tflite量化
tensorflow graphdefs to TensorFlow Lite's flat buffer format
tf、tflite存储格式不同,数据精度不同.
量化
量化好处自不必说了,减小模型大小,减少内存占用,提升速度,以及某些架构的硬件只支持int8,这时候必须量化.缺点就是模型精度有所下降.
量化也分很多种

不同的硬件设备所要求的量化方式是不同的,Edge TPU上只支持后两种.后两种都是要求有训练数据的.
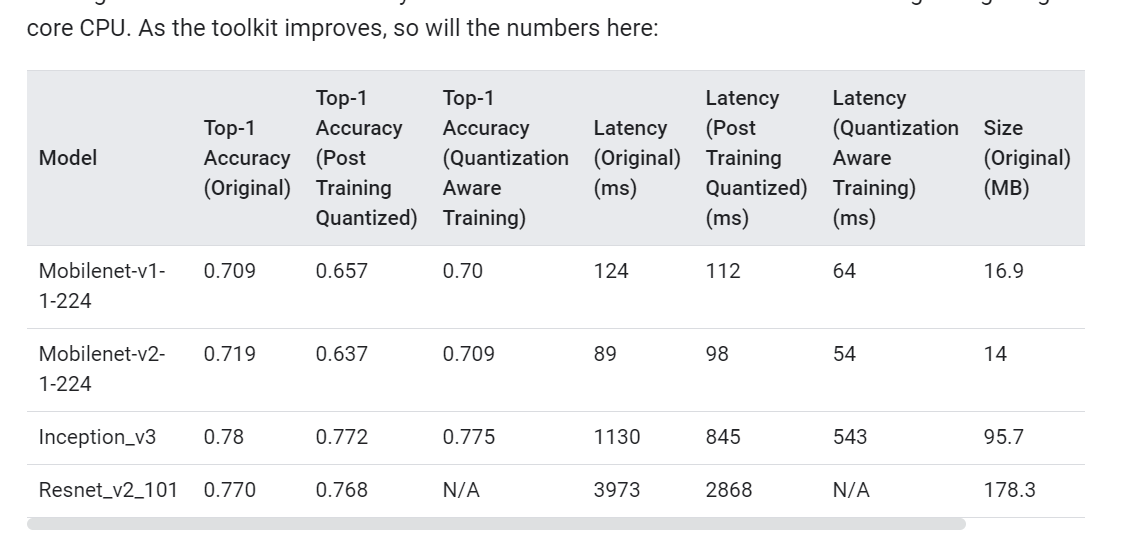
从上图看,post-training的量化方式对推理速度的提升很有限.
Post-training quantization
Post-training quantization也分很多种.
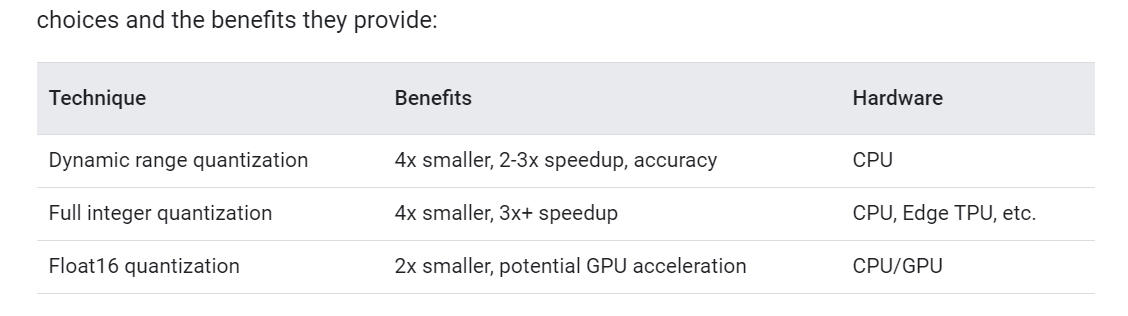
Edge TPU只能使用Full integer quantization.
Float16 quantization of weights
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.lite.constants.FLOAT16]
tflite_quant_model = converter.convert()
没啥说的,很少用.还不如直接fp32省心了,无非是减小点模型大小.
Dynamic range quantization
只能用于CPU加速
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
只把weights从fp32-->int8. 推理的时候,把int8转回fp32,用floating-point kernels做计算.

注意:However, the outputs are still stored using floating point, so that the speedup with dynamic-range ops is less than a full fixed-point computation

量化得到的模型只有weights是int8的,activation的部分依然是fp32的,activation输出的量化在推理的时候做,一个graph的不同部分用不同的kernel去处理.
Full integer quantization of weights and activations
you need to measure the dynamic range of activations and inputs by supplying a representative data set
要提供representative data set
模型的weights和activation全部转换为int8. 在cpu上速度提高3-4倍. 支持EDGE TPU上运行.
量化后的模型的input和output仍然是fp32的,对于activation op没有量化版本的实现的,会保留为fp32。
import tensorflow as tf
def representative_dataset_gen():
for _ in range(num_calibration_steps):
# Get sample input data as a numpy array in a method of your choosing.
yield [input]
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
对于没有量化版本实现的op就不量化了,保留为fp32.
对于Edge TPU这种只支持int8 op的硬件,必须模型里的op都是int8的.
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
通过指定converter属性要求必须全部op都转为int8的,否则直接报错.
int8<-->fp32
int8和fp32之间的映射关系如何确定,参考下面官方链接
https://www.tensorflow.org/lite/performance/quantization_spec
值得一看
https://zhuanlan.zhihu.com/p/99424468
https://blog.csdn.net/qq_19784349/article/details/82883271
https://murphypei.github.io/blog/2019/11/neural-network-quantization

