工作记录
服务器上安装dnndk
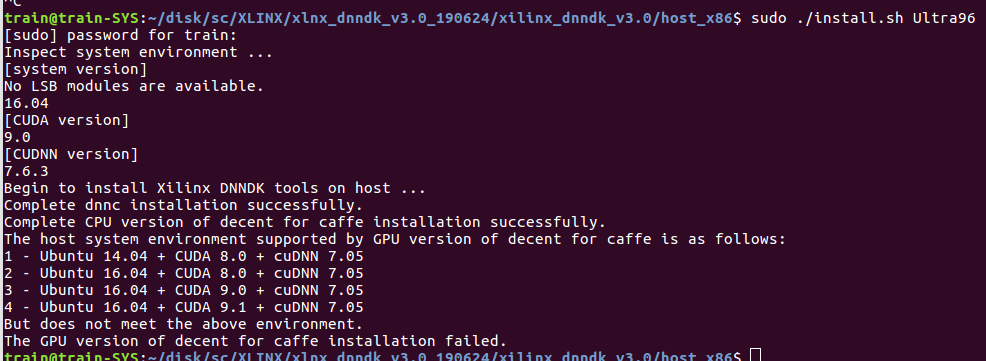
dnndk工具要求cuda9.0+cudnn7.0.5
xlinx板子推导yolov3

- 训练出yolov3.weights
- 把yolov3.cfg/yolov3.weights放到0_model_darknet
- bash 0_convert.sh
这一步会生成caffe模型.

- 测试模型转换的效果
这一步做不做意义不大. 因为我们训练用的darknet和xlinx提供的版本不一致,前处理可能不一样.导致用a版本训练的模型用b版本推导的时候结果错误严重.

做的话,要改0_test_darknet.sh脚本.或者不改脚本把5_file_for_test/coco.data改掉.

这里测试用的是xlinx提供的darknet. 训练用的darknet是alexyab版本的. 在图像的前处理上有一定差别. alexyab用了opencv.原版的没有使用. 所以对应不同的数据集,不同的的resize方式影响大小可能不同.

测试caffe模型的脚本也要改.
- 对caffe模型做量化 fp32-->int8
做量化的时候要提供一些校准图片.
#coding=utf-8
import random
import os
import shutil
def get_random_imgnames(dir,num):
"""
从目录dir下随机选出num张图片
"""
all_imgs = []
for img_name in os.listdir(dir):
if not img_name.endswith(".jpg"):
continue
#full_name = "{}/{}".format(dir,img_name)
all_imgs.append(img_name)
choosen_imgs = random.sample(all_imgs,num)
#print(choosen_imgs)
return choosen_imgs
def copy_imgs(choosen_imgs,dir1,dir2):
"""
把dir1内的img拷贝到dir2
"""
for img in choosen_imgs:
src = "{}/{}".format(dir1,img)
dst = "{}/{}".format(dir2,img)
shutil.copyfile(src,dst)
def test(dir,num,dir2):
"""
从dir内选出num张图片,拷贝到dir2内.
"""
imgs = get_random_imgnames(dir,num)
copy_imgs(imgs,dir,dir2)
##生成cal
f = open("calib.txt","w")
for img in os.listdir(dir2):
f.writelines("{} 1\n".format(dir2,img))
f.close()
def main():
"""
生成xlinx模型转换fp32-->int8时所需要的校准文件.
"""
test("/home/train/disk/sc/data2/LISA_BDD_APOLLO/",100,"/home/train/disk/sc/XLINX/darknet2caffe/docs/Darknet-Caffe-Conversion/example_common_obj/5_file_for_test/calib_data")
main()
生成校准文件calib.txt.拷贝到5_file_for_test目录下.
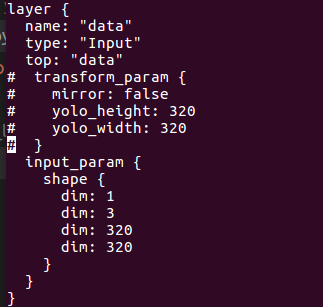
把第三部生成的caffe32的v3.prototxt和v3.caffemodel拷贝到目录2_model_for_quantize下.并修改v3.prototxt
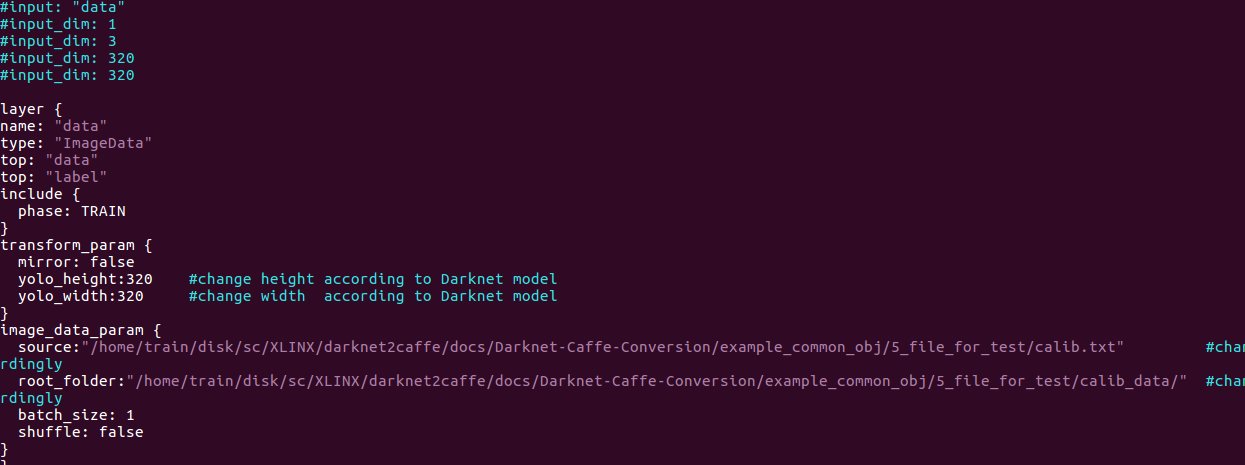
这里xlinx查找图片是把root_folder + source里的名字拼在一起的. 注意source里的内容是图像名字,不需要全路径了. root_folder注意结尾要有/
这一步做完后会生成int8的caffe模型.

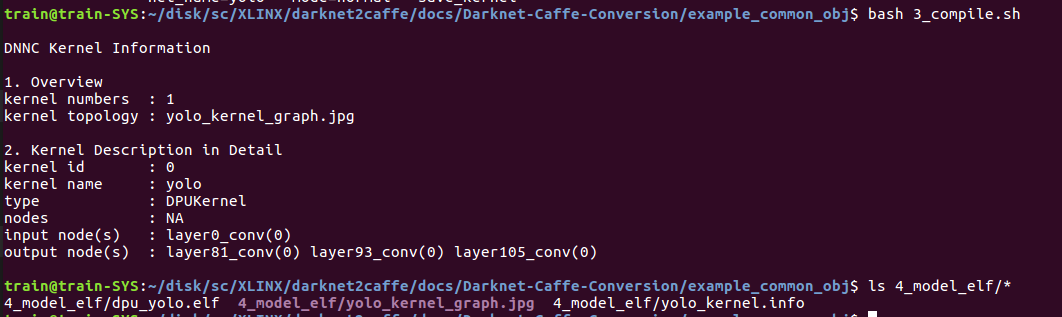
- 把模型编译成elf
3_model_after_quantize$ vi deploy.prototxt
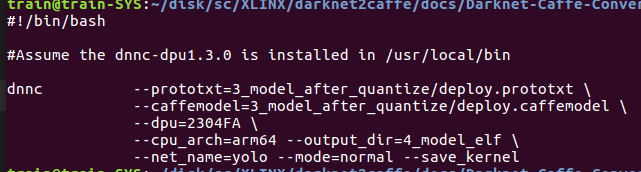
ultra96对应的dpu=2304FA net_name随便取.
这一步之后就会生成dpu_yolo.elf在目录4_model_elf下
ultra96环境搭建
opencv3.3安装
dnndk v3.0
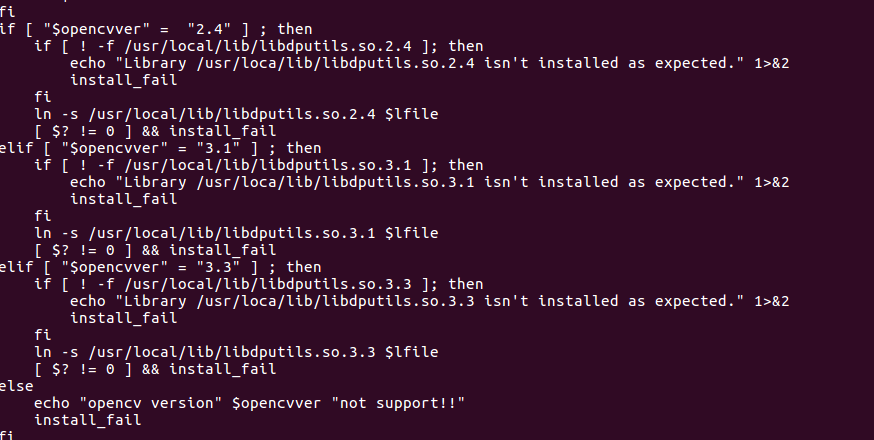

只支持3个版本的opencv.
debian仓库的opencv版本是3.2
https://packages.debian.org/search?searchon=sourcenames&keywords=opencv
卸载掉 系统自带的opencv3.2
系统自带的opencv3.2
apt-get autoremove libopencv-dev python-opencv
opencv3.3.1安装参考:
https://gist.github.com/danigosa/367b8a8cbc8d883df80c5c071423e4b2
######################################
# INSTALL OPENCV ON UBUNTU OR DEBIAN #
######################################
# 1. KEEP UBUNTU OR DEBIAN UP TO DATE
sudo apt-get -y update
sudo apt-get -y upgrade
sudo apt-get -y dist-upgrade
sudo apt-get -y autoremove
# 2. INSTALL THE DEPENDENCIES
# Build tools:
sudo apt-get install -y build-essential cmake
# GUI (if you want to use GTK instead of Qt, replace 'qt5-default' with 'libgtkglext1-dev' and remove '-DWITH_QT=ON' option in CMake):
sudo apt-get install -y qt5-default libvtk6-dev
# Media I/O:
sudo apt-get install -y zlib1g-dev libjpeg-dev libwebp-dev libpng-dev libtiff5-dev libjasper-dev libopenexr-dev libgdal-dev
# Video I/O:
sudo apt-get install -y libdc1394-22-dev libavcodec-dev libavformat-dev libswscale-dev libtheora-dev libvorbis-dev libxvidcore-dev libx264-dev yasm libopencore-amrnb-dev libopencore-amrwb-dev libv4l-dev libxine2-dev
# Parallelism and linear algebra libraries:
sudo apt-get install -y libtbb-dev libeigen3-dev
# Python:
sudo apt-get install -y python-dev python-tk python-numpy python3-dev python3-tk python3-numpy
# Java:
sudo apt-get install -y ant default-jdk
# Documentation:
sudo apt-get install -y doxygen
# 3. INSTALL THE LIBRARY (YOU CAN CHANGE '3.3.1' FOR THE LAST STABLE VERSION)
sudo apt-get install -y unzip wget
wget https://github.com/opencv/opencv/archive/3.3.1.zip
unzip 3.3.1.zip
rm 3.3.1.zip
mv opencv-3.3.1 OpenCV
cd OpenCV
mkdir build
cd build
cmake -DWITH_QT=ON -DWITH_OPENGL=ON -DFORCE_VTK=ON -DWITH_TBB=ON -DWITH_GDAL=ON -DWITH_XINE=ON -DBUILD_EXAMPLES=ON -DENABLE_PRECOMPILED_HEADERS=OFF ..
make -j4
sudo make install
sudo ldconfig
出错:
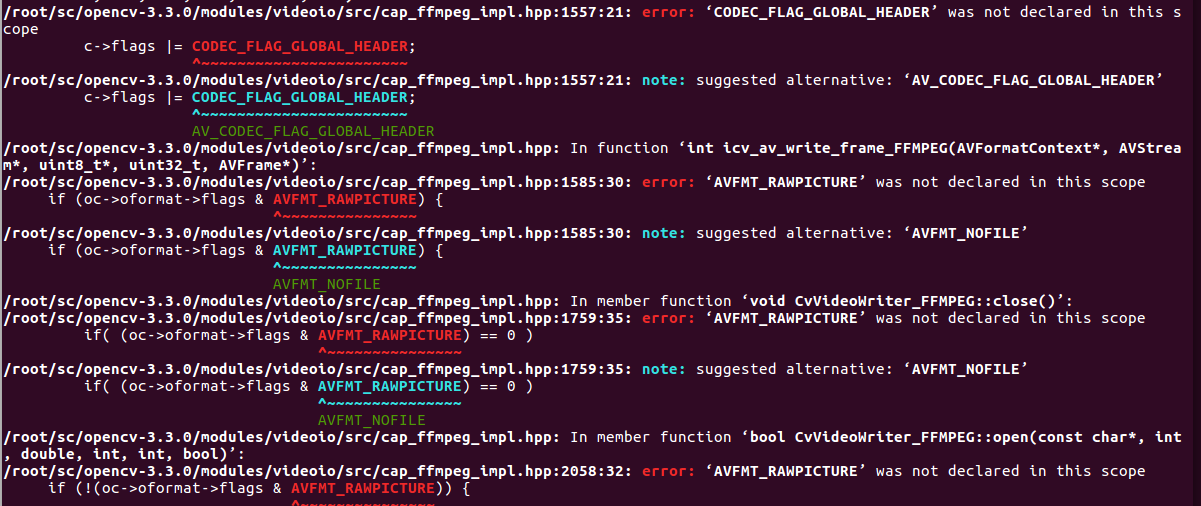
参考https://stackoverflow.com/questions/46884682/error-in-building-opencv-with-ffmpeg
#define AV_CODEC_FLAG_GLOBAL_HEADER (1 << 22)
#define CODEC_FLAG_GLOBAL_HEADER AV_CODEC_FLAG_GLOBAL_HEADER
#define AVFMT_RAWPICTURE 0x0020

在编译python模块的时候各种问题,下面的方案不确定ok不ok.
编译cv2.cpp出错const char* to char*的话就按照编译器提示把源码改掉.
最后
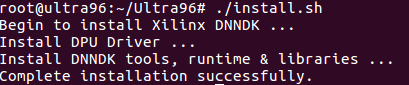
dnndk v3.0安装
ros安装
http://wiki.ros.org/melodic/Installation/Source
Traceback (most recent call last):
File "/opt/ros/melodic/bin/catkin_make", line 13, in <module>
from catkin.terminal_color import disable_ANSI_colors, fmt
File "/opt/ros/melodic/lib/python2.7/dist-packages/catkin/terminal_color.py", line 2, in <module>
from catkin_pkg.terminal_color import * # noqa
ImportError: No module named terminal_color
apt install --reinstall python-catkin-pkg python-catkin-pkg-modules
rosdep install --from-paths src --ignore-src --rosdistro melodic -y --os=debian:buster


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架