VGG16
版权声明:本文为博主原创文章,未经博主允许不得转载。 <a class="copy-right-url" href=" https://blog.csdn.net/loveliuzz/article/details/79135546"> https://blog.csdn.net/loveliuzz/article/details/79135546</a>
</div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-3019150162.css">
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-3019150162.css">
<div class="htmledit_views" id="content_views">
一、VGG-16网络框架介绍
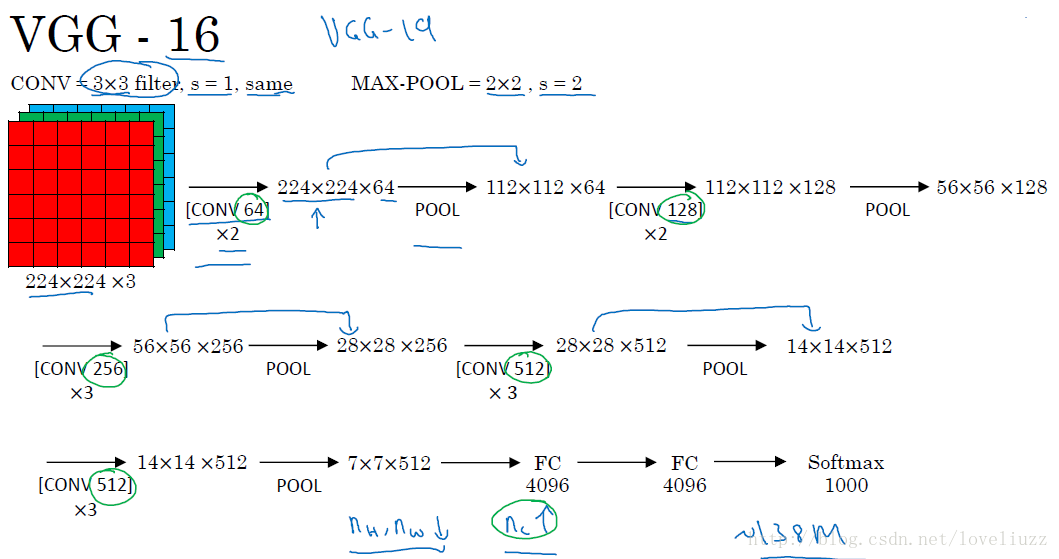
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,
VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,
VGGNet论文中全部使用了3*3的小型卷积核和2*2的最大池化核,通过不断加深网络结构来提升性能。
VGG-16和VGG-19结构如下:


总结:
(1)VGG-16网络中的16代表的含义为:含有参数的有16个层,共包含参数约为1.38亿。
(2)VGG-16网络结构很规整,没有那么多的超参数,专注于构建简单的网络,都是几个卷积层后面跟一个可以压缩
图像大小的池化层。即:全部使用3*3的小型卷积核和2*2的最大池化层。
卷积层:CONV=3*3 filters, s = 1, padding = same convolution。
池化层:MAX_POOL = 2*2 , s = 2。
(3)优点:简化了卷积神经网络的结构;缺点:训练的特征数量非常大。
(4)随着网络加深,图像的宽度和高度都在以一定的规律不断减小,
每次池化后刚好缩小一半,信道数目不断增加一倍。
二、整体架构代码实现
用VGG_6.py文件实现前向传播过程以及网络的参数:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- # Author:ZhengzhengLiu
-
- import tensorflow as tf
-
- #VGG_16全部使用3*3卷积核和2*2的池化核
-
- #创建卷积层函数
- def conv_op(input_op,name,kh,kw,n_out,dh,dw,p):
- """
- param :
- input_op -- 输入tensor
- name -- 该层的名称
- kh -- 卷积核的高
- kw -- 卷积核的宽
- n_out -- 卷积核数目/输出通道数
- dh -- 步长的高
- dw -- 步长的宽
- p -- 参数(字典类型)
- return:
- A -- 卷积层的输出
- """
- n_in = input_op.get_shape()[-1].value #输入的通道数
-
- with tf.variable_scope(name) as scope:
- weights = tf.get_variable(name=scope+"w",shape=[kh,kw,n_in,n_out],dtype=tf.float32,
- initializer=tf.contrib.layers.xavier_initializer_con2d())
- biases = tf.get_variable(name=scope+"b",shape=[n_out],dtype=tf.float32,
- initializer=tf.constant_initializer(0.0),trainable=True)
- conv = tf.nn.conv2d(input=input_op,filter=weights,strides=[1,dh,dw,1],padding="SAME")
- Z = tf.nn.bias_add(conv,biases)
- A = tf.nn.relu(Z,name=scope)
-
- p[name+"w"] = weights
- p[name+"b"] = biases
-
- return A
-
- #创建最大池化层的函数
- def maxpool_op(input_op,name,kh,kw,dh,dw):
- """
- param :
- input_op -- 输入tensor
- name -- 该层的名称
- kh -- 池化核的高
- kw -- 池化核的宽
- dh -- 步长的高
- dw -- 步长的宽
- return:
- pool -- 该层的池化的object
- """
- pool = tf.nn.max_pool(input_op,ksize=[1,kh,kw,1],strides=[1,dh,dw,1],padding="SAME",name=name)
- return pool
-
- #创建全连接层的函数
- def fc_op(input_op,name,n_out,p):
- """
- param :
- input_op -- 输入tensor
- name -- 该层的名称
- n_out -- 输出通道数
- p -- 参数字典
- return:
- A -- 全连接层最后的输出
- """
- n_in = input_op.get_shape()[-1].value
- with tf.variable_scope(name) as scope:
- weights = tf.get_variable(name=scope+"w",shape=[n_in,n_out],dtype=tf.float32,
- initializer=tf.contrib.layers.xavier_initializer())
- # biases不再初始化为0,赋予一个较小的值,以避免dead neuron
- biases = tf.get_variable(name=scope+"b",shape=[n_out],dtype=tf.float32,
- initializer=tf.constant_initializer(0.1))
- #tf.nn.relu_layer对输入变量input_op与weights做矩阵乘法加上biases,再做非线性relu变换
- A = tf.nn.relu_layer(input_op,weights,biases,name=scope)
-
- p[name + "w"] = weights
- p[name + "b"] = biases
-
- return A
-
- #构建VGG_16网络的框架
- def VGG_16(input_op,keep_prob):
- """
- param :
- input_op -- 输入tensor
- keep_prob -- 控制dropout比率的占位符
- return:
- fc8 -- 最后一层全连接层
- softmax -- softmax分类
- prediction -- 预测
- p -- 参数字典
- """
- p = {} #初始化参数字典
-
- #第一段卷积网络——两个卷积层和一个最大池化层
- #两个卷积层的卷积核大小为3*3,卷积核数量均为64,步长s=1,输出均为:224*224*64
- conv1_1 = conv_op(input_op,name="conv1_1",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
- conv1_2 = conv_op(conv1_1,name="conv1_2",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
- #最大池化层采用的尺寸大小为:2*2,步长s=2,输出为:112*112*64
- pool1 = maxpool_op(conv1_2,name="pool1",kh=2,kw=2,dh=2,dw=2)
-
- # 第二段卷积网络——两个卷积层和一个最大池化层
- # 两个卷积层的卷积核大小为3*3,卷积核数量均为128,步长s=1,输出均为:112*112*128
- conv2_1 = conv_op(pool1,name="conv2_1",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
- conv2_2 = conv_op(conv2_1,name="conv2_2",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
- # 最大池化层采用的尺寸大小为:2*2,步长s=2,输出为:56*56*128
- pool2 = maxpool_op(conv2_2,name="pool2",kh=2,kw=2,dh=2,dw=2)
-
- # 第三段卷积网络——三个卷积层和一个最大池化层
- # 三个卷积层的卷积核大小为3*3,卷积核数量均为256,步长s=1,输出均为:56*56*256
- conv3_1 = conv_op(pool2,name="conv3_1",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
- conv3_2 = conv_op(conv3_1,name="conv3_2",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
- conv3_3 = conv_op(conv3_2,name="conv3_3",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
- # 最大池化层采用的尺寸大小为:2*2,步长s=2,输出为:28*28*256
- pool3 = maxpool_op(conv3_3,name="pool3",kh=2,kw=2,dh=2,dw=2)
-
- # 第四段卷积网络——三个卷积层和一个最大池化层
- # 三个卷积层的卷积核大小为3*3,卷积核数量均为512,步长s=1,输出均为:28*28*512
- conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- conv4_3 = conv_op(conv4_2, name="conv4_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- # 最大池化层采用的尺寸大小为:2*2,步长s=2,输出为:14*14*512
- pool4 = maxpool_op(conv4_3, name="pool4", kh=2, kw=2, dh=2, dw=2)
-
- # 第五段卷积网络——三个卷积层和一个最大池化层
- # 三个卷积层的卷积核大小为3*3,卷积核数量均为512,步长s=1,输出均为:14*14*512
- conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- conv5_2 = conv_op(conv5_1, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- conv5_3 = conv_op(conv5_2, name="conv5_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
- # 最大池化层采用的尺寸大小为:2*2,步长s=2,输出为:7*7*512
- pool5 = maxpool_op(conv5_3, name="pool5", kh=2, kw=2, dh=2, dw=2)
-
- # 第六、七段 —— 含4096个隐藏节点的全连接层及dropout
- pool5_shape = pool5.get_shape().as_list()
- flattened_shape = pool5_shape[1] * pool5_shape[2] * pool5_shape[3]
- dense = tf.reshape(pool5, shape=[-1, flattened_shape],name="dense") # 向量化
-
- fc6 = fc_op(dense,name="fc6",n_out=4096,p=p)
- fc6_drop = tf.nn.dropout(fc6,keep_prob=keep_prob,name="fc6_drop")
-
- fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p)
- fc7_drop = tf.nn.dropout(fc7, keep_prob=keep_prob, name="fc7_drop")
-
- #最后一层输出层含1000个节点,进行softmax分类
- fc8 = fc_op(fc7_drop,name="fc8",n_out=1000,p=p)
- softmax = tf.nn.softmax(fc8)
- prediction = tf.argmax(softmax,1)
-
- return prediction,softmax,fc8,psamsan
三、用slim实现VGG_16网络的代码如下:
- def vgg16(inputs):
- with slim.arg_scope([slim.conv2d, slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
- weights_regularizer=slim.l2_regularizer(0.0005)):
- net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
- net = slim.max_pool2d(net, [2, 2], scope='pool1')
- net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
- net = slim.max_pool2d(net, [2, 2], scope='pool2')
- net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
- net = slim.max_pool2d(net, [2, 2], scope='pool3')
- net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
- net = slim.max_pool2d(net, [2, 2], scope='pool4')
- net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
- net = slim.max_pool2d(net, [2, 2], scope='pool5')
- net = slim.fully_connected(net, 4096, scope='fc6')
- net = slim.dropout(net, 0.5, scope='dropout6')
- net = slim.fully_connected(net, 4096, scope='fc7')
- net = slim.dropout(net, 0.5, scope='dropout7')
- net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8')
- return net
作者:sdu20112013
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎转载,转载请注明出处.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号