

Google 开发的 Golang 自 2009 年推出,已经日趋成为各大公司开发后端服务使用的语言,有名的基于 Golang 的开源项目有Docker、Kubernetes等。当使用 Golang 开发服务后端时,难免产生性能问题,如内存泄漏、Goroutine 卡死等,Golang 是一个对性能要求很高的语言,因此语言中自带的 PProf 工具成为我们检测 Golang 开发应用性能的利器。
Profiling 一般翻译为 画像,在计算机领域,我们可以将其理解为当前应用状态的画像。当程序性能不佳时,我们希望知道应用在 什么地方 耗费了 多少 CPU、memory。下面将介绍如何使用这一工具。
PProf 关注的模块
- CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据
- Memory Profile(Heap Profile):报告程序的内存使用情况
- Block Profiling:报告 goroutines 不在运行状态的情况,可以用来分析和查找死锁等性能瓶颈
- Goroutine Profiling:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
两种引入方式
PProf 可以从以下两个包中引入:
import "net/http/pprof"
import "runtime/pprof"
其中 net/http/pprof 使用 runtime/pprof 包来进行封装,并在 http 端口上暴露出来。runtime/pprof 可以用来产生 dump 文件,再使用 Go Tool PProf 来分析这运行日志。
使用 net/http/pprof 可以做到直接看到当前 web 服务的状态,包括 CPU 占用情况和内存使用情况等。
如果服务是一直运行的,如 web 应用,可以很方便的使用第一种方式 import "net/http/pprof",下面主要介绍通过 web 收集 prof 信息方式的使用。
PProf 使用方式
如果使用了默认的 http.DefaultServeMux(通常是代码直接使用 http.ListenAndServe("0.0.0.0:8000", nil)),只需要添加一行:
import _ "net/http/pprof"
如果应用使用了自定义的 Mux,则需要手动注册一些路由规则:
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
服务起来之后,就会多多一条路由,如http://127.0.0.1:8000/debug/pprof,有以下输出
/debug/pprof/
profiles:
0 block
62 goroutine
444 heap
30 threadcreate
full goroutine stack dump
这个路径下还有几个子页面:
/debug/pprof/profile:访问这个链接会自动进行 CPU profiling,持续 30s,并生成一个文件供下载/debug/pprof/heap: Memory Profiling 的路径,访问这个链接会得到一个内存 Profiling 结果的文件/debug/pprof/block:block Profiling 的路径/debug/pprof/goroutines:运行的 goroutines 列表,以及调用关系
使用 Go Tool PProf 分析工具
Go Tool PProf 工具可以对以上链接下载的 prof 文件进行更详细的分析,可以生成调用关系图和火焰图。
生成调用关系图
- 先下载
graphviz工具 - 分析工具使用命令
go tool pprof [binary][source] - 生成关系调用图
go tool pprof demo demo.prof
(pprof) web #生成调用关系图,demo.svg文件
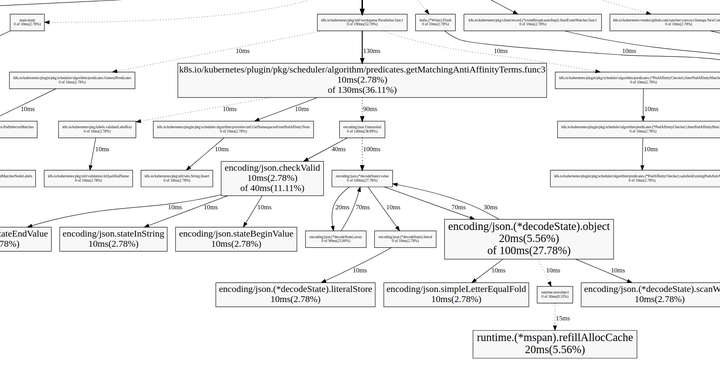
每个方框代表一个函数,方框的大小和执行时间成正比,箭头代表调用关系,箭头上的时间代表被调用函数的执行时间
查看 topN 数据
- topN 命令可以查出程序最耗 CPU 的调用
(pprof) top10
130ms of 360ms total (36.11%)
Showing top 10 nodes out of 180 (cum >= 10ms)
flat flat% sum% cum cum%
20ms 5.56% 5.56% 100ms 27.78% func1
20ms 5.56% 11.11% 20ms 5.56% func2
...- flat、flat% 表示函数在 CPU 上运行的时间以及百分比
- sum% 表示当前函数累加使用 CPU 的比例
- cum、cum%表示该函数以及子函数运行所占用的时间和比例,应该大于等于前两列的值
- topN 命令可以查出程序最耗 memory 的调用
(pprof) top
11712.11kB of 14785.10kB total (79.22%)
Dropped 580 nodes (cum <= 73.92kB)
Showing top 10 nodes out of 146 (cum >= 512.31kB)
flat flat% sum% cum cum%
2072.09kB 14.01% 14.01% 2072.09kB 14.01% func1
2049.25kB 13.86% 27.87% 2049.25kB 13.86% func2
...
生成火焰图
- 先下载
[go-torch](https://github.com/uber/go-torch)工具 - 生成 火焰图
go-torch -u url( 选择是 CPU 或是 memory 等的 profile 文件 )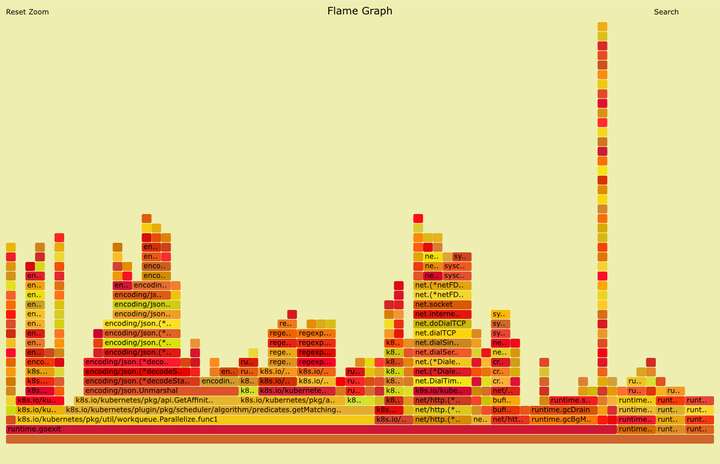
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
- 火焰图使用
- 鼠标悬浮
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比 - 点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息 - 搜索
按下 Ctrl + F 会显示一个搜索框,用户可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示

