Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin
hadoop官网:http://hadoop.apache.org/
本文结构如下:
- 安装hadoop前的准备工作
1.1 创建新用户
1.2 更新APT
1.3 安装SSH
1.4 安装Java环境
2.安装和配置hadoop
2.1 hadoop下载
2.2 hadoop为分布式模式配置
3.问题总结
1.安装hadoop前的准备工作
1.1创建hadoop用户
为了方便以后的实验进行,推荐创建一个新的hadoop用户,所有实验内容都登陆该用户进行,具体的shell代码和注释如下:
sudo useradd -m hadoop -s /bin/bash #创建用户hadoop,并使用/bin/bash作为Shell sudo passwd hadoop #设置hadoop的密码 sudo adduser hadoop sudo #为hadoop增加管理员权限
1.2更新APT
APT是一款软件管理工具,Linux采用APT来安装和管理各种软件,安装成功LInux系统以后,需要及时更新APT软件,否则后续的一些软件可能无法正常安装,更新APT使用以下命令:
sudo apt-get update
1.3安装SSH
SSH是Secure Shell的缩写.....
为什么要安装Hasoop之前要配置SSH呢? 这是因为Hadoop名称节点(NameNode)需要启用集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登陆来实现。Hadoop并没有提供SSH输入密码登陆的形式,因此,为了能够顺利登陆集群中的每台机器,需要将所有机器配置为“名称节点可以无密码登陆它们”
Ubuntu默认已经安装了SSH客户端,因此,只需要安装SSH服务端,在终端中执行以下命令:
sudo apt-get install openssh-server
然后可以使用如下命令登陆本机(因为是伪分布式集群,只有一台机器,同时作为名称节点和普通节点),如果提示输入密码,则表示安装成功了:
ssh localhost
由于这样登陆需要每次输入密码,所以,有必要配置SSH为无密码登陆,这样在Hadoop集群中,名称节点(NameNode)要登陆某台机器就不需要人工输入密码了(实际上也不可能每次都人工输入密码),SSH免密登陆配置方法如下:
cd ~/.ssh/ #,切换目录,若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa #会有提示,按enter即可(即不设置密码),这条语句生成公钥和私钥两个文件,补充ssh-keygen的基本用法:https://blog.csdn.net/qq_38570571/article/details/79268426 cat ./id_rsa.pub >> ./authorized_keys #加入授权,cat file1 >> file2 的含义是将file1的内容写入到file2的尾部
然后再执行ssh localhost命令,无需输入密码就可以直接登陆了,如图:

1.4 安装Java环境
Hadoop是基于Java语言开发的,同时Java语言也可以用来编写Hadoop应用程序,在Linux系统中安装Java环境有两种方式:Oracle的JDK或OpenJDK,本文采用第二中方式:
sudo apt-get install default-jre default-jdk #使用apt安装jre和jdk
安装完成后,编辑~/.bashrc,添加JAVA_HOME环境变量:
vim ~/.bashrc #编辑~/.bashrc
在.bashrc中添加如下单独一行:
export JAVA_HOME=/usr/lib/jvm/defult-java
然后执行如下代码,使环境变量立即生效:
source ~/.bashrc #使环境变量设置生效
检验一下是否设置正确:
echo $JAVA_HOME #打印$JAVA_HOME java --version #查看java版本
Java安装成功后,就可以进行Hadoop的安装了
2.安装和配置Hadoop
2.1 Hadoop下载和安装
Hadoop官网:http://hadoop.apache.org/,选择合适的版本(本文采用Hadoop2.7.7)下载(可以在windows系统中下载后,用ftp软件如filezilla上传到ubuntu虚拟机,也可以在ubuntu中直接下载),本文使用filezilla上传hadoop压缩包到ubuntu的~/Downloads/目录下,然后解压缩到/usr/local/并重命名文件夹为hadoop,由于我们当前的用户为hadoop,没有usr/local的文件权限,所以还需要修改文件权限,执行命令如下:
sudo tar -zxf ~/Downloads/hadoop-2.7.7.tar.gz -C /usr/local #解压缩 cd /usr/local/ sudo mv ./hadoop-2.7.7 ./hadoop #重命名文件 sudo chown -R hadoop ./hadoop #修改文件权限,即将./hadoop目录下所有的文件的属组都改成hadoop,也可以使用sudo chmod 777 ./hadoop
解压成功后,就可以使用如下命令查看Hadoop的版本信息:
cd /usr/local/hadoop
./bin/hadoop version
2.2Hadoop模式配置
Hadoop的默认模式为本地模式(即单机模式),无须其他配置就可以运行,值得注意的是,Hadoop的模式变更(单机模式、伪分布式、分布式)完全是通过修改配置文件实现的,本文想要将Hadoop配置为伪分布式模式,即只有一个节点(一台机器),这个节点既作为名称节点(NameNode),也作为数据节点(DataNode),伪分布式模式配置涉及两个配置文件:hadoop目录/etc/hadoop/下的core-site.xml和hdfs-site.xml,首先在core-site.xml文件中新增如下属性:
<property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> #指定临时目录,如果不指定,会默认使用临时目录/tmp/hadoo-hadoop,这个文件在Hadoop重启时可能被清除 <description>Abase for other trmporary directories</description> </property> <property> <name>fs.defaultFS</name> #指定HDFS的访问地址 <value>hdfs://localhost:9000</value> </property>
然后在hdfs-site.xml中新增如下属性:
<property> <name>dfs.replication</name> #指定副本数量 <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> #name节点的存储位置 <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> #data节点的存储位置 <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property>
上面两个文件内涉及的属性名称和值得含义可以在Hadoop官网中查看:
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
和http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
完成了配置文件的修改后,就可以执行名称节点格式化(NameNode Format)了:
cd /usr/local/hadoop
./bin/hdfs namenode -format
如果格式化成功,会看到Exiting with status 0的提示
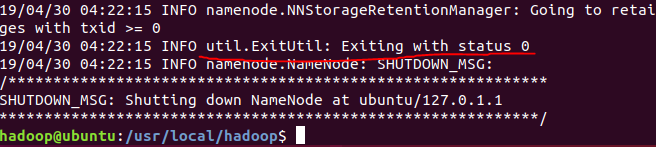
然后执行以下命令启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
在终端中执行jps(查看所有java进程pid)判断hadoop是否启动成功:
jps
如果执行成功,就可以看到如下几个进程:

至此,Hadoop伪分布式环境搭建成功
3.问题总结
1.DataNode没有启动
通过查阅资料https://blog.csdn.net/islotus/article/details/78357857,原因是:
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样就导致了datanode和namenode之间的ID不一致。
解决方法有两种,一是删除dfs文件(如果没有重要数据),二是在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可
应该在每一次运行结束Hadoop后,都关闭Hadoop
2.一定要关注权限问题
因为Linux下对用户权限有着严格的约束,用户A只有权访问/home/A/下的文件,用户B只有权访问/home/B/下的文件,如果A想要访问B的文件fileB,那么就要赋权给A,具体的方法有很多种,本文在刚开始执行名称节点格式化的过程中老是出错,就是因为没有注意权限问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号