点云3d检测模型pointpillar
PointPillars
一个来自工业界的模型.https://arxiv.org/abs/1812.05784
3D目标检测通常做法
- 3d卷积
- 投影到前平面
- 在bird-view上操作
处理思路依然是3d转2d,先把3维的点云转成2d的伪图像.
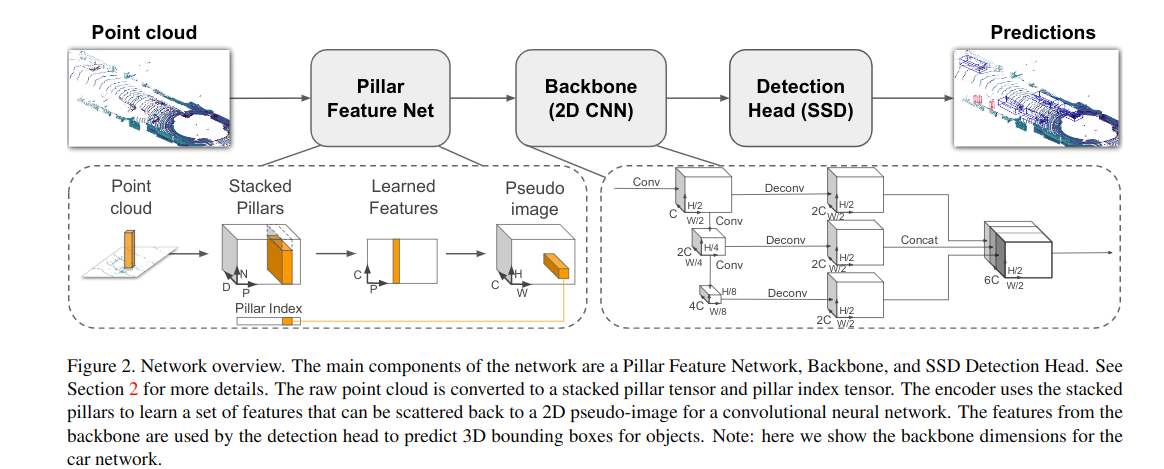
Feature Net
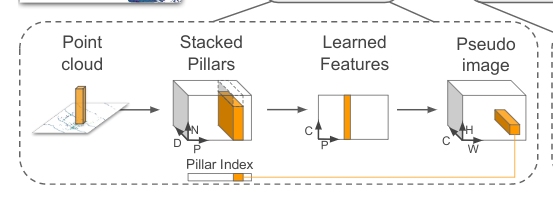
把点云数据处理成类似图像的数据.
pillar即柱子.点云的特性决定了每个柱子内的点是很稀少的.
一堆点,我们将其视为一个个柱子(即pillar),每个pillar内有很多points.所有的pillar内的point即组成了点云.
首先在x-y平面上投影出来一个h x w的网格.即划出h x w个pillar出来.
原始的点云数据point有(x,y,z,r)4个维度,r代表反射率.我们将其扩展为9个维度(x,y,z,r,x_c,y_c,z_c,x_p,y_p,带c下标的是点相对于柱子中的点的质心的偏差,带p下标的是对点相对于柱子物理中心的偏差。每个柱子中点多于N的进行采样,少于N的进行填充0。于是就形成了(D,P,N)D=9, N为每个pillar的采样点数(设定值),P为pillar总数目,H*W。
这样点云数据就表达成了一个(D,P,N)的Tensor.
然后卷积,得到一个(C,P,N)的Tensor.在N这个维度上做max operation.得到(C,P)的tensor.变形得到(C,H,W)tensor.
至此,我们就用一个(C,H,W)的tensor完成了点云数据的表达.
Backbone
backbone完成特征提取.
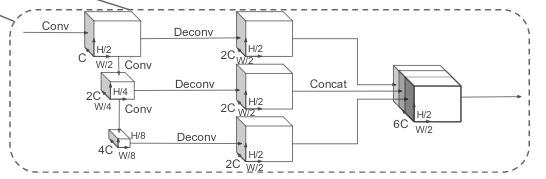
分为2部分
- top-down network产生空间分辨率逐步降低的feature map
- second network做upsample和concatenation,精细化feature.
top-down部分可以描述为一系列的block(S,L,F) S代表相对pseudo-image(即feature net得到的tensor)的stride. 一个block有L个3x3的2D卷积层. F代表输出的channel数目.
backbone输出的tensor为(6C,H/2,W/2)
Detection
用的ssd.高度z是单独回归的.

实验细节

点云转图像部分的C=64.backbone部分,车/人/自行车的S不一样.
loss设计
3d box由(x,y,z,w,l,h,theta)确定. 类似于2d box由(x,y,w,h)确定,3d box多了一个z方向的数据,以及一个角度,用以预计3d box的朝向(绕z轴的角度).
loss由3部分组成
- 定位loss,衡量3d box画的准不准
- 分类loss,衡量box内的物体类别判断准不准
- direction loss.定位loss虽说已经考虑了角度,但是不能区分flipped box.即比如一个3d box内的车,朝着正南和朝着正北走,标出来的3d box都是一样的.
定位loss:

分类loss:
focal loss通过对不同样本的loss赋予不同的权重,该权重是一个与当前样本预测概率相关的值.
系数为(1-p)的变种.从而达到p越小,loss权重越大的目的. 即放大hard example的loss.从而使得模型更好地适应难以分类的样本.

方向loss:
由softmax得到.

代码解析
todo
代码:https://github.com/traveller59/second.pytorch
python ./pytorch/train.py evaluate --config_path=./configs/car.fhd.config --model_dir=/path/to/model_dir --measure_time=True --batch_size=1

