
KAFKA
一、fakfa概述
Kafka 是一个分布式的基于发布 / 订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
1、使用消息队列的好处
1、解耦:系统A直接发布数据到MQ中间件,需要数据的系统直接订阅MQ即可,不需要数据的不订阅。系统之间没有任何耦合度。
2、异步:异步处理节省时间,可以不立即处理,需要处理的时候才处理
3、削峰:在访问量剧增的情况下,先把要处理的请求放到消息队列中,防止系统被搞垮,提高系统的稳定性
2、消费模式
1、点对点模式:一对一,消费者主动拉取数据,消息收到后消息清除,只有一个消费者可以拿到数据
2、发布订阅模式:一对多,消费者消费数据之后不会清除消息,发布到 topic 的消息会被所有订阅者消费。

3、基础架构

- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
二、安装部署
准备两台虚拟机,最好配置免密登录
vi /etc/hosts
# 新增
192.168.6.128 node1
192.168.6.129 node2
2.1首先安装zookeeper集群
- 下载安装包
cd /opt/module wget http://archive.apache.org/dist/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gz - 解压
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz mv apache-zookeeper-3.6.3-bin zookeeper - 修改配置文件
cd ./zookeeper/conf # 添加zookeeper配置文件 cp zoo_sample.cfg zoo.cfg # 创建数据存放目录 mkdir /opt/module/zookeeper/conf/data vim zoo.cfg # 添加如下内容 server.1=hadoop1:2188:2888 server.2=hadoop2:2188:2888 server.3=hadoop3:2188:2888 # 修改dataDir dataDir=/opt/module/zookeeper/conf/data # 配置文件保存退出后,进入data目录 cd ../data # 生成myid文件,指定myid服务号 echo "1" > myid - 将zookeeper目录分发到其他节点
scp -r zookeeper/ node2:/opt/module/zookeeper - 修改其他节点的myid文件
#登录到node2 cd /opt/module/zookeeper/conf/data # 指定myid服务号为 2 vim myid - 编写操作zookeeper集群的脚本
#!/bin/bash case $1 in "start"){ for i in node1 node2 do echo ------------- zookeeper $i 启动 ------------ ssh $i "/opt/module/bin/zkServer.sh start" done } ;; "stop"){ for i in node1 node2 do echo ------------- zookeeper $i 停止 ------------ ssh $i "/opt/module/bin/zkServer.sh stop" done } ;; "status"){ for i in node1 node2 do echo ------------- zookeeper $i 状态 ------------ ssh $i "/opt/module/bin/zkServer.sh status" done } ;; esac - 启动集群
# 启动集群命令 ./zk.sh start # 停止集群命令 ./zk.sh stop # 查看集群状态命令 ./zk.sh status - 连接zookeeper集群
cd /opt/module/zookeeper ./bin/zkCli.sh
2.2安装kafka集群
-
下载安装包
官方下载地址:http://kafka.apache.org/downloads.html -
解压
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/ mv kafka_2.12-3.0.0/ kafka -
修改配置文件
主要修改:broker.id、log.dirs、zookeeper.connect
cd config/ vim server.properties #broker 的全局唯一编号,不能重复,只能是数字。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以 配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理) zookeeper.connect=node1:2181,node2:2181/kafka -
分发kafka安装目录
scp -r kafka/ node2:/opt/module/kafka 分发完成后,需要修改配置文件server.properties中的 broker.id参数。 -
编写kafka集群操作脚本
#!/bin/bash case $1 in "start"){ for i in node1 node2 do echo -------------------------------- $i kafka 启动 --------------------------- ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties" done } ;; "stop"){ for i in node1 node2 do echo -------------------------------- $i kafka 停止 --------------------------- ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh" done } ;; esac -
启动kafka集群
启动kafka集群命令 ./kafka-cluster.sh start 停止kafka集群命令 ./kafka-cluster.sh stop
转 https://blog.csdn.net/u011109589/article/details/124920047
2.3kafka命令操作
2.3.1主题命令行操作
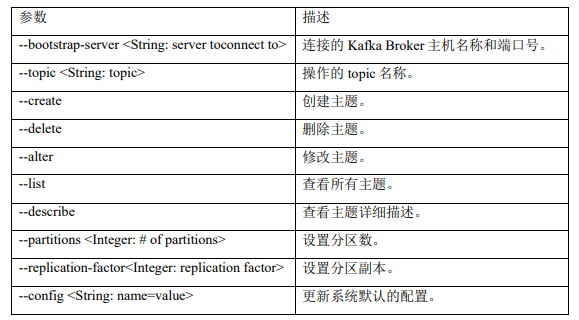
# 查看所有主题
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --list
# 创建主题
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --topic apple --create --partitions 1 --replication-factor 2
Created topic apple.
# 选项说明:
--topic 定义 topic 名
--replication-factor 定义副本数
--partitions 定义分区数
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --list
apple
# 查看主题详情
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --describe apple
Topic: apple TopicId: oj5zpIuNRtGEhbjHGlOTaA PartitionCount: 1 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: apple Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
# 修改分区为2个,注意:分区数只能增加,不能减少
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --alter --topic apple --partitions 2
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --describe --topic apple
Topic: apple TopicId: oj5zpIuNRtGEhbjHGlOTaA PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: apple Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: apple Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
# 删除分区
[root@node1 kafka]# bin/kafka-topics.sh --bootstrap-server node1:9092 --delete --topic apple
2.3.2 生产者

#发送消息
[root@node1 kafka]# bin/kafka-console-producer.sh --bootstrap-server node1:9092 --topic apple
>1234
>23
>
2.3.3消费者

# 消费消息
[root@node1 kafka]# bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic apple
33
111
# 读出所有消息,包括历史消息
[root@node1 kafka]# bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic apple --from-beginning
23
111
1234
33
三、生产者
发送原理
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
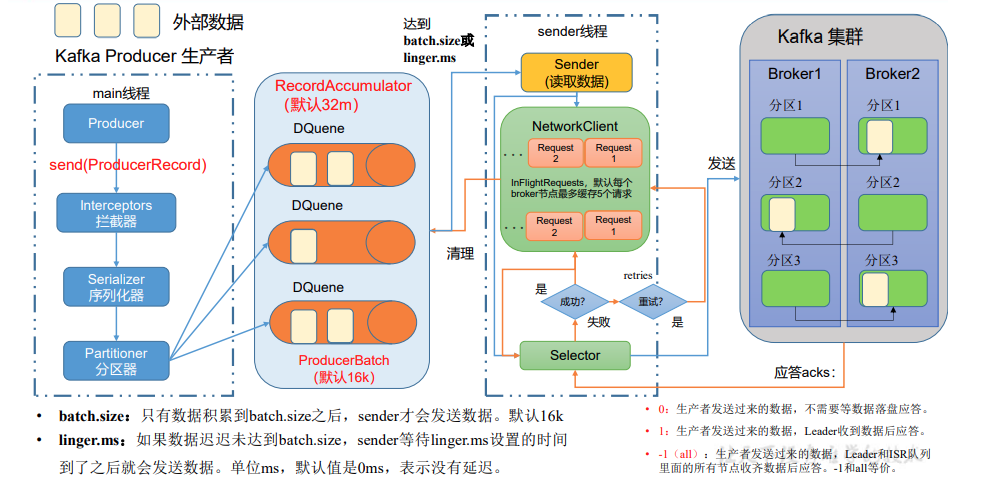
分区好处
1、合理使用存储资源,每个Partition在一个broker上存储,可以把海量数据分割 分别储存在不同broker的Partition上
2、提高并行度,生产者可以以分区为单位发送数据,消费者可以以分区为单位消费数据
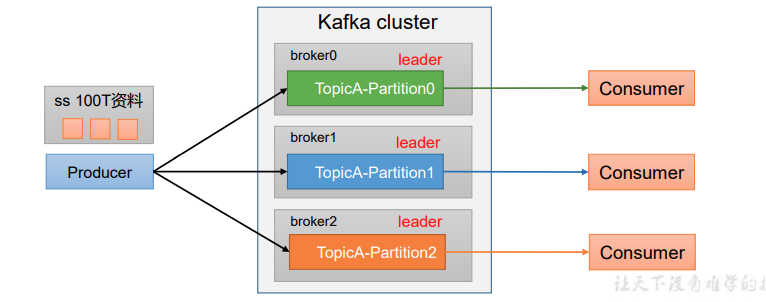
生产者发送消息的分区策略
-
发生指明分区,则直接把数据发送到指定分区
-
发送没有指定分区,但有key 的情况 会将key 的hashcode 对topic的分区数量取余得到Partition值
-
既没有partition值又没有key值的情况下,会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)。
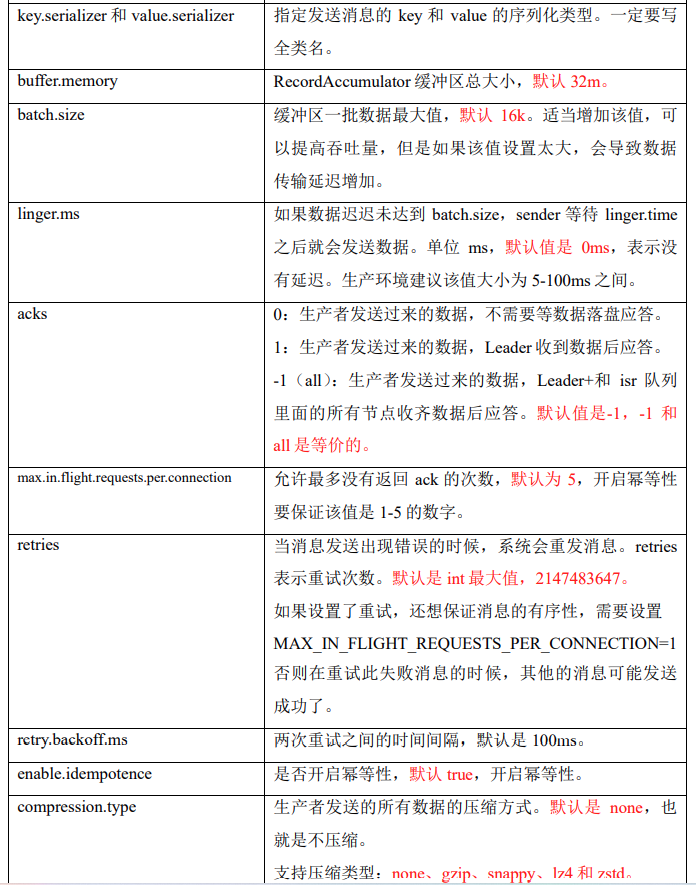
生产者如何提高吞吐量
-
batch.size:批次大小,默认16k
-
linger.ms:等待时间,修改为5-100ms
-
compression.type:压缩snappy
-
RecordAccumulator:缓冲区大小,修改为64m
生产者数据发送可靠性
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,
对可靠性要求比较高的场景。
ISR队列里面都是活的Follwer节点 和Leader节点
消息幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。所以幂等性只能保证的是在单分区单会话内不重复,可以通过事务解决问题。
解决发送数据乱序问题
-
kafka在1.x版本之前保证数据单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。 -
kafka在1.x及以后版本保证数据单分区有序,条件如下:
(1)未开启幂等性
max.in.flight.requests.per.connection需要设置为1。(2)开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,
故无论如何,都可以保证最近5个request的数据都是有序的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通