大众点评 字体爬取
通过网站头部的css链接 每次下载不同的woff字体文件,通过TTfont打开对数字进行匹配即可完成对于字体的破解,
有两种方案,一种式直接从response.text 替换其所有含上述字体的字符完成替换后再通过 etree.HTML( ) 打开.text 对象再去完成xpath查询
一种就是直接先查取对象 这里不能单个提取,因为元素全部分开且单个提取后的乱码无法解析(因为有\)然后通过extract() 全部截取 [' ', ' ' ]类型
通过对于列表元素中,replace 掉\,再于字体中的对象字典进行匹配即可得出值,如果想让列表变为单个字符串可以用:先遍历元素 data = ''.join(data)
两只关键是在字体 文件woff里面提取出 键值对!:
其主要函数就是: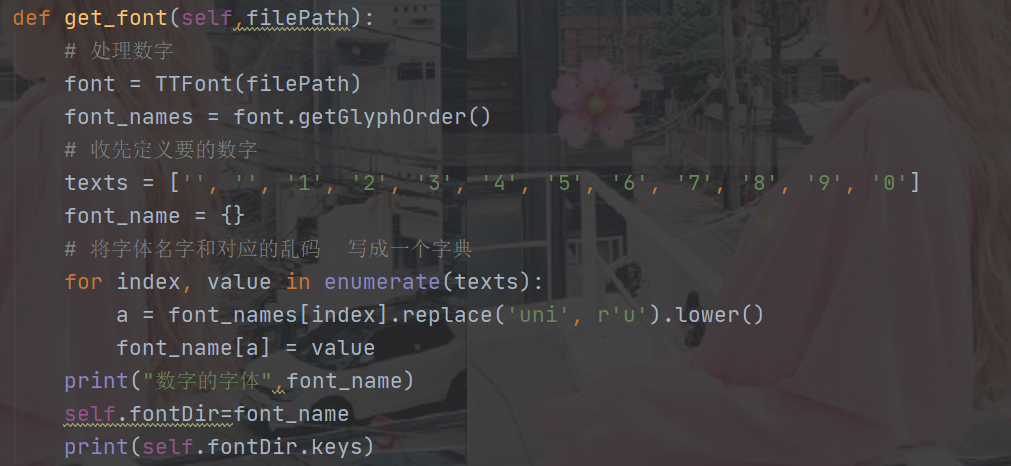


 浙公网安备 33010602011771号
浙公网安备 33010602011771号