招聘市场上 自然语言处理工程师都得会点啥
以boss直聘https://www.zhipin.com/上面搜索nlp为例,我们抓取数据,探索一下市场上对nlp人才的需求.
代码放在https://github.com/sdu2011/nlp.你可以稍加改造,看看自己所在地区,目标职位都要求一些什么技能.
以南京地区的nlp岗位为例.
- 要抓取职位列表.获取招聘方信息.抓取到职位详情页面的url。
- 要抓取职位详情,解析详情,分词,统计,提取关键词等
- 可视化. seaborn wordcloud等图形化展示.
数据抓取与清洗
这部分就不多谈了.主要要了解一些爬虫知识.html页面的解析库BeatifulSoup用法.这一步"脏活比较多",主要就是分析各种html的tag的格式,去除空格啦,提取各种tag下信息啦之类的数据清洗工作.
current_url = "https://www.zhipin.com/job_detail/?query=nlp&scity=101190100&industry=&position="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
,'Connection': 'keep-alive'
}
r=requests.get(current_url,headers=headers)
def parse_job_detail(url):
r=requests.get(url,headers=headers)
bs = BeautifulSoup(r.text,"html.parser")
h3=bs.find("h3",text="职位描述")
#print(h3.find_next_sibling("div"))
div_tag = h3.find_next_sibling("div")
#print(div_tag.text)
requirements = []#任职要求
responsbility = []#岗位职责
require_flag = False
responsbility_flag = False
for c in div_tag.children:
#print(c,type(c))
if type(c) is bs4.element.NavigableString:
str_no_space = c.string.replace(" ","")
#print(str_no_space)
if str_no_space.find("任职要求") != -1: #这边不能用==判断 因为前面由于中文字符的问题 replace替换不掉:后面的blank
responsbility_flag = False
require_flag = True
continue
if str_no_space.find("岗位职责") != -1: #这边不能用==判断 因为前面由于中文字符的问题 replace替换不掉:后面的blank
require_flag = False
responsbility_flag = True
continue
if require_flag:
requirements.append(str_no_space)
if responsbility_flag:
responsbility.append(str_no_space)
#print(requirements)
#print(responsbility)
return (requirements,responsbility)
#parse_job_detail("https://www.zhipin.com/job_detail/84e81e27c933269e1Xxz3dq1E1I~.html?ka=search_list_1")
def get_jobs_info(url):
r=requests.get(url,headers=headers)
bs = BeautifulSoup(r.text,"html.parser")
jobs = []
for job in bs.find_all("div",class_="job-primary"):
#print("**************************************************************")
one_job = []
for child in job.descendants:
if child.name == 'div'and child['class'] == ['info-primary']:
jobdetails = parse_job_detail("https://www.zhipin.com/%s" % (child.h3.a.get('href')))
one_job.append(child.h3.div.text) #title
#print(one_job)
one_job.append(child.h3.span.text) #salary
#one_job.append(child.h3.a.get('href')) #link
one_job.append(jobdetails[0]) #requirements
one_job.append(jobdetails[1]) #responsbility
index = 0
for c in child.p:
if index == 0:
#print(c)
one_job.append(c) #地区
elif index == 2:
#print(c)
one_job.append(c) #经验
elif index == 4:
#print(c)
one_job.append(c) #学历
index += 1
elif child.name == 'div' and child['class'] == ['info-company']:
#print(child.a.string)
index = 0
for c in child.p:
if index == 0:
#print(c) #行业
one_job.append(c)
elif index == 2:
#print(c) #公司发展阶段 A/B/C/D轮/上市
one_job.append(c)
elif index == 4:
#print(c) #规模
one_job.append(c)
index += 1
pass
#print(one_job)
jobs.append(one_job)
return jobs
jobs_info=get_jobs_info("https://www.zhipin.com/job_detail/?query=nlp&scity=101190100&industry=&position=")
数据抓取完成后
数据探索
这部分,需要对pandas,seaborn有一些了解.
下面我们就可以用seaborn对数据做可视化处理了.
解决sns显示中文字体的问题 from matplotlib.font_manager import FontProperties myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=14) sns.set(font=myfont.get_name())
- 学历
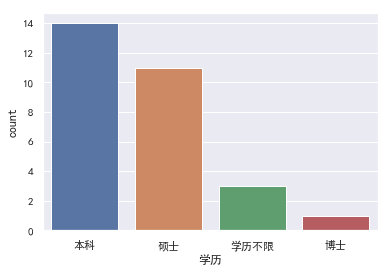
先来看看学历的要求.(说到这我就心痛,为什么当初要放弃读研,真想抽自己两耳光!!!! 直接导致了现在接近一半的职位连门槛都跨不进去)。
可以看到NLP工程师对学历的要求还是比较高,图标里硕士学历要求基本接近40%.实际上,要接近50%,因为有的岗位在职位搜索页面标注的是本科即可,但是实际上职位详情里又说明了要求硕士.
所以,有志于NLP的小伙伴能读研的还是读研吧,有志于NLP的小伙伴能读研的还是读研吧,有志于NLP的小伙伴能读研的还是读研吧,重要的事情说三遍.
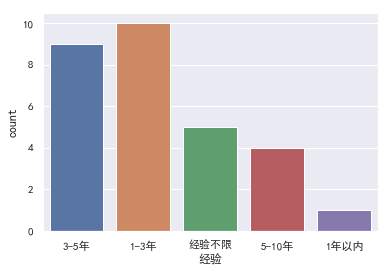
- 经验.
可以看到3年左右经验是比较受欢迎的.这也符合常识,首先NLP这几年是随着深度学习的发展开始火起来,经验特别丰富的从业者并不多.而且,不光是NLP,别的岗位也是3/5/8年比较吃香,因为此时你已经是这个级别的熟练工种了.
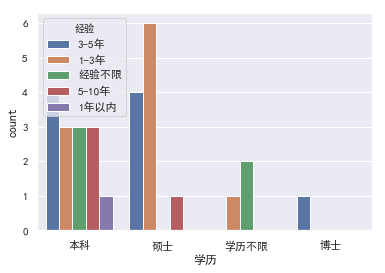
- 学历+经验
依然类似的结论,在各个学历下,都是3年左右的需求比较多.
- 规模
首先,千人以上的公司招聘需求相对大,比较好理解. 比较意外的是100-499的中小公司招聘需求相对较多.可能是最近几年随着深度学习的兴起,很多AI相关业务的A轮/B轮的创业公司.
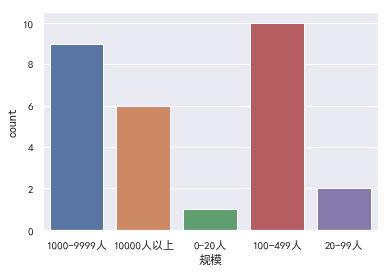
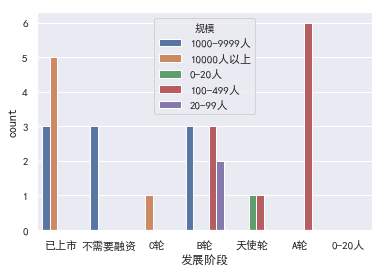
验证一下我们上面的猜测,100-499规模中,A/B轮的比较多.
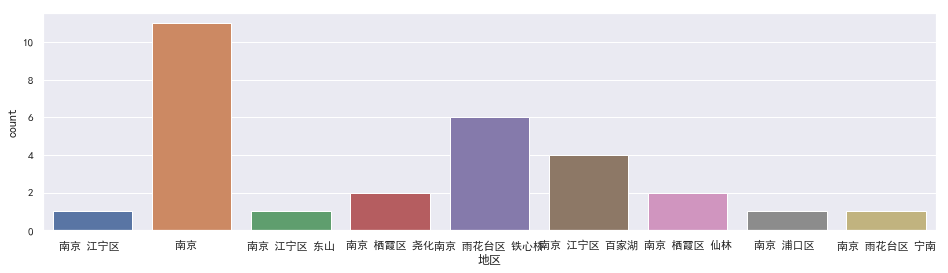
- 地区
排除没有标明具体地区的,剩下的雨花台铁心桥一带需求最多,因为那边是"宇宙的中心",大量的科技公司和码农聚集到软件大道一带. 剩下的江宁区的岗位也相对多.
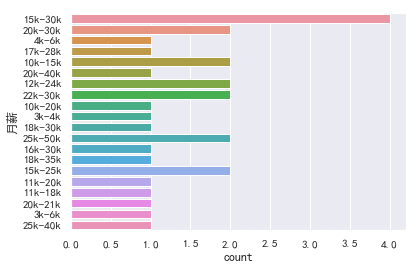
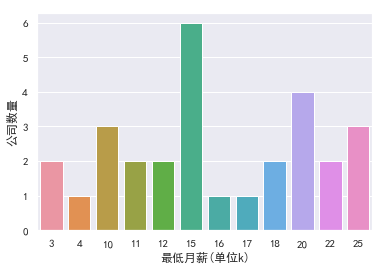
- 薪水
大部分集中在15-30k
我们取月薪的均值再看一眼.这里我们添加新的一列"平均月薪".
#处理月薪数据
def f(s):
#x="17k-18k"
l = s.replace('k','').split('-')
tmp=[int(e) for e in l]
return sum(tmp)/len(tmp)
df["平均月薪"]=df["月薪"].apply(f)

那种4k的基本是实习生.这么一看平均有22k,很诱人,有没有. 考虑到用人单位说的15-30k,一般指15k.... 我们再处理一下数据,绘图
def min_salary(s):
#x="17k-18k"
l = s.replace('k','').split('-')
return int(l[0])
df["最低月薪"]=df["月薪"].apply(min_salary)
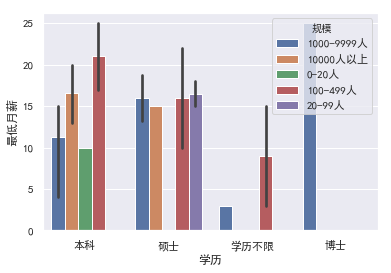
再看看不同规模公司中,不同学历与月薪的关系.小公司里本科生更多.大公司里硕士生占比提高.
NLP工程师需要会什么?
之前的代码里,我们已经抓取到了任职描述和岗位要求,现在我们使用jieba去做分词.
- 注意去掉stopwords
- 词典添加自定义词.比如希望'机器学习'被认为是一个完整的词,而不是‘机器’、‘学习’两个词.
f = open("./词表/哈工大停用词表.txt",encoding='utf-8')
stopword_list = [line.strip() for line in f.readlines()]
self_defined_list = ['1','2','3','4','5','6','以上学历','关于','\n']
stopword_list.extend(self_defined_list)
print(stopword_list)
def add_self_defined_words():
jieba.add_word('机器学习')
jieba.add_word('深度学习')
def get_words(serie):
clean_contents=[]
for s in serie:
s_tmp = ''.join(s)
#clean_s= re.sub(r'[^\u4e00-\u9fa5]', '', s_tmp) #https://github.com/fxsjy/jieba/issues/528 这个会去除中文词之外的词
clean_s = s_tmp
clean_contents.append(clean_s)
add_self_defined_words()
word_list = [word for word in jieba.cut(''.join(clean_contents),cut_all=False) if word not in stopword_list]
print(word_list)
tags=jieba.analyse.extract_tags(''.join(clean_contents), topK=20)
print(tags)
return word_list,tags
require_word_list,require_tags = get_words(df["任职要求"])
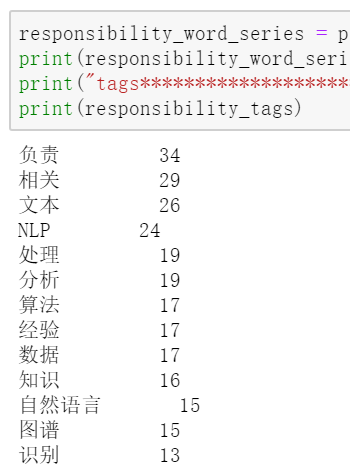
responsibility_word_list,responsibility_tags = get_words(df["岗位职责"])


结巴的topk关键词抽取使用的是tfidf,不是词频.仅供参考.这里我们其实更关心词频.
可以看到经验还是很重要的.不管是相关工作经验还是研究经验.
同样的看下岗位职责
![]()
为了探索特定词的词频,写了函数count_specific_word,考虑了相似词,比如Python和python其实想表达的是一个意思.
一般框架名都为英文比如tensorflow/hadoop等,写了函数get_englishword_list去获取这些英文词,情况如下:

可以发现tensorflow是最常被要求掌握的深度学习框架.
#获取特定词的出现次数
def count_specific_word(serie,word_list):
index = [False] * len(serie)
for w in word_list:
tmp_list = list(serie == w)
#print(list(tmp_list).count(True))
index=list(np.logical_or(tmp_list,index)) #注意一下两个boolean list相应位置and or的用法
#print(index.count(True))
return list(index).count(True)
print(count_specific_word(require_word_series,["TensorFlow"]))
print(count_specific_word(require_word_series,["经验"]))
print(count_specific_word(require_word_series,["研究生","硕士"]))
print(count_specific_word(require_word_series,["深度学习","机器学习"]))
print(count_specific_word(require_word_series,["python","Python"]))
#把中文去掉
def get_englishword_list():
l = []
for w in require_word_list:
w=re.sub(r'[\u4e00-\u9fa5\n]', '',w)
if w == "":
continue
else:
#print(w)
l.append(w.lower())
print(l)
return l
enw_serie = pd.Series(get_englishword_list())
enw_serie.value_counts()
为了获得更直观的印象,我们将关键词用词云绘制.
from wordcloud import WordCloud, ImageColorGenerator
from scipy.misc import imread
import matplotlib.pyplot as plt
def picture(wordlist):
font='C:\Windows\Fonts\simhei.ttf'
wc = WordCloud(background_color="white",font_path=font,max_words=2000)
wc.generate(" ".join(wordlist))
plt.figure()
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
picture(require_word_list),picture(responsibility_word_list)


将两组词合起来绘制出的词云如下:

总结:当前的NLP工程师招聘,基本上都要求有工作经验或研究经验的.(实际上意味着你如果你没有在学生阶段有NLP的经验的话,那么这个岗位基本也就与你无缘了...工作后会因为没有相关经验很难切入这个领域...不切入这个领域又很难积累经验...死循环)。 需要掌握python/java等,需要了解深度学习,最好能掌握诸如tensorflow的框架,具体要掌握的nlp相关技能会涉及数据挖掘、文本分词分类、实体抽取、知识图谱构件等.
最后,如果有南京地区的同学,求内推....

