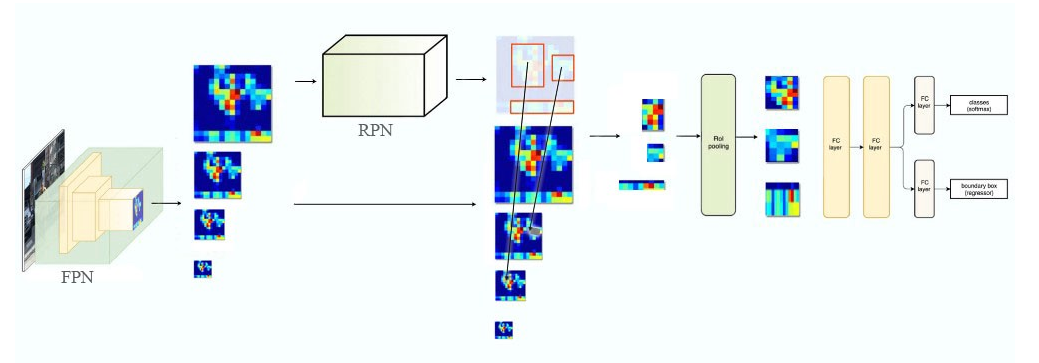
特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更难识别.
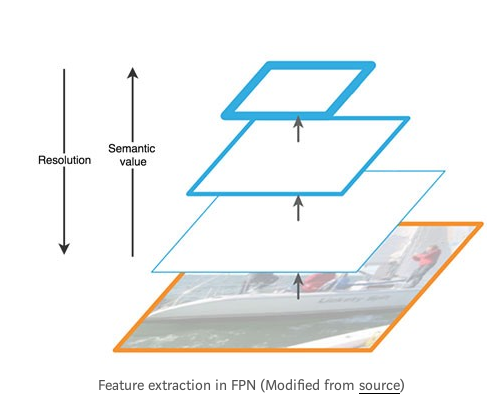
说回到cnn,不断地卷积以后,feature map的尺寸变小.这时候feature map所代表的语义信息已经很丰富了,如果绘图绘制出来,可能会看见代表的是某种形状,颜色,或更高级的更抽象的概念了.但是由于feature map尺寸减小,所以检测小目标困难.
我们可以用同一图片,不同尺寸内容相同的同一幅图分别训练多个feature map,但是这么搞会及其耗时,并且需要大量内存.在实时性要求高的场景下是不能这么搞的.这就引入了FPN的概念
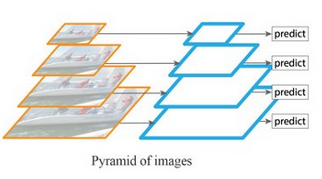
Feature Pyramid Networks (FPN)
特征金字塔网络(FPN)是根据特征金字塔概念设计的特征提取器,目的是提高精度和速度.它替代了类如Faster R-CNN中的特征提取器,并且生成更高质量的特征图金字塔.
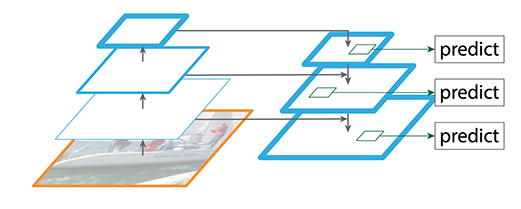
经过一系列的卷积以后得到了feature map,我们通过上采样,再一步步还原回去,在保证高级语义信息没丢的情况下,还把feature map的size搞大了.然后用大size的feature map去检测小目标.从而解决小目标难以检测的问题.
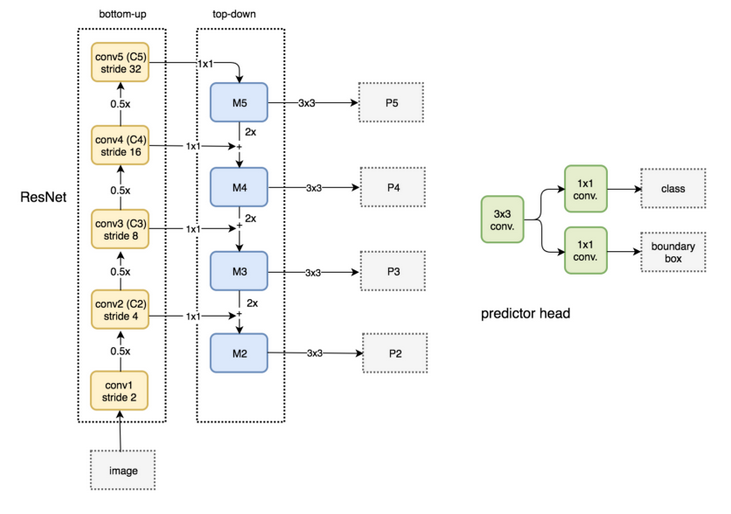
FPN由自下而上和自上而下两部分构成.自下而上的就是传统的卷积网络做特征提取,随着卷积的深入,空间分辨率减少,空间信息丢失.但是高级语义信息被更多地检测到.
ssd从依据多个feature map来做预测,但是底层的layer并没有选中做object detetion.底层的具有high resolution,但是不具备高级语义high semantic.ssd为了提高速度,在predict的时候不用比较底层的feature map.这一点也导致了它对小目标的检测效果不好.
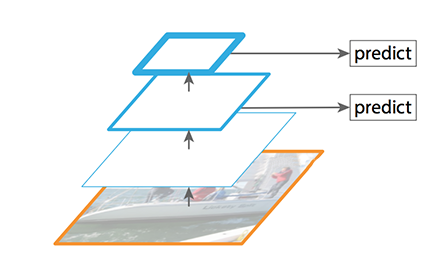
FPN提供了一种自上而下的路径,去构建higher resolution layer from a semantic rich layer.
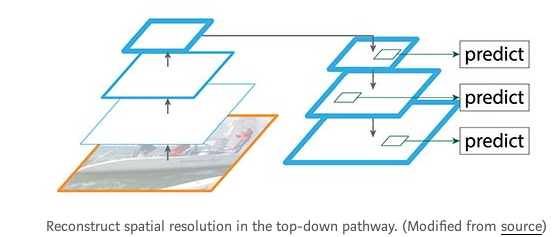
这样构建出来的层具有high resolution的同时又有丰富的语义rich semantic.但是由于经过了不断地上采样下采样,object的位置已经不准确了.
所以我们在重新构建出来的层和相应的feature map之间构建横向连接,以使得检测器可以更好地预测location.
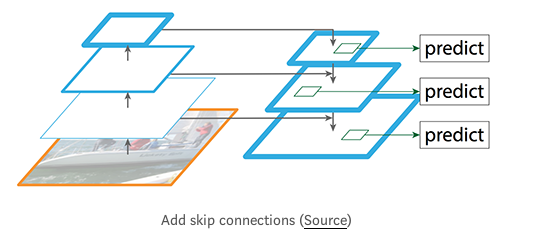
下面是自下而上和自上而下的路径图.P2,P3,P4,P5是object detection所需的金字塔feature map.
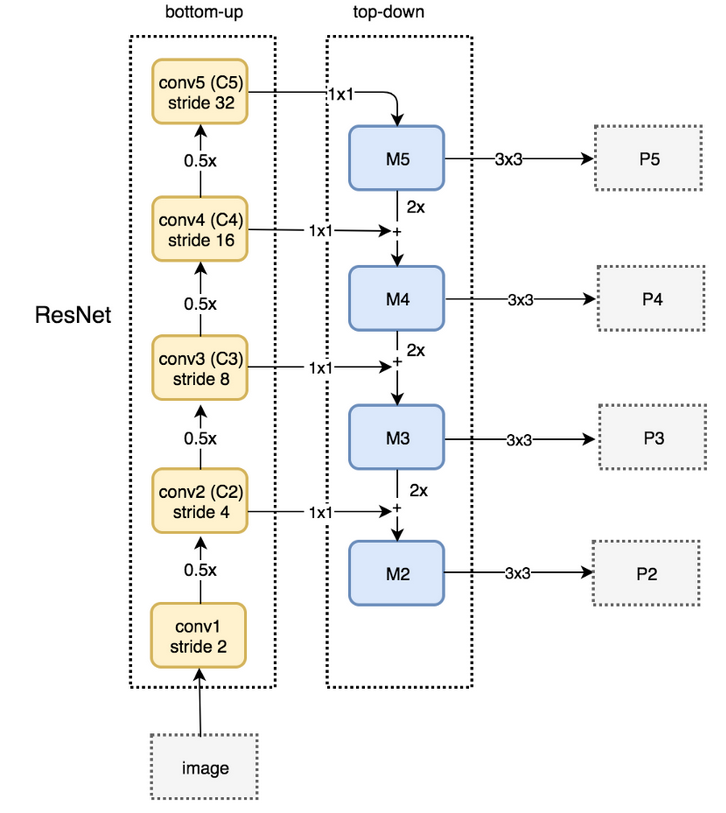
FPN with RPN
FPN本身并不是object detetcor.它只是一个feature detetor.下图显示FPN在一个object detector中的位置和作用. 每一个feature map(P2到P5)被独立地送到后续的流程完成object detection.
FPN with Fast R-CNN or Faster R-CNN
通过FPN,生成了feature map的金字塔(也就是一堆不同尺寸的特征图,都具有高级语义).然后用RPN生成ROI.然后对不同尺寸的目标,选用不同尺寸的特征图去做识别.小目标要用大尺寸的feature map. 大目标用小尺寸的feature map.很好理解,目标很小,你再用小尺寸(低分辨率)的feature map,肯定更难看清目标了.