


airflow 介绍
- airflow是一款开源的,分布式任务调度框架,它将一个具有上下级依赖关系的工作流,组装成一个有向无环图。
- 特点:
- 分布式任务调度:允许一个工作流的task在多台worker上同时执行
- 可构建任务依赖:以有向无环图的方式构建任务依赖关系
- task原子性:工作流上每个task都是原子可重试的,一个工作流某个环节的task失败可自动或手动进行重试,不必从头开始任务
- 工作流示意图
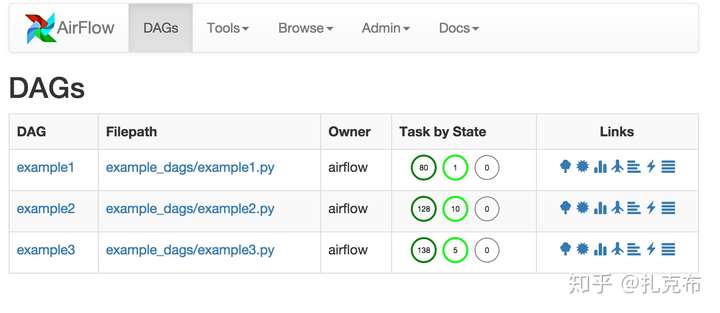
- 一个dag表示一个定时的工作流,包含一个或者多个具有依赖关系的task
- task依赖图
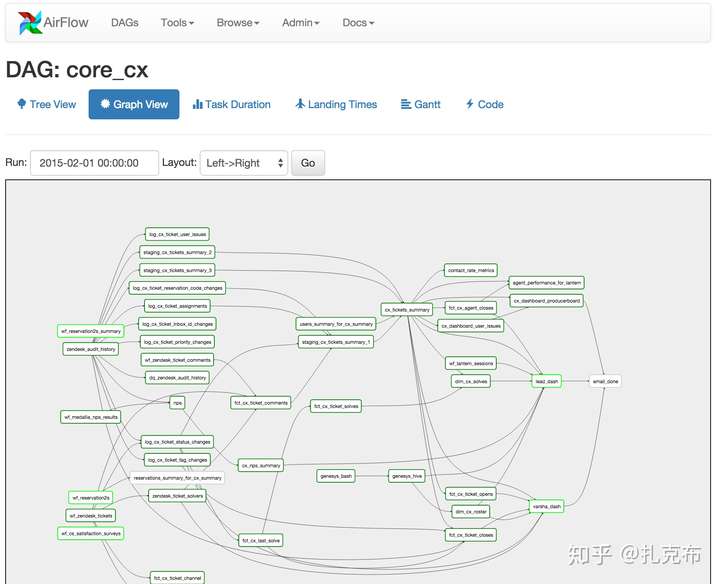
- 架构图及集群角色
- webserver : 提供web端服务,以及会定时生成子进程去扫描对应的目录下的dags,并更新数据库
- scheduler : 任务调度服务,根据dags生成任务,并提交到消息中间件队列中 (redis或rabbitMq)
- celery worker : 分布在不同的机器上,作为任务真正的的执行节点。通过监听消息中间件: redis或rabbitMq 领取任务
- flower : 监控worker进程的存活性,启动或关闭worker进程,查看运行的task
实战
构建docker镜像
- 采用的airflow是未发行的1.10.0版本,原因是从1.10.0开始,支持时区的设置,而不是统一的UTC
//self.registry.domain 为docker私有镜像仓库
//self.mvn.registry.com maven 私有镜像仓库
//data0 为数据目录,data1为日志目录,运维统一配置日志清楚策略
#docker build --network host -t self.registry.domain/airflow_base_1.10.7:1.0.0 .
FROM self.registry.domain/airflow/centos_base_7.4.1708:1.0.0
LABEL AIRFLOW=1.10.7
ARG CELERY_REDIS=4.1.1
ARG DOCKER_VERSION=1.13.1
ARG AIRFLOW_VERSION=1.10.7
ADD sbin /data0/airflow/sbin
ENV SLUGIFY_USES_TEXT_UNIDECODE=yes \
#如果构建镜像的机器需要代理才能连接外网的话,配置https_proxy
https_proxy=https://ip:port
RUN curl http://self.mvn.registry.com/python/python-3.5.6.jar -o /tmp/Python-3.5.6.tgz && \
curl http://self.mvn.registry.com/airflow/${AIRFLOW_VERSION}/airflow-${AIRFLOW_VERSION}.jar -o /tmp/incubator-airflow-${AIRFLOW_VERSION}.tar.gz && \
curl http:/self.mvn.registry.com/docker/${DOCKER_VERSION}/docker-${DOCKER_VERSION}.jar -o /tmp/docker-${DOCKER_VERSION}.tar.gz && \
tar zxf /tmp/docker-${DOCKER_VERSION}.tar.gz -C /data0/software && \
tar zxf /tmp/Python-3.5.6.tgz -C /data0/software && \
tar zxf /tmp/incubator-airflow-${AIRFLOW_VERSION}.tar.gz -C /data0/software && \
yum install -y libtool-ltdl policycoreutils-python && \
rpm -ivh --force --nodeps /data0/software/docker-${DOCKER_VERSION}/docker-engine-selinux-${DOCKER_VERSION}-1.el7.centos.noarch.rpm && \
rpm -ivh --force --nodeps /data0/software/docker-${DOCKER_VERSION}/docker-engine-${DOCKER_VERSION}-1.el7.centos.x86_64.rpm && \
yum -y install gcc && yum -y install gcc-c++ && yum -y install make && \
yum -y install zlib-devel mysql-devel python-devel cyrus-sasl-devel cyrus-sasl-lib libxml2-devel libxslt-devel && \
cd /data0/software/Python-3.5.6 && ./configure && make && make install && \
ln -sf /usr/local/bin/pip3 /usr/local/bin/pip && \
ln -sf /usr/local/bin/python3 /usr/local/bin/python && \
cd /data0/software/incubator-airflow-${AIRFLOW_VERSION} && python setup.py install && \
pip install -i https://pypi.douban.com/simple/ apache-airflow[crypto,celery,hive,jdbc,mysql,hdfs,password,redis,devel_hadoop] && \
pip install -i https://pypi.douban.com/simple/ celery[redis]==$CELERY_REDIS && \
pip install -i https://pypi.douban.com/simple/ docutils && \
ln -sf /usr/local/lib/python3.5/site-packages/apache_airflow-1.10.0-py3.5.egg/airflow /data0/software/airflow && \
mkdir -p /data0/airflow/bin && \
ln -sf /data0/airflow/sbin/airflow-200.sh /data0/airflow/bin/200.sh && \
ln -sf /data0/airflow/sbin/airflow-503.sh /data0/airflow/bin/503.sh && \
chown -R root:root /data0/software/ && \
chown -R root:root /data0/airflow/ && \
chmod -R 775 /data0/airflow/sbin/* && \
chmod -R 775 /data0/airflow/bin/* && \
echo 'source /data0/airflow/sbin/init-airflow.sh' >> ~/.bashrc && \
rm -rf /tmp/* /data0/software/Python-3.5.6 /data0/software/incubator-airflow-${AIRFLOW_VERSION} /data0/software/docker-${DOCKER_VERSION}
ENV PATH=$PATH:/data0/software/jdk/bin:/data0/software/airflow/bin:/data0/airflow/sbin/:/data0/airflow/sbin/airflow/:/data0/airflow/bin/
WORKDIR /data0/airflow/bin/
- 通过docker 启动容器的话需要暴露几个端口
webserver: 8081
worker: 8793
flower: 5555
//启动示例
docker run --name airflow -it -d --privileged --net=host -p 8081:8081 -p 5555:5555 -p 8793:8793 -v /var/run/docker.sock:/var/run/docker.sock -v /data1:/data1 -v /data0/airflow:/data0/airflow self.registry.domain/airflow_1.10.7:1.0.0
- airflow 升级到未release的1.10.0的版本
- 如果之前用的是低版本的话,需要执行airflow upgradedb 来更新迁移数据库的schema
- 由于1.10.0版本对一些参数配置名称进行了修改,需要重新进行对号入座,如:
celeryd_concurrency -> worker_concurrency
celery_result_backend -> result_backend- 1.10.0版本开始支持自定义时区,而不需要再统一使用默认的UTC时区,但是界面上的显示还是统一UTC,所以需要对代码进行定制化,以支持界面按照我们想要的时区显示
//airflow.cfg
default_timezone = Etc/GMT-8
//views.py
def utc2local(utc):
epoch = time.mktime(utc.timetuple())
offset = datetime.fromtimestamp(epoch) - datetime.utcfromtimestamp(epoch)
return utc + offset
//dags.html
utc2local(last_run.execution_date).strftime("%Y-%m-%d %H:%M")
utc2local(last_run.start_date).strftime("%Y-%m-%d %H:%M")
airflow plugins 定制化开发
- 官方plugins文档
- 由于dag的删除现在官方没有暴露直接的api,而完整的删除又牵扯到多个表,总结出删除dag的sql如下
set @dag_id = 'BAD_DAG';
delete from airflow.xcom where dag_id = @dag_id;
delete from airflow.task_instance where dag_id = @dag_id;
delete from airflow.sla_miss where dag_id = @dag_id;
delete from airflow.log where dag_id = @dag_id;
delete from airflow.job where dag_id = @dag_id;
delete from airflow.dag_run where dag_id = @dag_id;
delete from airflow.dag where dag_id = @dag_id;
实现的200和503脚本,用于集群统一的上下线操作
- 200脚本用于统一操作集群服务上线
#!/usr/bin/env bash
function usage() {
echo -e "\n A tool used for starting airflow services
Usage: 200.sh {webserver|worker|scheduler|flower}
"
}
PORT=8081
ROLE=webserver
ENV_ARGS=""
check_alive() {
PID=`netstat -nlpt | grep $PORT | awk '{print $7}' | awk -F "/" '{print $1}'`
[ -n "$PID" ] && return 0 || return 1
}
check_scheduler_alive() {
PIDS=`ps -ef | grep "/usr/local/bin/airflow scheduler" | grep "python" | awk '{print $2}'`
[ -n "$PIDS" ] && return 0 || return 1
}
function get_host_ip(){
local host=$(ifconfig | grep "inet " | grep "\-\->" | awk '{print $2}' | tail -1)
if [[ -z "$host" ]]; then
host=$(ifconfig | grep "inet " | grep "broadcast" | awk '{print $2}' | tail -1)
fi
echo "${host}"
}
start_service() {
if [ $ROLE = 'scheduler' ];then
check_scheduler_alive
else
check_alive
fi
if [ $? -ne 0 ];then
nohup airflow $ROLE $ENV_ARGS > $BASE_LOG_DIR/$ROLE/$ROLE.log 2>&1 &
sleep 5
if [ $ROLE = 'scheduler' ];then
check_scheduler_alive
else
check_alive
fi
if [ $? -ne 0 ];then
echo "service start error"
exit 1
else
echo "service start success"
exit 0
fi
else
echo "service alreay started"
exit 0
fi
}
function main() {
if [ -z "${POOL}" ]; then
echo "the environment variable POOL cannot be empty"
exit 1
fi
source /data0/hcp/sbin/init-hcp.sh
case "$1" in
webserver)
echo "starting airflow webserver"
ROLE=webserver
PORT=8081
start_service
;;
worker)
echo "starting airflow worker"
ROLE=worker
PORT=8793
local host_ip=$(get_host_ip)
ENV_ARGS="-cn ${host_ip}@${host_ip}"
start_service
;;
flower)
echo "starting airflow flower"
ROLE=flower
PORT=5555
start_service
;;
scheduler)
echo "starting airflow scheduler"
ROLE=scheduler
start_service
;;
*)
usage
exit 1
esac
}
main "$@"
- 503脚本用于统一操作集群服务下线
#!/usr/bin/env bash
function usage() {
echo -e "\n A tool used for stop airflow services
Usage: 200.sh {webserver|worker|scheduler|flower}
"
}
function get_host_ip(){
local host=$(ifconfig | grep "inet " | grep "\-\->" | awk '{print $2}' | tail -1)
if [[ -z "$host" ]]; then
host=$(ifconfig | grep "inet " | grep "broadcast" | awk '{print $2}' | tail -1)
fi
echo "${host}"
}
function main() {
if [ -z "${POOL}" ]; then
echo "the environment variable POOL cannot be empty"
exit 1
fi
source /data0/hcp/sbin/init-hcp.sh
case "$1" in
webserver)
echo "stopping airflow webserver"
cat $AIRFLOW_HOME/airflow-webserver.pid | xargs kill -9
;;
worker)
echo "stopping airflow worker"
PORT=8793
PID=`netstat -nlpt | grep $PORT | awk '{print $7}' | awk -F "/" '{print $1}'`
kill -9 $PID
local host_ip=$(get_host_ip)
ps -ef | grep celeryd | grep ${host_ip}@${host_ip} | awk '{print $2}' | xargs kill -9
;;
flower)
echo "stopping airflow flower"
PORT=5555
PID=`netstat -nlpt | grep $PORT | awk '{print $7}' | awk -F "/" '{print $1}'`
kill -9 $PID
start_service
;;
scheduler)
echo "stopping airflow scheduler"
PID=`ps -ef | grep "/usr/local/bin/airflow scheduler" | grep "python" | awk '{print $2}'`
kill -9 $PID
;;
*)
usage
exit 1
esac
}
main "$@"
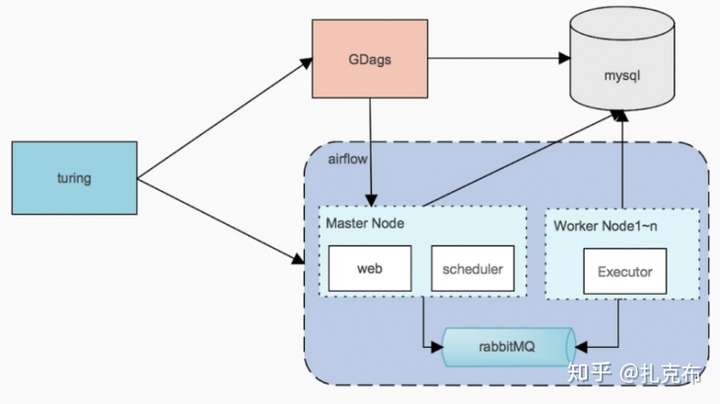
All in docker
为了使宿主机尽量clean,woker/master 节点便捷的横向扩展,我们所有服务(airflow worker/master/具体task) 都通过docker 的形式发布/调度。同时这样做也便于结合我们内部的代码构建发布工具
通过gitlab CI 规范dag发布流程
随着任务托管规模的扩大,使用业务方的增多,不规范的dag提交流程(上机器直接操作目录)可能导致所有任务灾难性不可恢复。于是dag的提交应该规范起来。
因为我们是通过gitlab对代码进行托管的,而某种程度上,dag的管理也是一种代码托管。所以我们把dag放在了gitlab上,结合gitlab CI工具,业务方提交dag之后需经过上一级的review之后合入主分支,此时触发一个事件,通知airflow master上的dag更新服务对dag目录进行更新。整个过程如下图
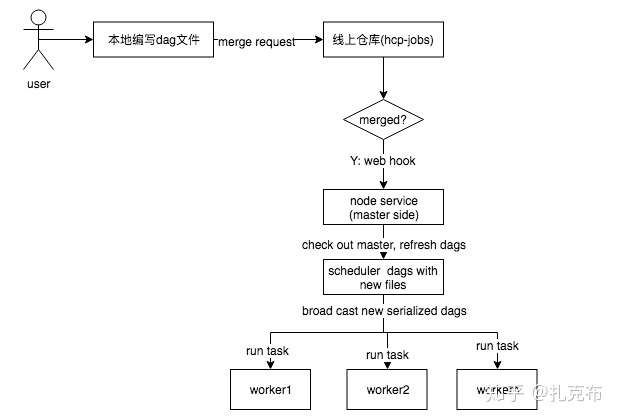
自定义Spark流/批任务托管插件
由于团队主要使用Spark计算框架进行离线和实时计算,Spark一般以Cluster模式提交任务。
对于批任务而言,此时计算结果是异步的,在airflow中的表现是上游任务提交完就成功退出,下游任务开始执行。如果在airflow中两个spark任务有明显的上下游数据依赖关系的话,会导致下游任务雪崩式的失败,很明显达不到任务托管的目的。当然,如果spark最终写入hive table的话还可以用airlfow自带的Sensor,但是我们只是产出到某个目录,所以此方案行不通。
于是我们定制了数据spark任务提交以及数据质量检查插件,在提交任务后不断轮询任务状态以及最后产出路径数据状态,当数据质量校验通过后,才成功退出当前任务;否则根据超时机制和重试次数对任务进行重跑。提交示例如下(通过response_check回调函数对数据质量进行校验):
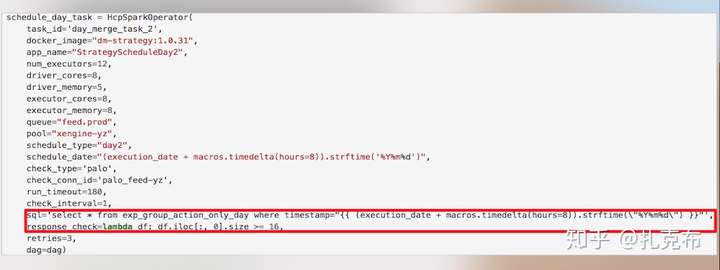
对于流任务而言,虽然airflow不太适合托管常驻型任务,但我们想的是统一流批任务的提交,管理,重试机制的方式,所以也通过插件的方式定制化。提交示例如下:

遇到的坑以及定制化解决方案
问题1: airflow worker 角色不能使用根用户启动
- 原因:不能用根用户启动的根本原因,在于airflow的worker直接用的celery,而celery 源码中有参数默认不能使用ROOT启动,否则将报错, 源码链接
C_FORCE_ROOT = os.environ.get('C_FORCE_ROOT', False)
ROOT_DISALLOWED = """\
Running a worker with superuser privileges when the
worker accepts messages serialized with pickle is a very bad idea!
If you really want to continue then you have to set the C_FORCE_ROOT
environment variable (but please think about this before you do).
User information: uid={uid} euid={euid} gid={gid} egid={egid}
"""
ROOT_DISCOURAGED = """\
You're running the worker with superuser privileges: this is
absolutely not recommended!
Please specify a different user using the --uid option.
User information: uid={uid} euid={euid} gid={gid} egid={egid}
"""- 解决方案一:修改airlfow源码,在celery_executor.py中强制设置C_FORCE_ROOT
from celery import Celery, platforms
在app = Celery(…)后新增
platforms.C_FORCE_ROOT = True
重启即可 - 解决方案二:在容器初始化环境变量的时候,设置C_FORCE_ROOT参数,以零侵入的方式解决问题
强制celery worker运行采用root模式
export C_FORCE_ROOT=True
问题2: docker in docker
- 在dags中以docker方式调度任务时,为了container的轻量化,不做重型的docker pull等操作,我们利用了docker cs架构的设计理念,只需要将宿主机的/var/run/docker.sock文件挂载到容器目录下即可 docker in docker 资料
问题3: 多个worker节点进行调度反序列化dag执行的时候,报找不到module的错误
- 当时考虑到文件更新的一致性,采用所有worker统一执行master下发的序列化dag的方案,而不依赖worker节点上实际的dag文件,开启这一特性操作如下
worker节点上: airflow worker -cn=ip@ip -p //-p为开关参数,意思是以master序列化的dag作为执行文件,而不是本地dag目录中的文件
master节点上: airflow scheduler -p
- 错误原因: 远程的worker节点上不存在实际的dag文件,反序列化的时候对于当时在dag中定义的函数或对象找不到module_name
- 解决方案一:在所有的worker节点上同时发布dags目录,缺点是dags一致性成问题
- 解决方案二:修改源码中序列化与反序列化的逻辑,主体思路还是替换掉不存在的module为main。修改如下:
//models.py 文件,对 class DagPickle(Base) 定义修改
import dill
class DagPickle(Base):
id = Column(Integer, primary_key=True)
# 修改前: pickle = Column(PickleType(pickler=dill))
pickle = Column(LargeBinary)
created_dttm = Column(UtcDateTime, default=timezone.utcnow)
pickle_hash = Column(Text)
__tablename__ = "dag_pickle"
def __init__(self, dag):
self.dag_id = dag.dag_id
if hasattr(dag, 'template_env'):
dag.template_env = None
self.pickle_hash = hash(dag)
raw = dill.dumps(dag)
# 修改前: self.pickle = dag
reg_str = 'unusual_prefix_\w*{0}'.format(dag.dag_id)
result = re.sub(str.encode(reg_str), b'__main__', raw)
self.pickle =result
//cli.py 文件反序列化逻辑 run(args, dag=None) 函数
// 直接通过dill来反序列化二进制文件,而不是通过PickleType 的result_processor做中转
修改前: dag = dag_pickle.pickle
修改后:dag = dill.loads(dag_pickle.pickle) - 解决方案三:源码零侵入,使用python的types.FunctionType重新创建一个不带module的function,这样序列化与反序列化的时候不会有问题
new_func = types.FunctionType((lambda df: df.iloc[:, 0].size == xx).__code__, {})问题4: 在master节点上,通过webserver无法查看远程执行的任务日志
- 原因:由于airflow在master查看task执行日志是通过各个节点的http服务获取的,但是存入task_instance表中的host_name不是ip,可见获取hostname的方式有问题.
- 解决方案:修改airflow/utils/net.py 中get_hostname函数,添加优先获取环境变量中设置的hostname的逻辑
//models.py TaskInstance
self.hostname = get_hostname()
//net.py 在get_hostname里面加入一个获取环境变量的逻辑
import os
def get_hostname():
"""
Fetch the hostname using the callable from the config or using
`socket.getfqdn` as a fallback.
"""
# 尝试获取环境变量
if 'AIRFLOW_HOST_NAME' in os.environ:
return os.environ['AIRFLOW_HOST_NAME']
# First we attempt to fetch the callable path from the config.
try:
callable_path = conf.get('core', 'hostname_callable')
except AirflowConfigException:
callable_path = None
# Then we handle the case when the config is missing or empty. This is the
# default behavior.
if not callable_path:
return socket.getfqdn()
# Since we have a callable path, we try to import and run it next.
module_path, attr_name = callable_path.split(':')
module = importlib.import_module(module_path)
callable = getattr(module, attr_name)
return callable()

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决