深度学习的一些思考
本文记录一些对深度学习的思考总结.意识流写法,想到哪写到哪,日后不定期更新补充.
在没有接触深度学习的时候,觉得这是个非常高大上的技术,数学基础要求非常多,上手门槛非常高.我想很多人和我有一样的想法.这种对深度学习的印象,我想很大一部分来自铺天盖地的自媒体的有关AI的报道解读,造成了一种深度学习,人工智能非常高大上的感觉. 实际上媒体人没有相关的理论基础,甚至没有工科背景,文章写出来又要吸引人能带流量,有时又难免夸大,各种名词什么神经网络,人工智能,梯度爆炸,并行计算优化,对没有接触过相关技术的人来说,很容易造成一种很高大上很神秘的印象.
其实,神经网络并不是什么新鲜的东西,早几十年就有了,卷积也不是什么新鲜东西,在模式识别,图像处理里也早就应用广泛. 现如今,深度学习大红大紫,还是因为时代发展到了这个阶段,算力的发展,芯片的发展,更快的gpu的出现,更好的计算优化技术,互联网时代我们有了大量的数据,这些都使得卷积神经网络的训练成为可能,而不是仅仅在理论层面.大量的训练数据,使得深度学习在很多业务领域有了更好的表现,尤其是图像处理方面。
深度学习的本质
先说结论:本质就寻找最合适的卷积核,最合适的特征权重,最大限度拟合训练样本。本质是计算。
以图像处理为例,传统的方法怎么做的? 手工提取特征 + 传统机器学习. 深度学习怎么做的?端到端的学习,不再需要手工提取特征了,自己学习特征.
比如下面这幅图,你很容易就认出来这是一只猫.

你有没有想过,你的大脑是怎么识别出来这是一只猫的?通过眼睛,耳朵,嘴巴,尾巴,腿?还是通过这些的组合?这里的"耳朵,嘴巴,尾巴"等等就是所谓的"特征"。虽然你并没有意识到你的大脑经过了一系列复杂的运算,但它确实是经过了一系列复杂的运算,然后告诉你这是一个猫。只不过神经元的速度太快了,你意识不到而已.
对计算机而言,上面的图就是一堆数字而已,比如800*600的图,就是一个800*600*3的矩阵,为了简化表达,就用灰度图来说吧,那就是800*600的矩阵,矩阵里相应元素的值代表着像素值.当然"像素值"这个概念,也是我们人为赋予的,计算机才不care什么像素值不像素值,对它来说,就是个数字而已.
那问题来了,什么样的数字代表"猫的眼睛",什么样的数字代表"猫的耳朵"?以前这个工作是手工去做的.现在是神经网络自动去做的.
比如对连续5个像素,值为1,34,67,89,213,我就认为这5个像素代表猫头,这个规则是我事先定义好的.(当然这是我瞎定义的,这5个像素当然不能代表猫头)。手工去做的时候,你需要理解业务,比如识别车和识别猫,(1,34,67,89,213)在猫的图片里可能代表猫头,在车子图片里可能代表车屁股,其含义是不同的.这就麻烦了,不同的领域,规则不同,而且,特征工程就是他娘的玄学啊,特征成千上万,找也找不完,好的特征和坏的特征对最后的识别结果带来的影响千差万别,怎么衡量该重点考虑哪种特征?.
而对深度学习来说,输入就是一堆数字而已,它不懂数字代表的业务含义,它也不需要懂,它只要尝试出最合适的卷积矩阵,使得loss最小就行,前面也说了,本质是计算。
这里也可以看到,传统的方法和深度学习的方法,在思路上就是完全两种思路. 前者更看着规则的定义,也就是特征的提取. 后者则更看重输入的数据,只要你输入的数据够多,质量够好,我就能自动提取出有效的特征和权重.(当然,这个意义也是我们人为赋予的,学习出来的其实就是一堆数而已,我们把他们称之为特征,这个时候,他们不再代表猫头、耳朵等等了,可能就是一个点,一条线,肉眼看去已经无法理解了,如下图)

这也是前面提到的,深度学习之所以站到了历史的台前的两大原因之一:海量的数据。
现在就涉及到卷积的概念了.
卷积

为什么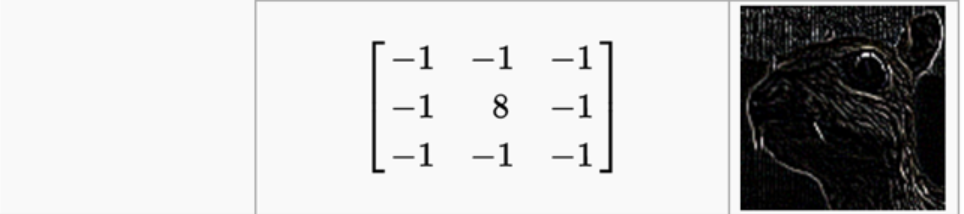
这个卷积核能起到边缘检测的作用?想想你是怎么去判断图像边缘的?如果给你一副纯色图,有边缘吗?
比如
显然没有啊。因为纯色图,矩阵的每一个像素值都一样的,所以分不出边缘.看出来了吧,你通过判断与周边像素的差别来判断是不是边缘.差别越大越有可能是边缘.现在在看上面的卷积核,很清楚了吧,经过卷积运算(不懂卷积运算的,先看看置顶的那篇https://www.cnblogs.com/sdu20112013/p/10149529.html) .每一个像素值x都变成了8*x + (-1)*周边像素,即8*x -周边像素。这可不就是在比较当前像素和周边像素的差值吗?所以卷积完的矩阵,绘图绘制出来,就有了边缘的效果.
按照这个思路,不难理解为什么不同的卷积核会有不同的效果了,也就是不同的特征被我们提取出来了.很多人设计好了很多卷积核,分别完成不同的功能.传统的图像处理,就是去使用这些卷积核,再配以规则,完成适配自己业务领域数据的特征提取.
好,重点来了.上面说了,"边缘"这个特征被提取出来了,那对这个代表图像边缘的矩阵,叫matrix_a吧,继续找一个卷积矩阵kenerl_a,对其做卷积,得到matrix_b,这个martrix_b什么意义呢?再对这个martrix_b做卷积,得到martrix_c,这个martix_c又代表啥呢?答案是我们不知道,像上面提到的,最终的矩阵绘制出来,可能已经是一个点,一条线了,我们已经无法肉眼识别他们在现实世界的对应物体了.但并不代表这是无意义的,不同于猫的眼睛,耳朵等等这些高级特征,这时候得到的这些点啊线啊,已经是非常抽象的低级特征了.而图片正是由这些大量的低级特征组成的.
深度学习干的啥事?就是寻找成千上万的卷积核,得到成千上万的特征,然后用分类也好,回归也罢,认为我们的目标=特征权重*特征之和.比如obj=0.3*feature1 + 0.5*feature2,obj=1代表猫,obj=2代表狗. 这样拿到一个新的图片,输入给模型,模型通过卷积就计算出对应的feature1,feature2,然后计算obj,然后我们就知道了这张图是猫和狗.
当然,卷积核不是瞎找的,卷积核矩阵里面的数字到底填几,要是一个个瞎试,再牛逼的gpu,再牛逼的芯片也试不完啊.这里面就涉及到损失函数定义,梯度下降了.
详细的去看我机器学习的文章吧,不想看的就知道模型学习的过程里,卷积核的值填什么不是随机乱填的,每次反向传播更新卷积核的时候都是朝着让loss更小,也就是让模型更准确(所谓更准确,是针对你的训练数据来说的,同样的网络结构,你机器上跑出来的模型的参数和别人跑出来的模型参数是不一样的,如果你们的训练数据不一样的话)这样一个目标去更新的就完了.
怎么设计出一种滤波器/卷积核
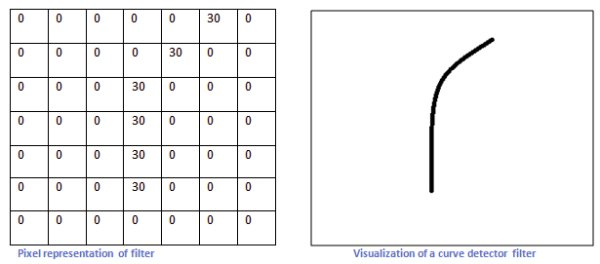
比如上图的卷积核可以识别右边的曲线.道理也是很显然的,上图的卷积核的形状就是类似我们想要的曲线的形状的.如果遇到类似形状的图像,卷积(对应位置像素值相乘再相加)之后得到的数会很大,反之很小.这样就把想要的形状的曲线识别出来了.
与信号处理的关系
大学的时候,学信号处理,天天就是各种傅里叶变换,完全不知道有啥用.说实在的,大学的很多老师水平其实也不咋地,基本就是照本宣科,要么放万年不变的PPT,可能自己都不能深刻理解,或者与产业界太脱离,完全不讲这些理论的现实应用.其实讲清楚这些现实意义也没那么难么.所以还在上学的同学们,要好好学习啊,要好好学习啊,要好好学习啊,重要的事情说三遍,你现在以为没用的东西,不知道哪天就派上用场了.
现在回头看,卷积不就是离散的傅里叶变换吗. 从信号的角度理解卷积,卷积核不就是滤波器吗,卷积核对图像的作用,不就是对图像这种信号做滤波吗.啥叫滤波,其实也就是特征提取。
傅里叶变换将时域和空域信息-->转换到频域上. 对图像处理而言,我们处理的大部分时候是空域的信息.说人话就是空间信息,对单帧图像而言,我们卷积出来的特征,点也好,线也罢,是一种形状,是空间上的信息. 连续的图像才存在这时间信息,多帧图像是有联系的,比如视频,时域信息就很重要了.
https://www.zhihu.com/question/20099543/answer/13971906
首先说说图像频率的物理意义。图像可以看做是一个定义为二维平面上的信号,该信号的幅值对应于像素的灰度(对于彩色图像则是RGB三个分量),如果我们仅仅考虑图像上某一行像素,则可以将之视为一个定义在一维空间上信号,这个信号在形式上与传统的信号处理领域的时变信号是相似的。不过是一个是定义在空间域上的,而另一个是定义在时间域上的。所以图像的频率又称为空间频率,它反映了图像的像素灰度在空间中变化的情况。例如,一面墙壁的图像,由于灰度值分布平坦,其低频成分就较强,而高频成分较弱;而对于国际象棋棋盘或者沟壑纵横的卫星图片这类具有快速空间变化的图像来说,其高频成分会相对较强,低频则较弱(注意,是相对而言)。
https://www.zhihu.com/question/29246532
图像傅里叶变换如何理解?
所以对于数组来说,数字之间变化剧烈,代表高频,柔和代表低频.同理,对于图像来说,那就是灰度变化快的是高频,慢的是低频.比如一个物体的边缘,就是高频信号,物体内部,就是低频.而傅立叶变换无非是告诉你这副图像上XXX频率的信号有多少多少, YYY的频率有多少多少.那换句话说就是,图像的傅立叶变换可以让你直观的看到这幅图总体上"剧烈"的变化有多少,"柔和"的变化有多少.一副整体很模糊的图,傅立叶变换后显示的低频分量就很多一副整体灰度变化很剧烈的图,傅立叶变换后显示的高频分量就很多同理,如果你在频域上将高频分量去掉,再反变换回去,那图片就会变的模糊.
图像的空间信息丢掉了是什么意思
先看CNN中全连接层参数是怎么来的.参考https://zhuanlan.zhihu.com/p/33841176.
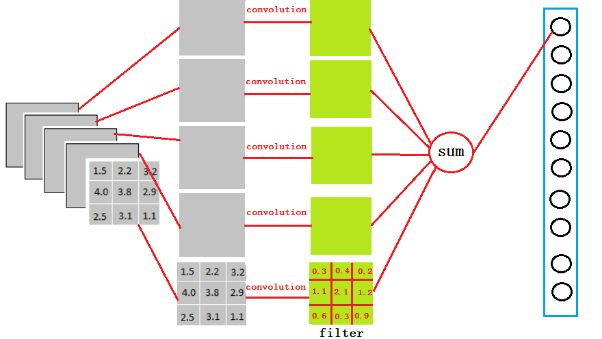
以VGG-16举例,在VGG-16全连接层中,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程。
这样做会有什么好处和问题?
好处和坏处是一样的,就是去除掉位置信息的影响.主要看你处理的是什么问题.对分类来说,我们不关心位置,希望某种像素组合被识别为某种特征,我们不在乎这种像素组合在图片矩阵的什么位置出现,我都要能识别它,这时候就是好处.
但是对于图像分割来说,就是坏处了.因为我需要知道位置信息.比如需要知道图片里的猫在左上角还是右下角,这样才能准确分割.所以分割模型会用卷积层替代掉全连接层.
在我写这篇文章的时候,我做了一点google,想看看有没有人写过类似的主题,发现有2篇文章写的很好,我也引用了部分图,推荐之。
- http://www.hankcs.com/ml/understanding-the-convolution-in-deep-learning.html
- https://blog.csdn.net/DL_CreepingBird/article/details/78574133
图片和概率分布的关系
图片是什么?是一堆像素.比如64 X 64 X 3的图有大概12K个像素. 那我们可以把图片理解为12K维空间里的一个点.
现在说回概率分布
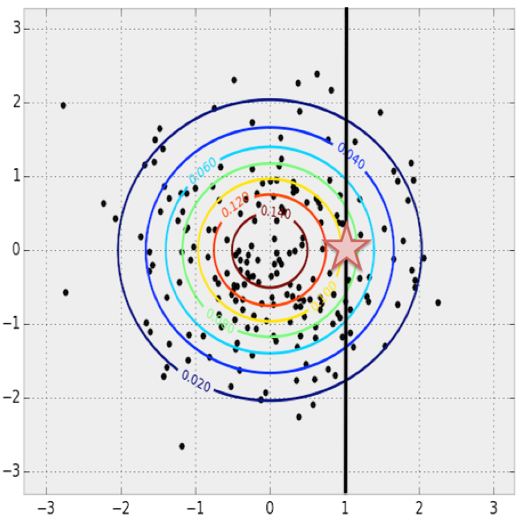
以二维空间为例,当x=1的时候,可能对应着很多点.那最有可能的y是多少呢?其实也就是x=1时,最密集的点在什么位置. 显然这个可以通过已有样本统计得到.
扩展到高维空间,其实道理是一样的.首先我们有了很多很多图片,也就是说我们有了很多很多12K维的样本,这样的话我们就能得到概率分布,从而可以根据这个分布去填充马赛克图片里的马赛克部分,使得数据最大程度地拟合前面统计出来的概率分布.
很有意思的文章,研究卷积核得到的输出可视化是什么样子的.cnn究竟是如何去组合不同的细节信息的.
https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号