AWVS批量导入网站(刷漏洞入门)
今天整了一天这个AWVS批量扫描脚本,主要是下了好几个版本的AWVS,都不稳定,一次次删除又一次次安装。
做这件事儿目的就是为了批量刷漏洞,不过弄好之后又不打算刷漏洞了,不太喜欢无脑刷漏洞,没什么意义,并且现在水平也不是很高,先踏实学习吧。
这个文章目的就是记录一下整体的思路。
要想较为高效的刷漏洞(这里指的是和菜鸟相比),需要两步,一 : 获取大量的网页链接 ; 二 : 误报率低,比较牛逼一点的漏洞扫描工具
一 :获取大量的网页链接
这个有三种方法:
① fofa 这个有前提 ,必须得有 fofa 的VIP会员,直接下载工具 输入 账号 和 key 即可批量导,软件直接在 github 下载就行
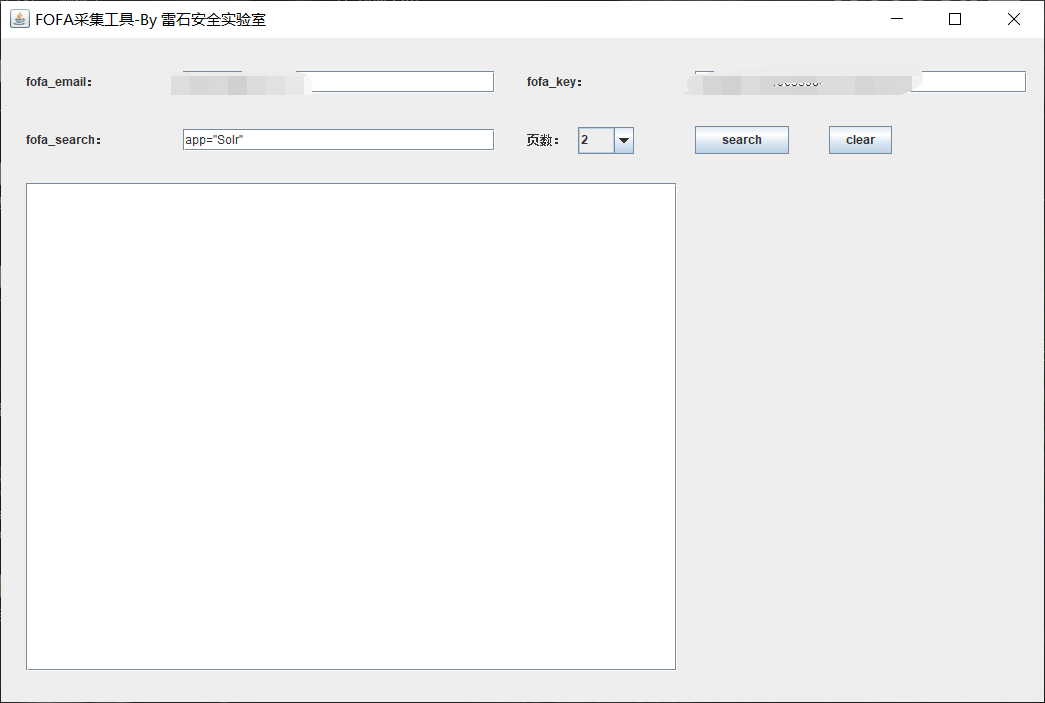
软件下载链接 : https://github.com/tangxiaofeng7/Fofa-collect/releases/tag/V1.0
② 利用crawlergo工具,
这个工具 功能就是能爬取 你导入好的txt文件中 每个链接中 源码的 链接
这个工具的原理就是爬虫,开启多个chrom一起爬,(这个chrom不是咱们用的那个谷歌浏览器,只是名字差不多)
这个工具如果和 xray 联动 ,那就比较完美 ,这个工具可以设置代理 ,流量先通过 xray 最后在放出去,实现了被动扫描。具体详情可以看 我写的文章 在分类中的 xray和crawlergo联动
https://github.com/0Kee-Team/crawlergo
这个是crawlergo在github中的下载链接,里面也有 crawlergo 使用说明
③ 这种方法就比较普通了,就是使用 layer 子域名挖掘机去一个个挖掘,不太推荐这种方法,layer扫出来的网站质量一般
二 : 选一款牛批的漏洞扫描工具
常见的漏洞扫描工具无非就是 AWVS ,appscan ,OWAsp ,xray 等等 ,因为以前用awvs感觉不错,所以这次也选的 awvs (没想到坑死我。。。)
网上许多的 awvs破解版都不太稳定,要不就是没 api,要不就是使会儿就不行了,现在是2020.7.24 实测下面这款比较不错,有需要的可以下载
https://www.sqlsec.com/2020/04/awvs.html
下载完了之后按照步骤破解安装就行
AWVS这里有个小缺点就是只支持批量导入 csv 文件,这就有点xx,几百上千个网站,我总不能一个个导入,于是就在网上找了半天批量导入的脚本,还好,试了几个之后就找到了个合适的,
直接把文章链接放出来 https://www.imzzj.com/2020/05/18/shi-yong-python-gei-awvs13-pi-liang-tian-jia-ren-wu.html 顺便感谢下博主,给了我很大帮助!!
这里需要提示一点的就是 使用 pycharm打开的时候,import 导入包儿那块儿会报一些错误,也没明白是啥情况,反正我给改对了,直接贴出来前部分的代码
import requests
import json
import requests.packages
import urllib3.packages
from urllib3.exceptions import InsecureRequestWarning
# from requests.packages.urllib3.exceptions import InsecureRequestWarning
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
urllib3.disable_warnings(InsecureRequestWarning)
apikey = '1986ad8c0a5b3df4d7028dc51b15d120bf015197e'
# 去 AWVS 配置文件里面 有个 API KEY 复制填进去就行
apikey = str(apikey)
headers = {'Content-Type': 'application/json',"X-Auth": apikey}
def addTask(url,target):
try:
url = ''.join((url, '/api/v1/targets/add'))
data = {"targets":[{"address": target,"description":""}],"groups":[]}
r = requests.post(url, headers=headers, data=json.dumps(data), timeout=30, verify=False)
result = json.loads(r.content.decode())
return result['targets'][0]['target_id']
except Exception as e:
return e
def scan(url,target,Crawl,user_agent,profile_id,proxy_address,proxy_port):
scanUrl = ''.join((url, '/api/v1/scans'))
target_id = addTask(url,target)
if target_id:
data = {"target_id": target_id, "profile_id": profile_id, "incremental": False, "schedule": {"disable": False, "start_date": None, "time_sensitive": False}}
try:
configuration(url,target_id,proxy_address,proxy_port,Crawl,user_agent)
response = requests.post(scanUrl, data=json.dumps(data), headers=headers, timeout=30, verify=False)
result = json.loads(response.content)
return result['target_id']
except Exception as e:
print(e)
def configuration(url,target_id,proxy_address,proxy_port,Crawl,user_agent):
configuration_url = ''.join((url,'/api/v1/targets/{0}/configuration'.format(target_id)))
data = {"scan_speed":"fast","login":{"kind":"none"},"ssh_credentials":{"kind":"none"},"sensor": False,"user_agent": user_agent,"case_sensitive":"auto","limit_crawler_scope": True,"excluded_paths":[],"authentication":{"enabled": False},"proxy":{"enabled": Crawl,"protocol":"http","address":proxy_address,"port":proxy_port},"technologies":[],"custom_headers":[],"custom_cookies":[],"debug":False,"client_certificate_password":"","issue_tracker_id":"","excluded_hours_id":""}
r = requests.patch(url=configuration_url,data=json.dumps(data), headers=headers, timeout=30, verify=False)
def main():
Crawl = False
proxy_address = '127.0.0.1'
proxy_port = '8888'
awvs_url = 'https://127.0.0.1:3443' #awvs url
with open('url.txt','r',encoding='utf-8') as f:
targets = f.readlines()
profile_id = "11111111-1111-1111-1111-111111111111"
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21" #扫描默认UA头
if Crawl:
profile_id = "11111111-1111-1111-1111-111111111117"
for target in targets:
target = target.strip()
if scan(awvs_url,target,Crawl,user_agent,profile_id,proxy_address,int(proxy_port)):
print("{0} 添加成功".format(target))
if __name__ == '__main__':
main()
使用说明就是 先更改配置 ,添加api_key ; 把需要扫描的站点放在 url.txt 中 ; 运行awvs.py ; 显示 XXX 导入成功;打开awvs,可以看到站点添加成功,直接就开始自动扫描了
最后哔哔一句,不知道为啥,AWVS误报率有些高,没太仔细看,也没准是我的问题,等真正投入到挖漏洞的时候在研究吧。
最后推荐几篇文章:
https://zhuanlan.zhihu.com/p/108065469

 浙公网安备 33010602011771号
浙公网安备 33010602011771号