各种杂记
局域网内扫描所有ip
扫描所有192.168.10网段的ip
nmap -sS 192.168.10.0/24
cat /proc/net/arp
conda&&pip设置国内源
https://blog.csdn.net/bornfree5511/article/details/106691526
色温调节软件
https://blog.csdn.net/DreamHome_S/article/details/78439098
https://blog.csdn.net/touch_dream/article/details/80499900
grep
递归查找目录下含有该字符串的所有文件
grep -rn "data_chushou_pay_info" /home/hadoop/nisj/automationDemand/
查找当前目录下后缀名过滤的文件
grep -Rn "data_chushou_pay_info" *.py
当前目录及设定子目录下的符合条件的文件
grep -Rn "data_chushou_pay_info" /home/hadoop/nisj/automationDemand/ *.py
结合find命令过滤目录及文件名后缀
find /home/hadoop/nisj/automationDemand/ -type f -name '*.py'|xargs grep -n 'data_chushou_pay_info'
pip install 挂死
https://stackoverflow.com/questions/52860913/pip-install-urllib3-hanging-on-caching-due-to-etag

sc@sc:~/.cache$ rm -r pip
删除pip cache文件.
top
VIRT:进程所使用的虚拟内存大小
RES:系统为虚拟内存分配的物理内存大小,包括file backed和anonymous内存,其中anonymous包含了进程自己分配和使用的内存,以及和别的进程通过mmap共享的内存;而file backed的内存就是指加载可执行文件和动态库所占的内存,以及通过private方式调用mmap映射文件所使用的内存(当在内存中修改了这部分数据且没有写回文件,那么这部分内存就变成了anonymous),这部分内存也可能跟别的进程共享。
SHR:RES的一部分,表示和别的进程共享的内存,包括通过mmap共享的内存和file backed的内存。当通过prive方式调用mmap映射一个文件时,如果没有修改文件的内容,那么那部分内容就是SHR的,一旦修改了文件内容且没有写回文件,那么这部分内存就是anonymous且非SHR的。
%MEM:等于RES/total*100%,这里total指总的物理内存大小。
注意:由于SHR可能会被多个进程所共享,所以系统中所有进程的RES加起来可能会超过总的物理内存数量,由于同样的原因,所有进程的%MEM总和可能超过100%。
从上面的分析可以看出,VIRT的参考意义不大,它只能反应出程序的大小,而RES也不能完全的代表一个进程真正占用的内存空间,因为它里面还包含了SHR的部分,比如三个bash进程共享了一个libc动态库,那么libc所占用的内存算谁的呢?三个进程平分吗?如果启动一个bash占用了4M的RES,其中3M是libc占用的,由于三个进程都共享那3M的libc,那么启动3个bash实际占用的内存将是3*(4-3)+3=6M,但是如果单纯的按照RES来算的话,三个进程就用了12M的空间。所以理解RES和SHR这两个数据的含义对我们在评估一台服务器能跑多少个进程时尤其重要,不要一看到apache的进程占用了20M,就认为系统能跑的apache进程数就是总的物理内存数除以20M,其实这20M里面有可能有很大一部分是SHR的。
注意:top命令输出中的RES和pmap输出中的RSS是一个东西。
https://segmentfault.com/a/1190000008125059
jetson nano
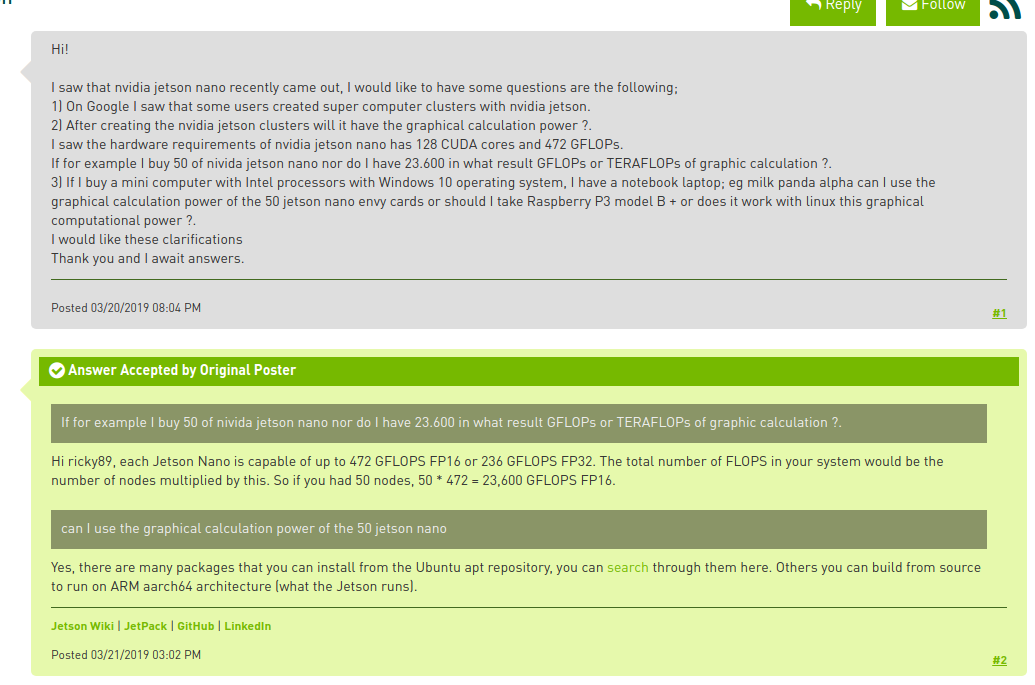
nvidia-docker安装
https://www.cnblogs.com/klausage/p/11865054.html
重装显卡驱动会导致nvidia-docker不见,但是之前创建的docker环境不会消失,只要重装nvidia-docker即可
文件过多时报错arguments list too long
find . -name "*.xml" -print0 | xargs -0 rm
find ./00012524 -type f -name "*.PDF" -exec cp {} ./dummy01/ ; -print
find -type f -name '*.txt' | wc -l
统计目录下文件个数
ls -l | grep "^-" | wc -l
http://noahsnail.com/2017/02/07/2017-02-07-Linux统计文件夹下的文件数目/
du配合sort查询目录大小
du -s * | sort -nr | head 选出排在前面的10个
du -s * | sort -nr | tail 选出排在后面的10个
时间相关
设置时间
date +%Y%m%d -s "20190618"
date +%T -s "14:29:00"
更改硬件时钟
sudo hwclock --set --date "mm/dd/yyyy hh:mm:ss"
sudo hwclock -s
具体查看sudo hwclock --help
ubuntu 18.04 开启ntp同步
timedatectl set-ntp yes
查看目录大小
du -hs /path/to/directory
- -h is to get the numbers "human readable", e.g. get 140M instead of 143260 (size in KBytes)
- -s is for summary (otherwise you'll get not only the size of the folder but also for everything in the folder separately)
- -d, --max-depth=N print the total for a directory (or file, with --all)
only if it is N or fewer levels below the command
line argument; --max-depth=0 is the same as
--summarize
权限相关
groups查看当前用户所属group

usermod改变user所属group

查看有哪些group
cat /etc/group

判断opencv版本
It worked for me like that in C++ : cout<<"OpenCV Version used:"<<CV_MAJOR_VERSION<<"."<<CV_MINOR_VERSION<<endl;
Makefile中输出信息
https://stackoverflow.com/questions/16467718/how-to-print-out-a-variable-in-makefile
$(info $$var is [${var}])
查看pip把包安装到哪里去了
pip show [package name]
查看某个package安装在什么位置
You can import the module and check the module.file string. It contains the path to the associated source file.
Alternatively, you can read the File tag in the the module documentation, which can be accessed using help(module), or module? in IPython.
查看新接入的usb设备名称
ls -1 /dev > ~/before.txt
插上设备
ls -1 /dev > ~/after.txt
diff ~/before.txt ~/after.txt
tty设备
http://www.voidcn.com/article/p-tkkjtere-vo.html
/dev/tty*设备open 失败
1.由于tty属于“dialout”组别,比如用户名是joeuser,先命令查看下用户隶属的组别
groups joeuser
2.如果没有隶属“dialout”,那么把用户加入进去
sudo gpasswd --add joeuser dialout
3.logout 再登录系统激活功能
shell 替换字符串
sed -i 's/old-text/new-text/g' input.txt
sed -i 's//home/sc/work_codes/yolo/320_320_yolov3_红绿灯//home/train/disk/data/g' input_autotune.txt
创建软链接
ln -s file filesoft //前面是目标文件名 后面是快捷方式名
ldconfig命令
ldconfig命令的用途主要是在默认搜寻目录/lib和/usr/lib以及动态库配置文件/etc/ld.so.conf内所列的目录下,搜索出可共享的动态链接库(格式如lib.so),进而创建出动态装入程序(ld.so)所需的连接和缓存文件。缓存文件默认为/etc/ld.so.cache,此文件保存已排好序的动态链接库名字列表,为了让动态链接库为系统所共享,需运行动态链接库的管理命令ldconfig,此执行程序存放在/sbin目录下。
ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库时,就需要手工运行这个命令。
检测某个函数是否存在于一个动态库中
nm xxx.so | grep "funcname"
查看cpu核心数目
lscpu
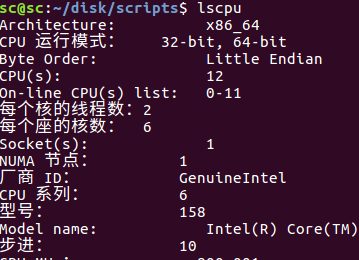
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
查看ubuntu版本
cat /etc/issue
lsb_release -a
protobuf多版本问题
PROTOC src/caffe/proto/caffe.proto
CXX .build_release/src/caffe/proto/caffe.pb.cc
In file included from .build_release/src/caffe/proto/caffe.pb.cc:5:0:
.build_release/src/caffe/proto/caffe.pb.h:17:2: error: #error This file was generated by an older version of protoc which is
#error This file was generated by an older version of protoc which is
^
.build_release/src/caffe/proto/caffe.pb.h:18:2: error: #error incompatible with your Protocol Buffer headers. Please
#error incompatible with your Protocol Buffer headers. Please
^
.build_release/src/caffe/proto/caffe.pb.h:19:2: error: #error regenerate this file with a newer version of protoc.
#error regenerate this file with a newer version of protoc.
The problem is that the installed headers on your system (in /usr/include/google/protobuf or /usr/local/include/google/protobuf) are from a newer version of Protocol Buffers than your protoc. It may be the case that you have both versions installed in different locations, and the wrong one is being used.
系统内的header file位于/usr/include/google/protobuf or /usr/local/include/google/protobuf
查看头文件版本
look at google/protobuf/stubs/common.h and look for the GOOGLE_PROTOBUF_VERSION macro around 100 lines in
-
虚拟环境创建
conda create --name env2.7 python=2.7 -
复制虚拟环境
conda create --name <env_name> --clone <name_to_be_copied> -
opencv安装
conda install -c menpo opencv -
为jupyter-notebook创建conda虚拟环境的kernal
https://blog.csdn.net/u014665013/article/details/81084604- conda install ipykernel
- conda activate env3.6
- (env3.6)python -m ipykernel install --user --name env3.6 --display-name "env3.6"
-
强制重新安装某个包
https://stackoverflow.com/questions/19548957/can-i-force-pip-to-reinstall-the-current-version
pip install --upgrade --force-reinstall numpy
循环执行某个命令
watch -n 5 ls backup_commonobj/
根据名字杀掉某个进程
ps aux | grep -ie 进程名字 | awk '{print $2}' | xargs kill -9
vscode配置
- ctrl + p 查找文件
- ctrl + shift + p 进入控制命令面板,查找vscode功能
- ctrl + shift + o 查看symbols. 变量/函数等.
- ctrl + alt + - 后退
- ctrl + l 选中整行
- 多行注释 选中多行 ctrl+k ctrl+c
添加inlcude path
ctrl + shift + p 进入控制命令面板


vscode打开一个目录后,会生成一个.vscode的目录,里面存放了临时的配置信息.只有打开这个目录,才会使用这些配置信息.

ubuntu18下vscode空格问题
ubuntu18下vscode空格距离太小.tab size改成几看起来缩进都是2个空格. 解决方案:安装字体
https://blog.csdn.net/kellncy/article/details/90345506
sudo apt install fonts-firacode
- 更改vscode的settings.json文件
// 以下两行必须
"editor.fontFamily": "'Fira Code'",
"editor.fontLigatures": true,
//下面四行分别设置不同粗细的字体,选择一种
// "editor.fontWeight": "300",// Light
// "editor.fontWeight": "400", // Regular
"editor.fontWeight": "500", // Medium
// "editor.fontWeight": "600", // Bold
列编辑模式
shift+alt+鼠标左键
添加ros插件
https://answers.ros.org/question/256565/how-to-add-ros-to-path-in-vs-code/
更改vscode默认的python解释器
file-preference-settings
latex语法
- LaTeX可以通过这符号\(^\) 和\(_\) 来设置上标和下标
- 开平方\sqrt{x}
http://mohu.org/info/symbols/symbols.htm
linux下鼠标变成十字
在Python操作的时候,没有输入Python命令进入到Python命令操作界面
而是直接在Terminal下面直接输入import导致鼠标被锁死变成十字
可以使用ps -e |grep import找到import进程的id
再执行命令kill -9 id 杀死进程即可!
vi用法及配置
vim全选,全部复制,全部删除
全选(高亮显示):按esc后,然后ggvG或者ggVG
全部复制:按esc后,然后ggyG
全部删除:按esc后,然后dG
解析:
gg:是让光标移到首行,在vim才有效,vi中无效
v : 是进入Visual(可视)模式
G :光标移到最后一行
选中内容以后就可以其他的操作了,比如:
d 删除选中内容
y 复制选中内容到0号寄存器
"+y 复制选中内容到+寄存器,也就是系统的剪贴板,供其他程序用
ubuntu18.04安装opencv
https://blog.csdn.net/qq_41080854/article/details/88609795
https://www.pyimagesearch.com/2018/05/28/ubuntu-18-04-how-to-install-opencv/
https://blog.csdn.net/GreenHandCGL/article/details/81452362
core文件不生成
echo "core.%e.%p" > /proc/sys/kernel/core_pattern

ros添加生成core文件
https://zhuanlan.zhihu.com/p/459530578
cmake
What's the CMake syntax to set and use variables?

cmake中换行不需要加'',直接换行即可.
set(CXX_SRCS
"src/Context.cpp"#不需要加空格
"src/trafficlights_detector.cpp"
"src/common_obj_detector.cpp"
"src/front_detector.cpp"
"src/main.cpp")
message(STATUS ${CXX_SRCS})
add_executable(front_detect ${CXX_SRCS})
这种每行也不需要加空格.
cmake添加命令行选项
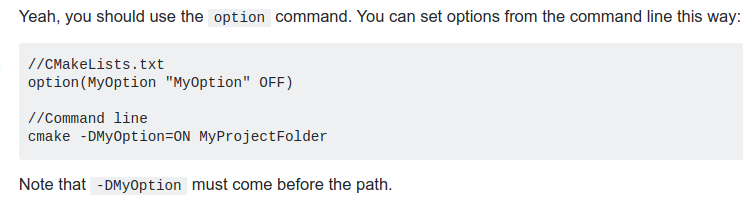
vi上下左右变成ABCD
https://blog.csdn.net/example440982/article/details/54956598
工业相机选型
https://www.cnblogs.com/harrypotterjackson/p/11431800.html
A5000 sm_86 error
https://github.com/pytorch/pytorch/issues/52288
conda create -n a6000 python=3.8 pytorch cudatoolkit=11.1 -c pytorch -c nvidia
A5000的算力过高,算力8.6(sm_86),需要安装匹配版本的torch. torch版本0.10.0+cu102,由于cuda10.2最高只支持到7.x ,所以需要安装0.10.0_cu111版本的torch才可以.
可以用torch.version.cuda查看
单独安装0.10.0+cu111的torchvision
conda install torchvision==0.10.0 cudatoolkit=11.1 -c pytorch
linux查看是x86架构还是arm架构
uname -m
查看opencv是否在使用gpu
https://stackoverflow.com/questions/61492452/how-to-check-if-opencv-is-using-gpu-or-not
print(cv2.getBuildInformation())
count = cv2.cuda.getCudaEnabledDeviceCount()
查询自己显卡对应的CUDA_ARCH_BIN
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
运行后输出如下:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Quadro P2200"
CUDA Driver Version / Runtime Version 11.2 / 11.1
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 5059 MBytes (5304745984 bytes)
(10) Multiprocessors, (128) CUDA Cores/MP: 1280 CUDA Cores
GPU Max Clock rate: 1493 MHz (1.49 GHz)
Memory Clock rate: 5005 Mhz
Memory Bus Width: 160-bit
L2 Cache Size: 1310720 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 98304 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.2, CUDA Runtime Version = 11.1, NumDevs = 1
Result = PASS
可以看cuda capability为6.1
nvidia gpu系列产品介绍
https://blog.csdn.net/zztflyer/article/details/100169374
各个版本的libtorch下载地址
https://blog.csdn.net/weixin_43742643/article/details/114156298
创建定时任务
crontab -e
编辑命令打开的文件
*/1 * * * * update.sh > 1.log
每隔一分钟执行一次update.sh,并将结果存入1.log
保存定时任务
crontab -l > my-crontab
在repo的根目录下:
git config credential.helper store
会在.git/config文件里生成如下内容
[credential]
helper = store
以后在git push的时候会记住用户名,密码.只有第一次需要手动输入
在一台电脑上配置多个github账号
https://gist.github.com/oanhnn/80a89405ab9023894df7
编辑~/.ssh/config
# Account 1 (work or personal) - the default config
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa
# Account 2 (work or personal) - the config we are adding
Host github-storrrrrrrrm
HostName github.com
User git
IdentityFile ~/.ssh/id_rsa_companyemail
在clone工程的时候改成git clone git@github-storrrrrrrrm:xxxx
在docker容器内部查看容器id
cat /proc/self/cgroup | head -1
jetson-xavier踩坑
xavier原生ubuntu1804+cuda10.2
ros2使用ubuntu2004
nvidia官方提供了一个galactic的镜像,本质上是在1804上手动编译了一个基础的ros2 galactic,很多第三方包是没有的.
如果做一个Ubuntu2004镜像,自己在里面手动安装ros,cuda,tensorrt,也会有问题,cuda10.2的官方是不支持ubuntu2004的,只能手动编译,而cuda10.2是不支持gcc7以上的.但是ubutu2004的默认gcc是9.

