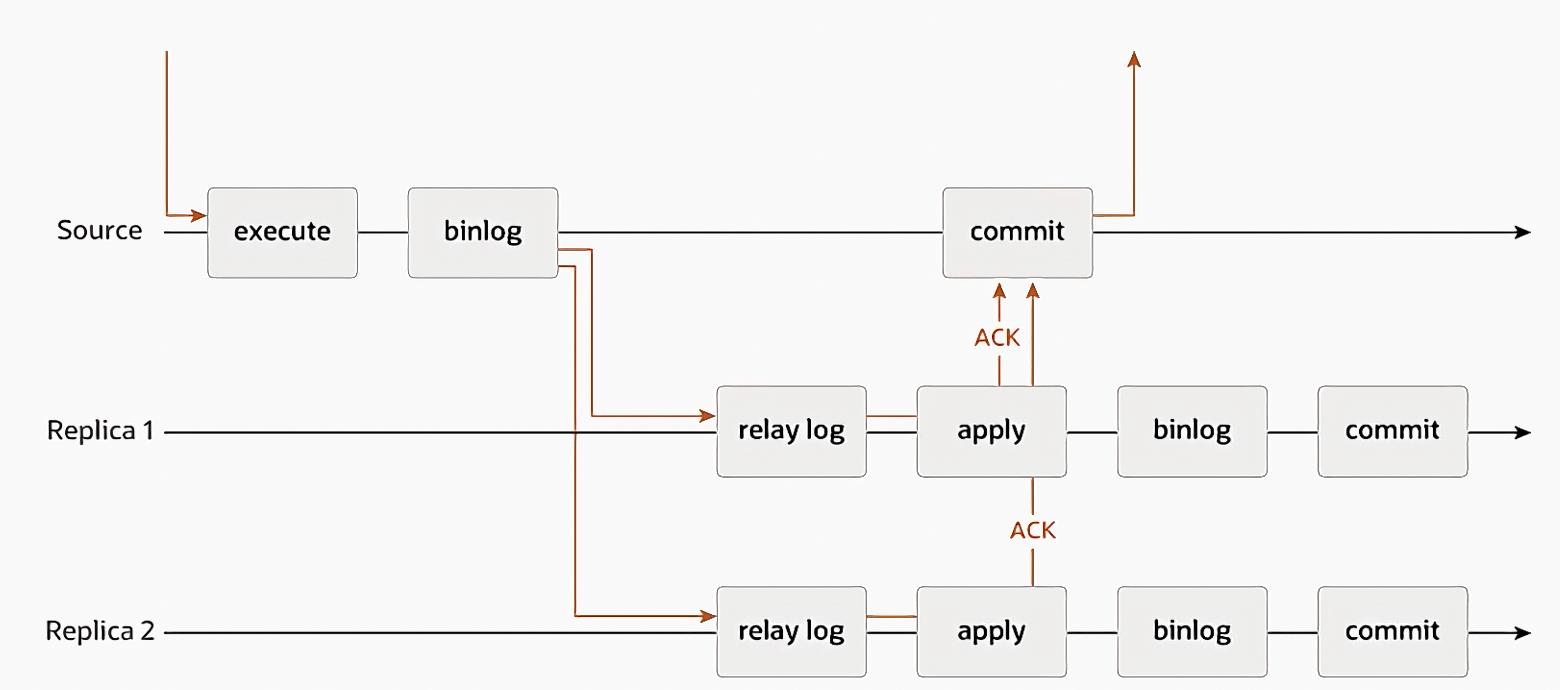
- 对网络延迟有要求,要部署在同一机房
- 对数据的复制有保证,不会轻易丢失
- rpl_semi_sync_master_timeout 参数可以调整确认超时的时间
组复制
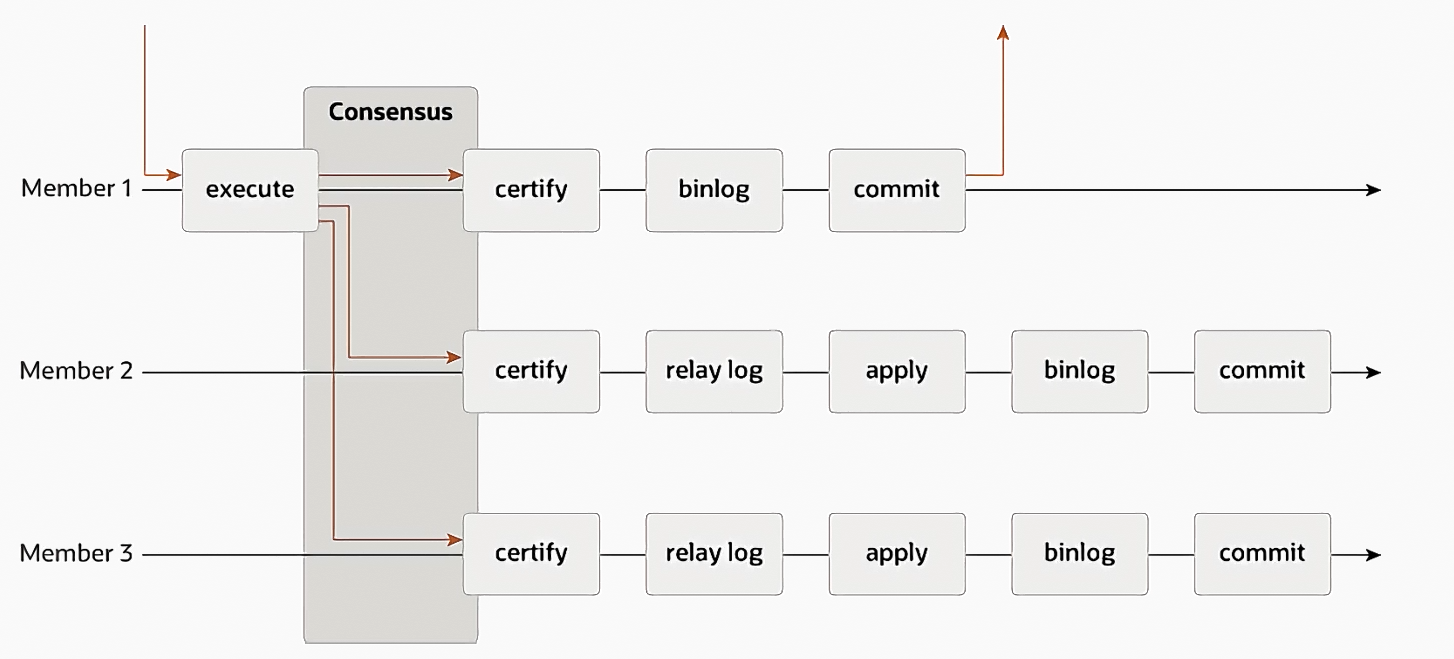
- 利用Paxos分布式一致性算法,确保SQL语句在主备库上同时执行
- 通常不用,因为MySQL不是原生分布式的,如果要分布式,那么用HBASE
复制实现
配置文件参数
- server-id:指定MySQL server在集群中的唯一id
- bin-log: 指定bin-log的名称和存放路径(默认情况下bin-log不会打开)
- gtid_mode: 是否开启全局事务模式(开启后,主备库的事务id都会唯一,不会冲突,便于复制)
- enforce_gtid_consistency: 是否开启gtid一致性
配置文件示例
server-id=123
bin-log=mysql-bin-log
gtid_mode=on
enforce_gtid_consistency=on
SQL指令
// 把当前数据库设置为master的备库
CHANGE MASTER TO MASTER_HOST='XXX.XX.XXX.XX', MASTER_USER='XXXX', MASTER_PASSWORD='XXXXXX', master_auto_position=1;
start slave;
binlog对复制的影响
statement格式
- 5.0之前的默认bin-log格式
- 记录SQL语句的原文
- 主备库之间,可能存在同一条SQL,结果不一样的情况,从而导致数据一致性出错
delete from table_x limit 1;
- 上述sql语句,在主备库可能执行是不一样的,因为这是随机选取一条记录删除,有可能主库和从库走的索引不同,从而删除不同的记录,导致数据出现冲突。
row格式
- 记录行数据的变化
- 不是物理日志,是逻辑日志
- 相对于statement格式,占用空间大
备库延迟
延迟的原因
- relay log重放耗时
- 通常情况下,备库的机器性能不如主库
- 备库承担了SQL分析语句
- 主库长事务未提交
- 根本原因:主库多线程执行,而备库只有一个线程用于重放relay log
解决方法
- 提高备库机器性能
- 备库关闭log实时落盘
- 增加备库数量,或者不在SQL数据库上执行分析任务,转而使用Hadoop
- 长事务拆分成多个小的事务
并行复制
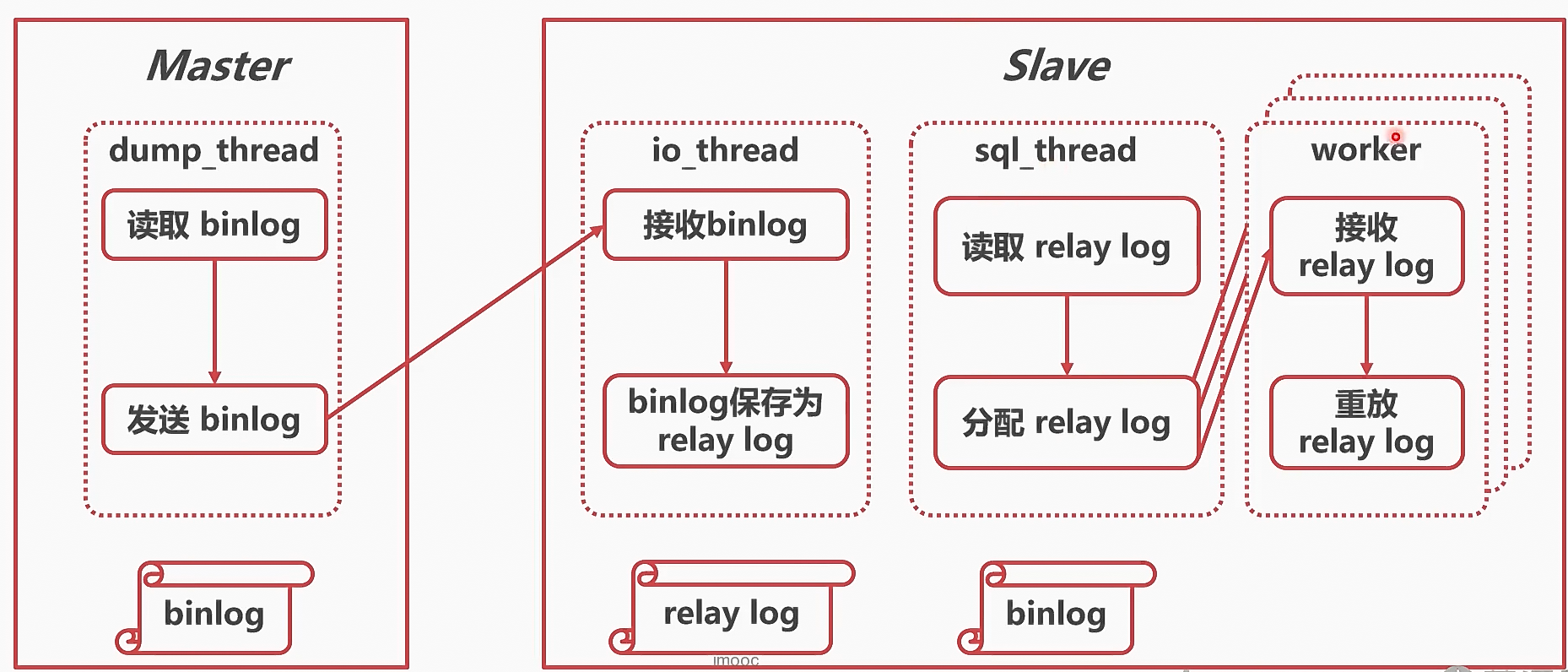
并行复制的分类
- 按表并行,粒度太大,性能提升不明显
- 按行并行
- 按事务并行
按事务组并行
-
bin log刷盘可以分为两个步骤:把bin log从 binlog cache写入内存打开的bin log文件,然后刷盘
![]()
-
基本思想:不相关的事务(即没有前后顺序依赖),可以同时执行,从而加快relay log重放速度
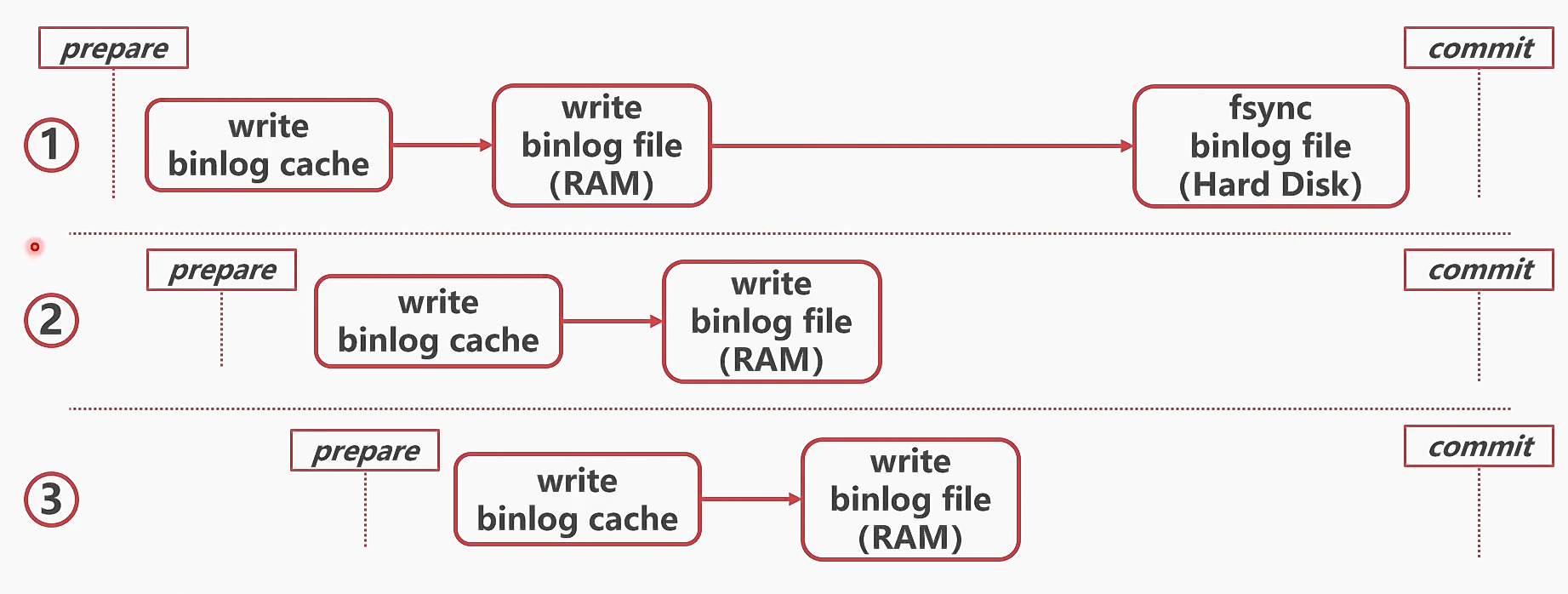
事务组并行刷盘参数
- binlog_group_commit_sync_delay: 延迟刷盘的微秒数
- binlog_group_commit_sync_no_delay_count: 累计多少次提交后才刷盘
- 二者是或的关系
开启组并行复制
- 设置 binlog-transaction-dependency-tracking 参数
- COMMIT_ORDER: 事务组并行
- WRITESET: 没有修改相同行的事务可以并行
- WRITESET_SESSION: 同一个线程,先后执行的事务不能并行
备库读取最新数据
备库数据是否是最新的判断
- 强制延时,根据业务经验,设定一个延时时间
- 当备库的seconds_behind_master=0时,(理论上不可能出现这种情况)
- 对比bin log执行位点
- 对比GTID执行情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号