轻量级CNN模型mobilenet v1
mobilenet v1
论文解读
论文地址:https://arxiv.org/abs/1704.04861
核心思想就是通过depthwise conv替代普通conv.

有关depthwise conv可以参考https://www.cnblogs.com/sdu20112013/p/11759928.html
模型结构:
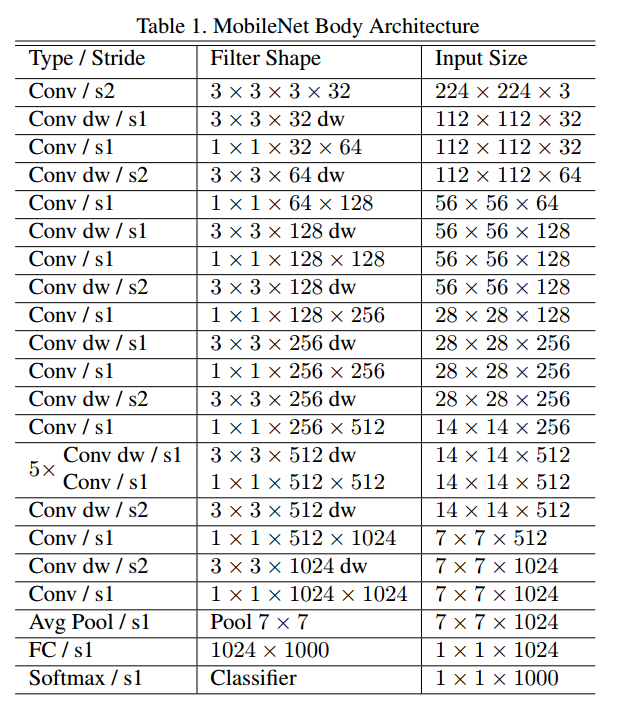
类似于vgg这种堆叠的结构.
每一层的运算量

可以看到,运算量并不是与参数数量绝对成正比,当然整体趋势而言,参数量更少的模型会运算更快.
代码实现
https://github.com/marvis/pytorch-mobilenet
网络结构:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
参考论文中的结构,第一层是普通的卷积层,后面接的都是可分离卷积.
这里注意groups参数的用法. 当groups=输入channel数目时,即对每个channel分别做卷积.默认groups=1,此时即为普通卷积.

训练伪代码
# create model
model = Net()
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
# load data
train_loader = torch.utils.data.DataLoader()
# train
for every epoch:
input,target=get_from_data
#前向传播得到预测值
output = model(input_var)
#计算loss
loss = criterion(output, target_var)
#反向传播更新网络参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
作者:sdu20112013
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎转载,转载请注明出处.

