Linux内核笔记:epoll实现原理(一)
一、说明
针对的内核版本为4.4.10。
本文只是我自己看源码的简单笔记,如果想了解epoll的实现,强烈推荐下面的文章:
The Implementation of epoll(1)
The Implementation of epoll(2)
The Implementation of epoll(3)
The Implementation of epoll(4)
二、epoll_create()
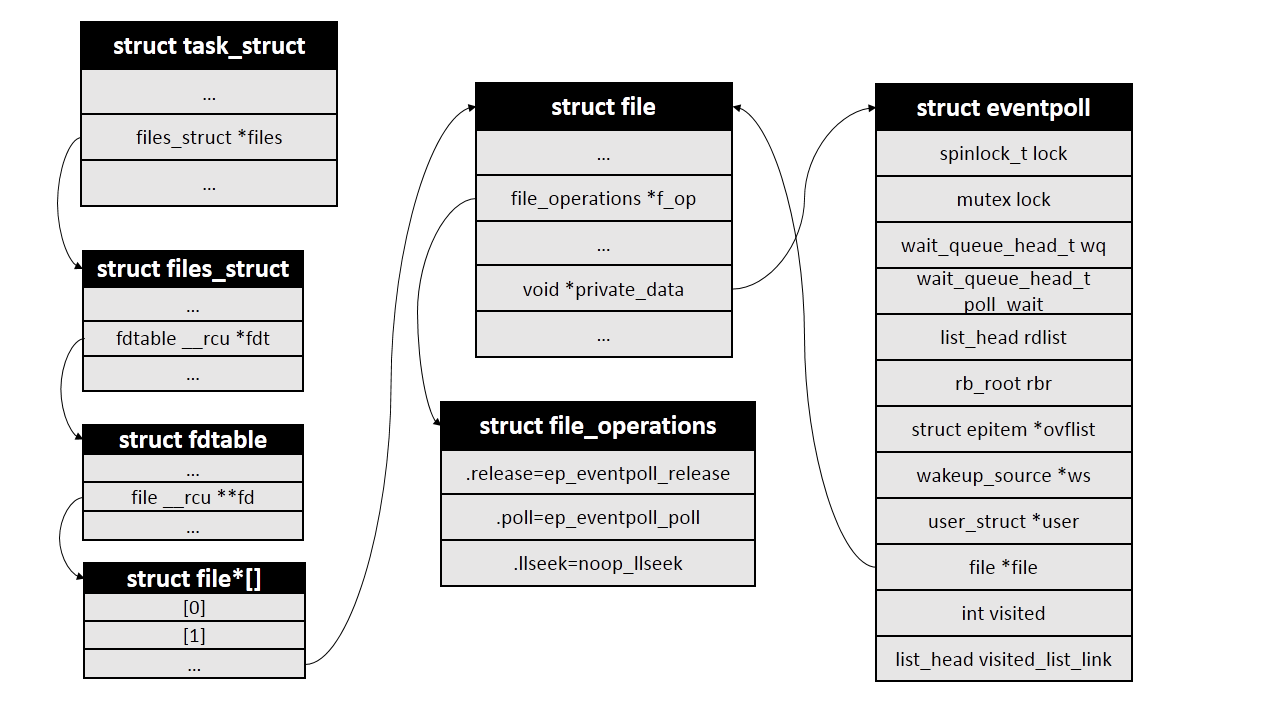
系统调用epoll_create()会创建一个epoll实例并返回该实例对应的文件描述符fd。在内核中,每个epoll实例会和一个struct eventpoll类型的对象一一对应,该对象是epoll的核心,其声明在fs/eventpoll.c文件中.
epoll_create的接口定义在这里,主要源码分析如下:
首先创建一个struct eventpoll对象:
struct eventpoll *ep = NULL;
...
error = ep_alloc(&ep);
if (error < 0)
return error;
然后分配一个未使用的文件描述符:
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}
然后创建一个struct file对象,将file中的struct file_operations *f_op设置为全局变量eventpoll_fops,将void *private指向刚创建的eventpoll对象ep:
struct file *file;
...
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep, O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
然后设置eventpoll中的file指针:
ep->file = file;
最后将文件描述符添加到当前进程的文件描述符表中,并返回给用户
fd_install(fd, file);
return fd;
操作结束后主要结构关系如下图:
三、epoll_ctl()
系统调用epoll_ctl()在内核中的定义如下,各个参数的含义可参见epoll_ctl的man手册
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd, struct epoll_event __user *, event)
epoll_ctl()首先判断op是不是删除操作,如果不是则将event参数从用户空间拷贝到内核中:
struct epoll_event epds;
...
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
ep_op_has_event()实际就是判断op是不是删除操作:
static inline int ep_op_has_event(int op)
{
return op != EPOLL_CTL_DEL;
}
接下来判断用户是否设置了EPOLLEXCLUSIVE标志,这个标志是4.5版本内核才有的,主要是为了解决同一个文件描述符同时被添加到多个epoll实例中造成的“惊群”问题,详细描述可以看这里。 这个标志的设置有一些限制条件,比如只能是在EPOLL_CTL_ADD操作中设置,而且对应的文件描述符本身不能是一个epoll实例,下面代码就是对这些限制的检查:
/*
*epoll adds to the wakeup queue at EPOLL_CTL_ADD time only,
* so EPOLLEXCLUSIVE is not allowed for a EPOLL_CTL_MOD operation.
* Also, we do not currently supported nested exclusive wakeups.
*/
if (epds.events & EPOLLEXCLUSIVE) {
if (op == EPOLL_CTL_MOD)
goto error_tgt_fput;
if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||
(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))
goto error_tgt_fput;
}
接下来从传入的文件描述符开始,一步步获得struct file对象,再从struct file中的private_data字段获得struct eventpoll对象:
struct fd f, tf; struct eventpoll *ep; ... f = fdget(epfd); ... tf = fdget(fd); ... ep = f.file->private_data;
如果要添加的文件描述符本身也代表一个epoll实例,那么有可能会造成死循环,内核对此情况做了检查,如果存在死循环则返回错误。这部分的代码目前我还没细看,这里不再贴出。
接下来会从epoll实例的红黑树里寻找和被监控文件对应的epollitem对象,如果不存在,也就是之前没有添加过该文件,返回的会是NULL。
struct epitem *epi; ... epi = ep_find(ep, tf.file, fd);
ep_find()函数本质是一个红黑树查找过程,红黑树查找和插入使用的比较函数是ep_cmp_ffd(),先比较struct file对象的地址大小,相同的话再比较文件描述符大小。struct file对象地址相同的一种情况是通过dup()系统调用将不同的文件描述符指向同一个struct file对象。
static inline int ep_cmp_ffd(struct epoll_filefd *p1,
struct epoll_filefd *p2) { return (p1->file > p2->file ? +1: (p1->file < p2->file ? -1 : p1->fd - p2->fd)); }
接下来会根据操作符op的不同做不同的处理,这里我们只看op等于EPOLL_CTL_ADD时的添加操作。首先会判断上一步操作中返回的epollitem对象地址是否为NULL,不是NULL说明该文件已经添加过了,返回错误,否则调用ep_insert()函数进行真正的添加操作。在添加文件之前内核会自动为该文件增加POLLERR和POLLHUP事件。
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tf.file, fd, full_check);
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
ep_insert()返回之后会判断full_check标志,该标志和上文提到的死循环检测相关,这里也略去。
四、ep_insert()
ep_insert()函数中,首先判断epoll实例中监视的文件数量是否已超过限制,没问题则为待添加的文件创建一个epollitem对象:
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
user_watches = atomic_long_read(&ep->user->epoll_watches);
if (unlikely(user_watches >= max_user_watches))
return -ENOSPC;
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
接下来是对epollitem的初始化:
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
if (epi->event.events & EPOLLWAKEUP) {
error = ep_create_wakeup_source(epi);
if (error)
goto error_create_wakeup_source;
} else {
RCU_INIT_POINTER(epi->ws, NULL);
}
接下来是比较重要的操作:将epollitem对象添加到被监视文件的等待队列上去。等待队列实际上就是一个回调函数链表,定义在/include/linux/wait.h文件中。因为不同文件系统的实现不同,无法直接通过struct file对象获取等待队列,因此这里通过struct file的poll操作,以回调的方式返回对象的等待队列,这里设置的回调函数是ep_ptable_queue_proc:
struct ep_pqueue epq; ... /* Initialize the poll table using the queue callback */ epq.epi = epi; init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); /* * Attach the item to the poll hooks and get current event bits. * We can safely use the file* here because its usage count has * been increased by the caller of this function. Note that after * this operation completes, the poll callback can start hitting * the new item. */ revents = ep_item_poll(epi, &epq.pt);
上面代码中结构体ep_queue的作用是能够在poll的回调函数中取得对应的epollitem对象,这种做法在Linux内核里非常常见。
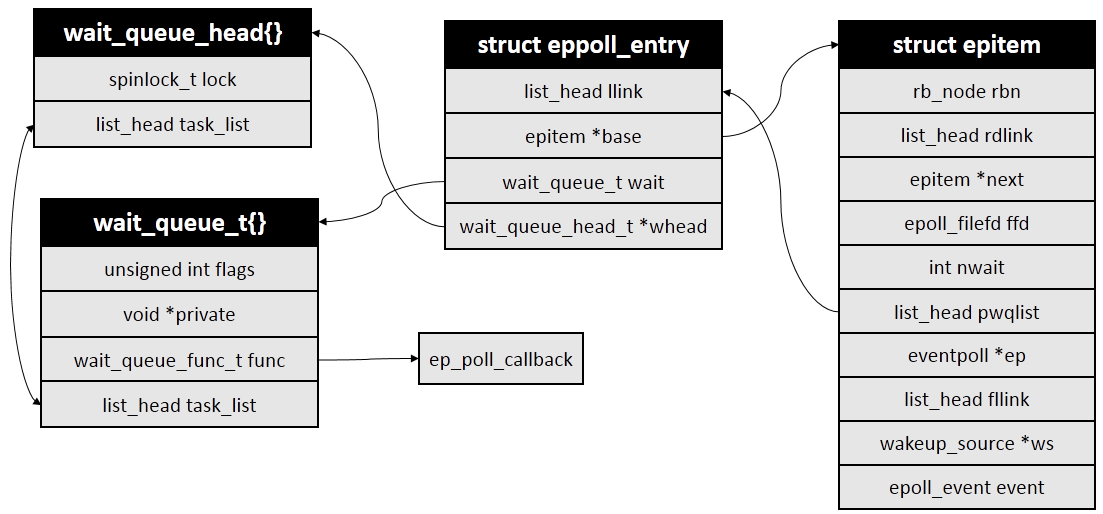
在回调函数ep_ptable_queue_proc中,内核会创建一个struct eppoll_entry对象,然后将等待队列中的回调函数设置为ep_poll_callback()。也就是说,当被监控文件有事件到来时,比如socker收到数据时,ep_poll_callback()会被回调。ep_ptable_queue_proc()代码如下:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
eppoll_entry和epitem等结构关系如下图:
在回到ep_insert()函数中。ep_item_poll()调用完成之后,会将epitem中的fllink字段添加到struct file中的f_ep_links链表中,这样就可以通过struct file找到所有对应的struct epollitem对象,进而通过struct epollitem找到所有的epoll实例对应的struct eventpoll。
spin_lock(&tfile->f_lock); list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links); spin_unlock(&tfile->f_lock);
然后就是将epollitem插入到红黑树中:
ep_rbtree_insert(ep, epi)
最后再更新下状态就返回了,插入操作也就完成了。
在返回之前还会判断一次刚才添加的文件是不是当前已经有事件就绪了,如果是就将其加入到epoll的就绪链表中,关于就绪链表放到下一部分中讲,这里略过。
最后是我画的几个结构体之间的结构图。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号