
广告检索优化实践
首先介绍一下索引的原理,打个比方说一个新员工入职,想认识和他是同乡且喜欢“王者农药”的妹子或汉子,最简单的方式就是一个个老员工问过去,但有将近400号员工,这种方式肯定是低效的。这时如果HR把员工按游戏爱好、家乡、性别等分组后放在不同的文档中你就可以快速的定位到要找的妹子或汉子了,这就是索引以及索引的作用,与我们筛选广告有着相似的需求。常见的索引有数据库中的B+树索引以及搜索引擎中常用的倒排索引,这两者的区别太专业,这里就不细表,感兴趣的同学可以参考文档1。在业界较早且成熟的搜索引擎方案是Lucene但只能应用在Java开发中,后面出现了独立的搜索引擎服务器例如Solr、ElasticSearch等。ElasticSearch加入了分布式、分片等特性后作为后期之秀在业界得到了大量使用。推啊广告平台在技术选型时对比了各搜索引擎在分布式管理、数据格式支持、使用便利性、实时数据更新等方面做了对比,结合推啊广告自身数据变化频率比较高的情况,选择了ElasticSearch(简称ES)作为广告检索引擎的基础服务。
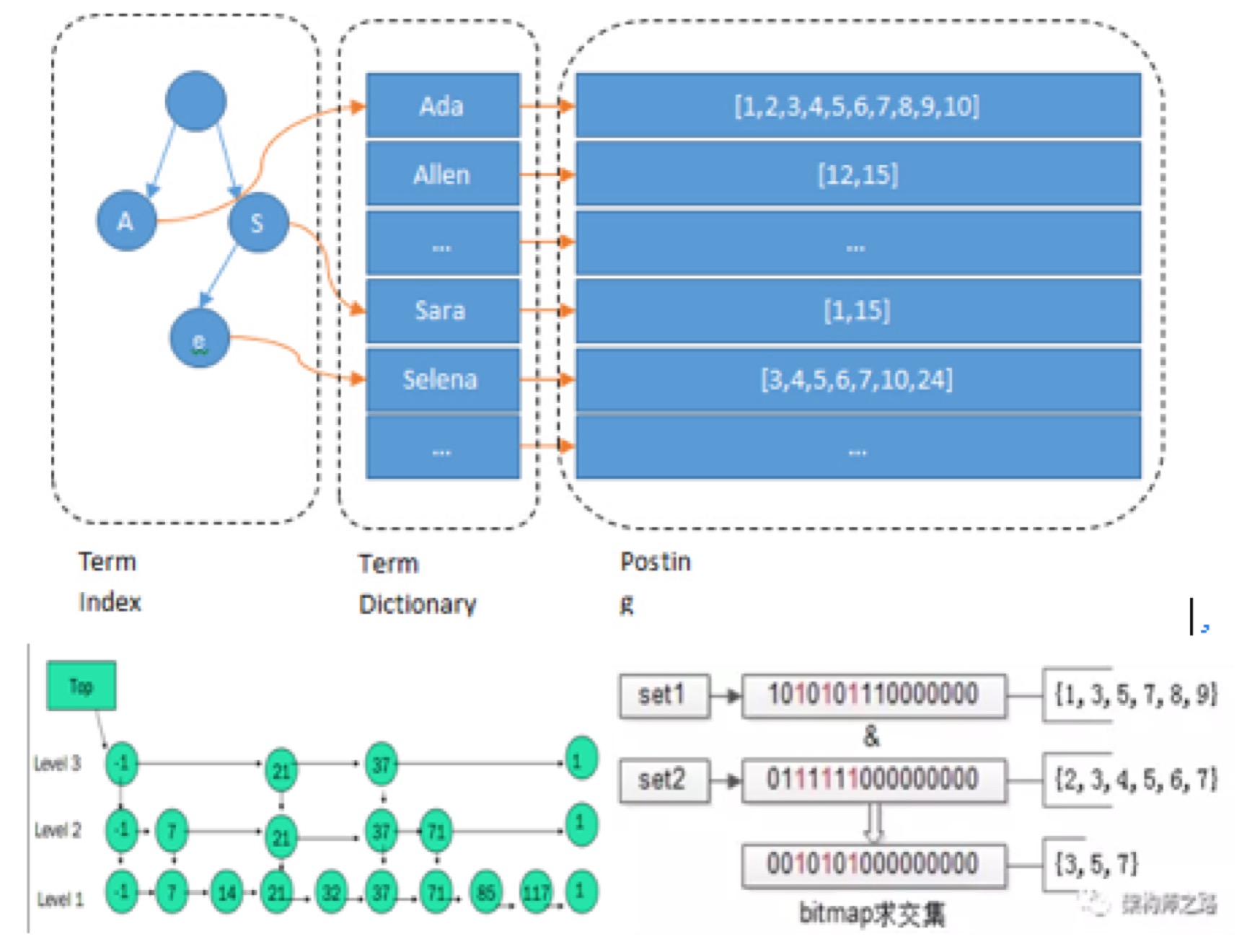
下面进一步说明ES为了提高检索效率而做的一些优化,还是使用新员工入职的例子,全国一共有三百多个城市那么如何在文档中快速的定位到自己所在的家乡城市呢?这儿就用到了正排索引,例如根据城市名称或者所在省份建立Sheat或者超链接,如图2所示,在ES中使用Term Dictionary加速定位同时为了能全部使用内存查询又引入了Term Index基本结构。假设从王者农药中找到了1000个小伙伴在城市列表中找到了20个小伙伴那如何快速的找到同时满足这两个特征的小伙伴呢?假如拿20个小伙伴的名字和1000个比较那就需要20000次肯定是低效的,如果1000个小伙伴的名字根据拼音有一个目录是不是就快很多了。在ES中就使用了SkipList这种结构来加速两个列表的聚合,当然还有将两组文档列表分组后转换为位进行位操作的方式这里就不在细说了。同时ES为了减少磁盘占用也大量的进行数据压缩此处不在详细描述有兴趣的可以参考后面的链接。
接下来详细说一下推啊进行广告检索优化实施的过程:
将广告数据推送到搜索引擎
如果ES中的数据为空则读取可用广告列表构建数据推送到ES中,监听各类广告变化消息进行同步变更编写代码校验DB和ES中的数据是否同步。这块功能在检索功能上线前发布,最后一步帮助提前发现数据不一致问题。在上线后确实发现因为使用Redis作为消息队列而导致的多机并发问题(多个机器接受到广告变更消息且执行顺序不一致导致ES数据不一致),使用zk作为分布式锁保证只有一个消费线程后解决了,同时开发补偿功能如果在一段时间内持续检测到数据不一致则强制进行一次ES的数据重建。
广告检索核心流程开发
将原有的广告检索流程中的静态条件检索改造为ES查询组装查询条件构造各种测试数据进行测试。代码开发完成后使用jmeter进行压力测试使用BeanShell构建动态的查询参数模拟真实请求。在压力测试过程中观察应用和ES的内存CPU等使用情况发现ES的CPU使用较高。然后使用Jmc或者JProfiler采样发现ES使用了大量时间进行json的反序列化操作,经过分析是存储的json文档数据因为包含城市信息较多所以特别大,因为程序中使用的返回字段有限所以使用单独设置要返回的字段单独store解决。进行改造,再次压测采样发现ES耗费大量的时间在lz4的解压缩方法上,从业务场景分析广告数据量比较小实际用不到压缩功能但是查找官方issue和github后发现该功能点为底层的Lunce自带无法关闭。

线上并行比对
由于检索流程涉及到金钱所以一定要保证上线后改业务的正确。经过讨论决定使用并行在线的方式进行一段时间的线上比对,执行完旧的广告检索流程后再执行一次新的使用ES检索的流程然后比对两者的结果,这样就能在真正的替换使用新检索代码前发现代码中的问题。同时为了保证比对的代码部分不影响系统的性能使用Hystrix来控制比对线程池的资源消耗和超时时间。
ES调优
在系统改造前ES一直作为用户特征的存储检索组件,内部存储了上百G的用户特征信息。该模块只需要使用id进行用户信息的检索但是在设计时没有关闭分词索引等用不到的功能导致上线后一直占用了大量的系统资源。如果广告检索上线后和改模块共用资源势必相互影响,考虑到该模块是大量索引操作进行了以下优化:增大Refresh时间这样就减少了索引操作的频率,减少副本数量这样就减少了通一个索引操作所占用的机器(索引操作在主分片和副本上占用同样的资源)。当然后续分析这块的业务更适合KV存储接口将数据迁移到了Mongodb,然后大量的写入占用资源的情况也不存在了。

Hytrix的使用
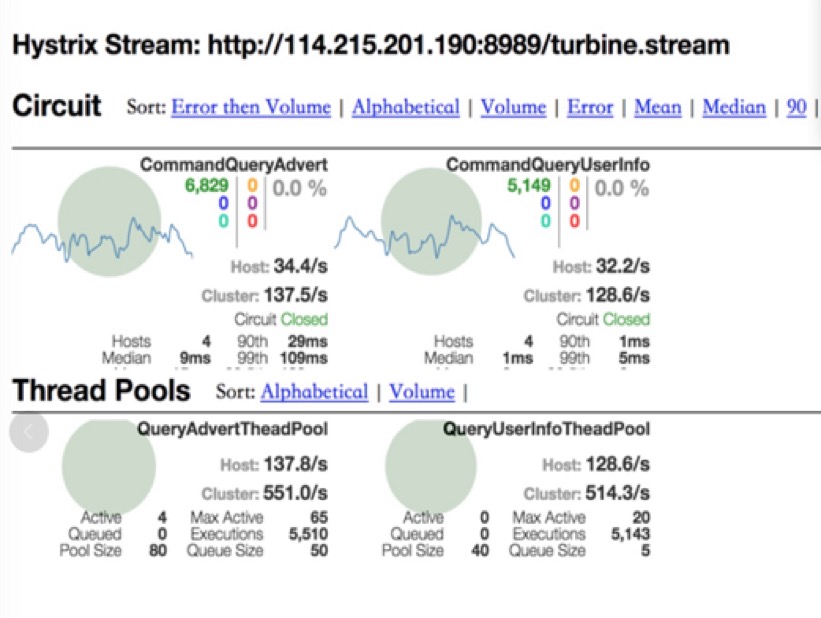
考虑到当时ES的使用还不太稳定(响应时间基本在15ms但也有上200ms的)引入Hytrix控制资源的使用,同时作为熔断器在ES挂掉的情况下快速失败返回谢谢参与保证活动的正常逻辑,系统上线后在7.1号单个应用做活动导致流量翻倍的情况下也比较好的抗住的压力。关于熔断器有一点要说的就是不能为了不发生熔断的情况而不断的增大线程池和超时时间,熔断器的作用就是控制资源的使用。通过线程池个数*TP99的相应时间估算最坏情况的吞吐来设置相应的值,在超时或者线程池不足的情况下抛弃部分流量减少后续压力是正确的方式。


成果
系统正式上线后经过了流量翻倍以及广告配置包翻倍的考验,当前每日发券量达到了3000万定向配置包的个数达到了600左右。上线后TP95和TP99等指标下降了25%左右,同时熔断器的引入也在流量高峰的应对中起到了作用。
图6为广告检索优化前后投放流程的响应时间对比直方图。从图中可以看出性能提升了30%,但回到文章开头的问题,最重要的是解决随着广告库在线广告数量的增加带来的性能下降。
图7为检索优化带来的系统业务容量。
当前系统的负载使用和CPU使用在中等水平,考虑到业务的快速发展后续还需进一步对ES的使用还需进行优化。
希望通过对检索引擎的不断优化、广告投放流程的不断优化这些前戏工作,能够让推啊广告业务“持久的高潮”。
参考文档
- B+树:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
- 执行计划:http://coding-geek.com/how-databases-work/
- Hytrix:http://hot66hot.iteye.com/blog/2155036 https://github.com/Netflix/Hystrix/wiki
- ES:https://neway6655.github.io/elasticsearch/2015/09/11/elasticsearch-study-notes.html
- ES: https://www.datadoghq.com/blog/monitor-elasticsearch-performance-metrics/
- https://mp.weixin.qq.com/s?__biz=MzA4NjgwMDQ0OA==&mid=2652445487&idx=1&sn=fb99fac1db2ad8120e98f00165323b2a&scene=0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号