基于决策树的分类预测及重要参数
1.决策树的介绍
决策树是一种常见的分类模型,在金融分控、医疗辅助诊断等诸多行业具有较为广泛的应用。决策树的核心思想是基于树结构对数据进行划分,这种思想是人类处理问题时的本能方法。例如在婚恋市场中,女方通常会先看男方是否有房产,如果有房产再看是否有车产,如果有车产再看是否有稳定工作……最后得出是否要深入了解的判断。
决策树的主要优点:
具有很好的解释性,模型可以生成可以理解的规则。
可以发现特征的重要程度。
模型的计算复杂度较低。
决策树的主要缺点:
模型容易过拟合,需要采用减枝技术处理。
不能很好利用连续型特征。
预测能力有限,无法达到其他强监督模型效果。
方差较高,数据分布的轻微改变很容易造成树结构完全不同。
2.决策树构建的伪代码
决策树的构建过程是一个递归过程。函数存在三种返回状态:
(1)当前节点包含的样本全部属于同一类别,无需继续划分;
(2)当前属性集为空或者所有样本在某个属性上的取值相同,无法继续划分;
(3)当前节点包含的样本集合为空,无法划分。

3.划分选择
从上述伪代码中我们发现,决策树的关键在于line6.从A中选择最优划分属性a∗,一般我们希望决策树每次划分节点中包含的样本尽量属于同一类别,也就是节点的“纯度”更高。
1.信息增益
信息熵是一种衡量数据混乱程度的指标,信息熵越小,则数据的“纯度”越高。
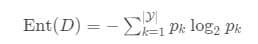
其中pk代表了第k类样本在D中占有的比例。

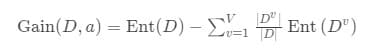
一般的信息增益越大,则意味着使用特征a来进行划分的效果越好。
2.基尼指数
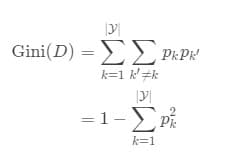
基尼指数反映了从数据集D中随机抽取两个的类别标记不一致的概率。
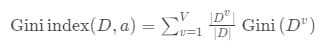
使用特征a对数据集D划分的基尼指数定义为上。
4.重要参数
1.criterion
Criterion这个参数正是用来决定模型特征选择的计算方法的。sklearn提供了两种选择:
输入”entropy“,使用信息熵(Entropy)
输入”gini“,使用基尼系数(Gini Impurity)
2.random_state & splitter
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显。splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
3.max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉。这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。
4.min_samples_leaf
min_samples_leaf 限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引起过拟合,设置得太大就会阻止模型学习数据。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号