
线上 leaderelection lost 导致 Kubernetes 组件异常退出的问题排查
问题描述
在线上集群中,遇到了 kube-scheduler,kube-controller-manager 频繁的异常退出重启,报错信息如下:
排查处理流程
选举失败一般是从几个方向去考虑排查:
• 组件资源占用,给到组件过低的资源可能会导致选举失败
• ETCD 存在问题,比如 etcd 挂载的磁盘性能过差,etcd组件异常等均有可能导致
• 网络问题,网络延迟高或不稳定也会导致问题
资源占用
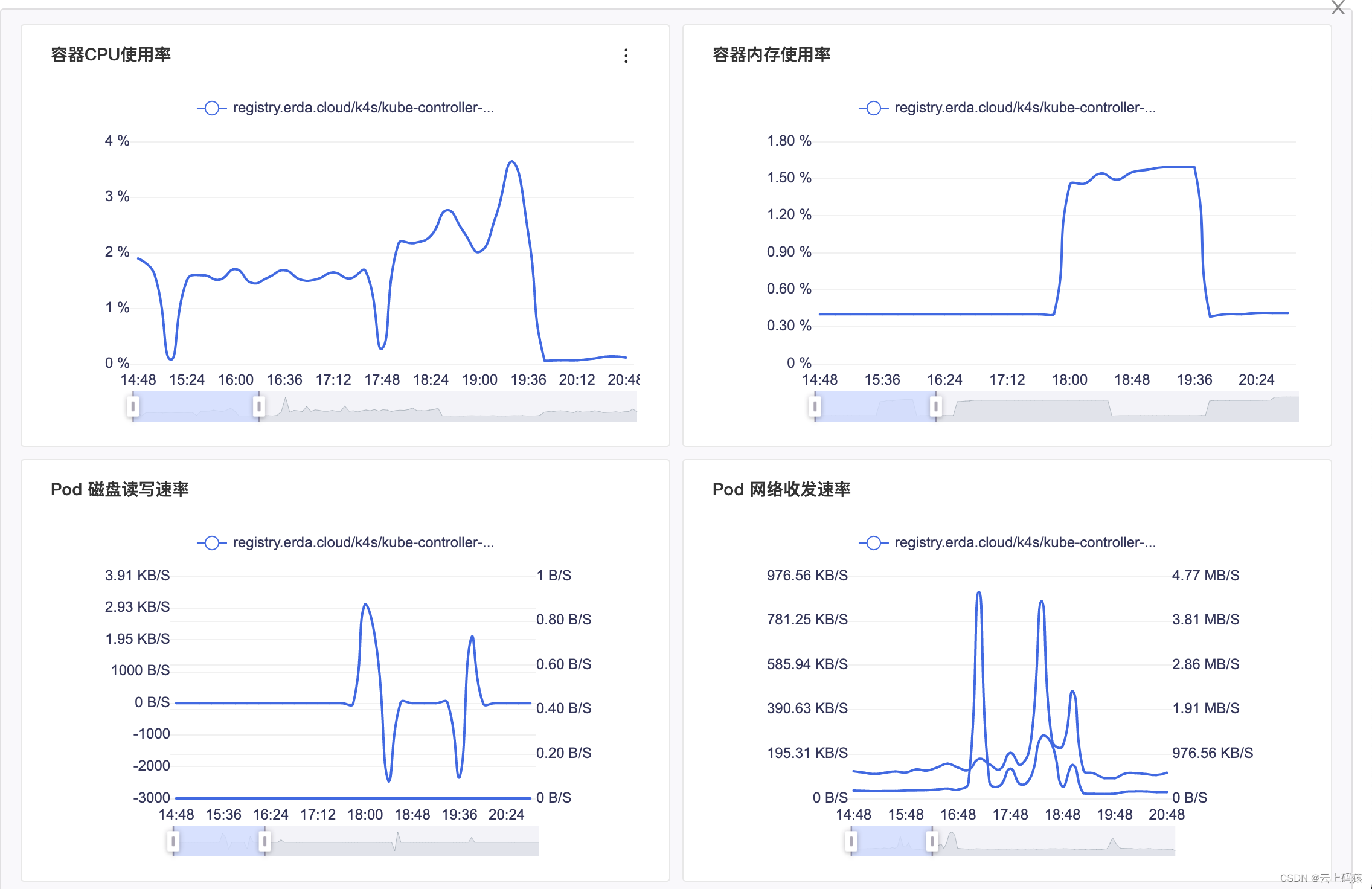
首先我们排查资源占用问题,在 Erda 平台找到对应 Pod 的历史监控数据,从资源占用上来看,并没有瓶颈,资源分配的很充足。
ETCD
排查 ETCD,并没有异常退出出现,而且查看 Pod 的事件也正常,这时候我们对 ETCD 进行一下写入测试
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=‘-’ --cert=‘-’ --key=‘-’ --cacert=‘-’ check perf

发现etcd磁盘的读写性能不够。
网络排查
我们排查下网络问题,查看两个组件的资源锁的信息,发现 renew 是正常的。
kubectl get leases -n kube-system
这时候我们考虑有可能是网络波动造成的,选举有如下两个参数需要注意:
• leader-elect-lease-duration:重新选举的超时时间,在该时间内,如果持锁的实例没有进行租约续期,则重新进行选主
• leader-elect-renew-deadline:如果在该时间内没有租约续期,则丢失持锁者的身份
–leader-elect-lease-duration=15s
–leader-elect-renew-deadline=10s
我们更改为 30s 跟 20s,由于是静态 Pod 拉起的组件,我们进入 yaml 所在路径,增加上述两个启动参数
cd /etc/kubernetes/manifests
经过几天的观察,并没有再出现异常重启的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号