hbase-列存储动态数据库
1) HBase是什么?
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
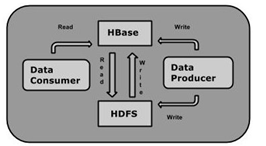
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
2) HBase的存储机制
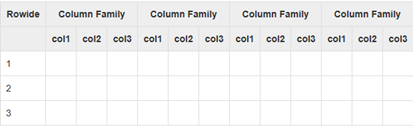
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。
总之,在一个HBase:表是行的集合à行是列族的集合à列族是列的集合à列是键值对的集合,如图:
3) Hbase的特点
- 建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式列存储的动态模式数据库,列式数据库(nosql)专门解决hadoop不擅长的工作。
- 采用BigTable的数据模型。增强的稀疏排序映射表(Key/Value),其中“键”是由行关键字、列关键字、时间截构成。
- 提供对大规模数据的随机、实时读写访问功能,其保存的数据可通过MapReduce处理。
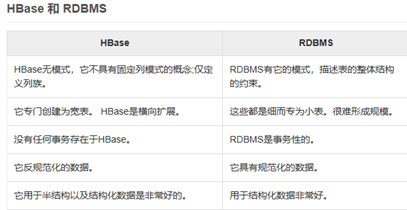
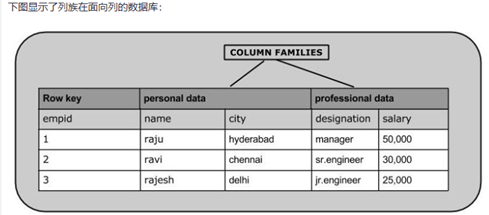
4) 行数据库与列数据库的区别

5) hbase表特点:
- 表比较大,一个表有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要冬天的增加,同一张表中的行也已有截然不同的列;
- 稀疏:空值列并不占用存储空间,列独立检索;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时间戳;
- 数据类型单一:数据都是字符串,没有类型
6) 存储核心—Hstore
Hstore分为menstore和storefiles两部分。
用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除
HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能架构。
7) Hbase架构
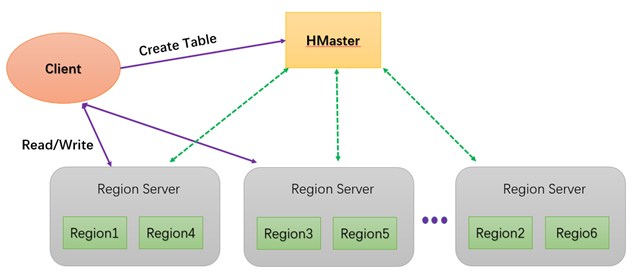
一个HMaster(管理服务器)控制多个Region Server(数据服务器);
- HMater负责表的创建、删除、维护以及Region的分配和负载均衡;
- Region Server负责管理维护Region以及响应读写请求;
- 客户端与HMaster进行有关表的元数据操作,之后直接读写Region servers。
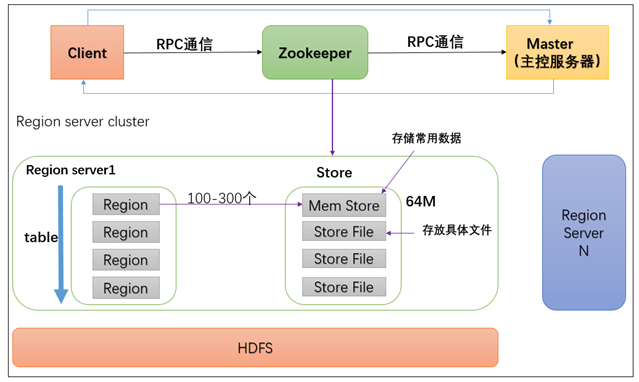
Master职责:
1. 为regionserver分配region;
2. 负责regionserver的负载均衡;
3. 垃圾文件回收;
4. 处理schema请求
Zookeeper职责:
- 保证集群只有一个Master;
- 监控Region Server状态,实时通知Master;
- Hbase目录入口地址;
- Hbase的Schema信息
Region职责:
- 对数据的读写支持;
- 对region管理的支持;
- Hbase目录入口地址;
- Hbase的Schema信息
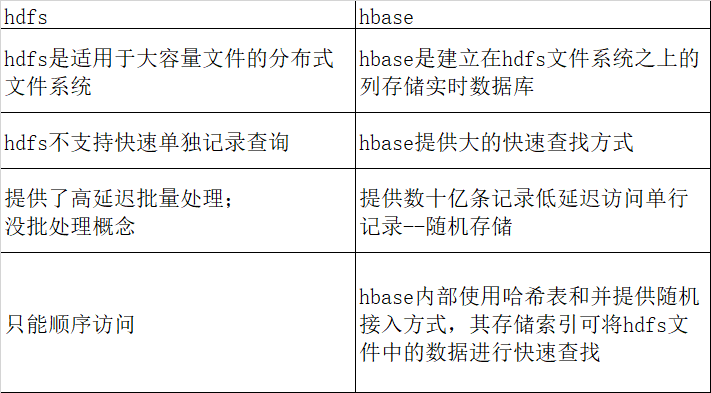
8) HBase 和 HDFS关系
9) hive与hbase区别
相同点:都是架构在hadoop之上,都是用hadoop作为底层存储
不同点:
Hive:
- 是批处理系统,目的是检索MapReduce jobs的编写工作;
- 是纯逻辑表并且是全表扫描,本身不存储和计算数据,完全依赖HDFS和MapReduce;
- 时效性低
Hbase:
- 是实时操作系统,目的是弥补hadoop的缺陷项目;
- 是物理表,采用列存储索引数据或实时数据,提供超大的内存hash表;
- 高时效性。
在安装hadoop分布式文件系统的集群中选择任意几台机器安装hbase
安装jdk,hadoop,tar,设置环境变量(同hadoop/hive类似操作)
验证安装是否成功:hbase version
完全分布式配置:
[hbase/conf/hbase-env.sh]
export JAVA_HOME=/soft/jdk
export HBASE_MANAGES_ZK=false
<!-- 使用完全分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定hbase数据在hdfs上的存放路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ip:8020/hbase</value>
</property>
<!-- 配置zk地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>ip1:2181,ip2:2181,ip3:2181</value>
</property>
<!-- zk的本地目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/centos/zookeeper</value>
</property>
配置regionservers
[hbase/conf/regionservers]
节点名称1
节点名称2
…
启动集群:进入hbase的bin目录
./start-hbase.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号