清楚缓存_使用github进行数据缓存
Most people are aware of using GitHub as an easy tool to collaborate on coding projects, but few even realize that you can use it as a data storage and caching system — for free.
大多数人都知道使用GitHub作为在编码项目上进行协作的简便工具,但是很少有人意识到您可以免费将它用作数据存储和缓存系统。
Depending on your use case, this can be a really nice workflow and allow some nice tricks like using static sites with dynamically generated and cached content.
根据您的用例,这可能是一个非常不错的工作流程,并允许使用一些不错的技巧,例如使用具有动态生成和缓存内容的静态网站。
使用原始代码URL将GitHub托管的文件作为数据源进行引用 (Reference GitHub-Hosted Files as Data Sources Using Raw Code URLs)
The main idea that stands behind this is quite simple: GitHub offers a raw view for files that can be accessed via a URL and gives you the raw file without any of the “GitHub stuff” around it. So instead of seeing your text or JSON file with all the version history and the GUI to make changes or download, you just get the file itself hosted under that URL.
背后的主要思想很简单:GitHub提供了可通过URL访问的文件的原始视图,并为您提供了没有任何“ GitHub内容”的原始文件。 因此,您无需查看具有所有版本历史记录和GUI进行更改或下载的文本或JSON文件,而只需将文件本身托管在该URL下即可。
The URL looks something like this:
URL看起来像这样:
https://raw.githubusercontent.com/username/repositoryname/master/filename?token=dsaöjlksdajöldfasjöfaThis URL does not change between builds or commits, which means that you can use it as persistent storage. This is already pretty nifty and can save you from setting up a database on some projects. However, this can be used even better to do caching of all kinds of common requests.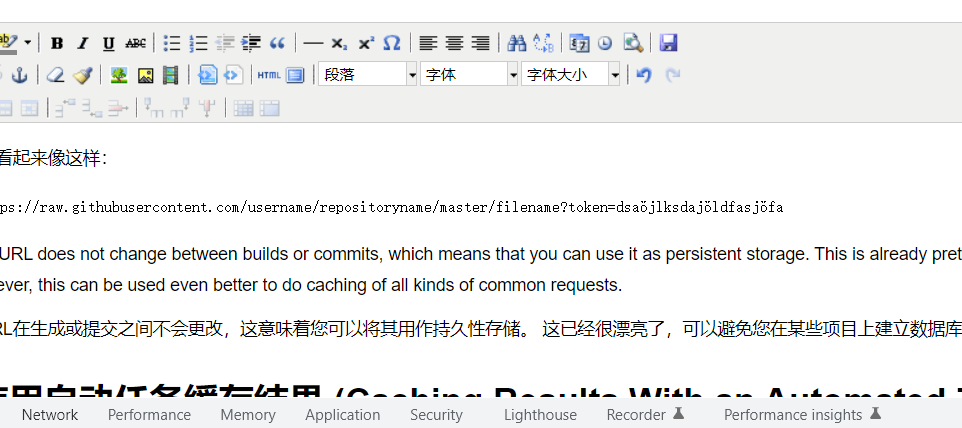
该URL在生成或提交之间不会更改,这意味着您可以将其用作持久性存储。 这已经很漂亮了,可以避免您在某些项目上建立数据库。 但是,这甚至可以更好地用于缓存各种常见请求。
使用自动任务缓存结果 (Caching Results With an Automated Task)
In essence, you will need a way to automatically commit changes to the repository every so often. This can be stupidly simple with a batch script running on your own machine or a server. Something like this:
本质上,您将需要一种经常自动将更改提交到存储库的方法。 使用在自己的计算机或服务器上运行的批处理脚本,这可能非常简单。 像这样: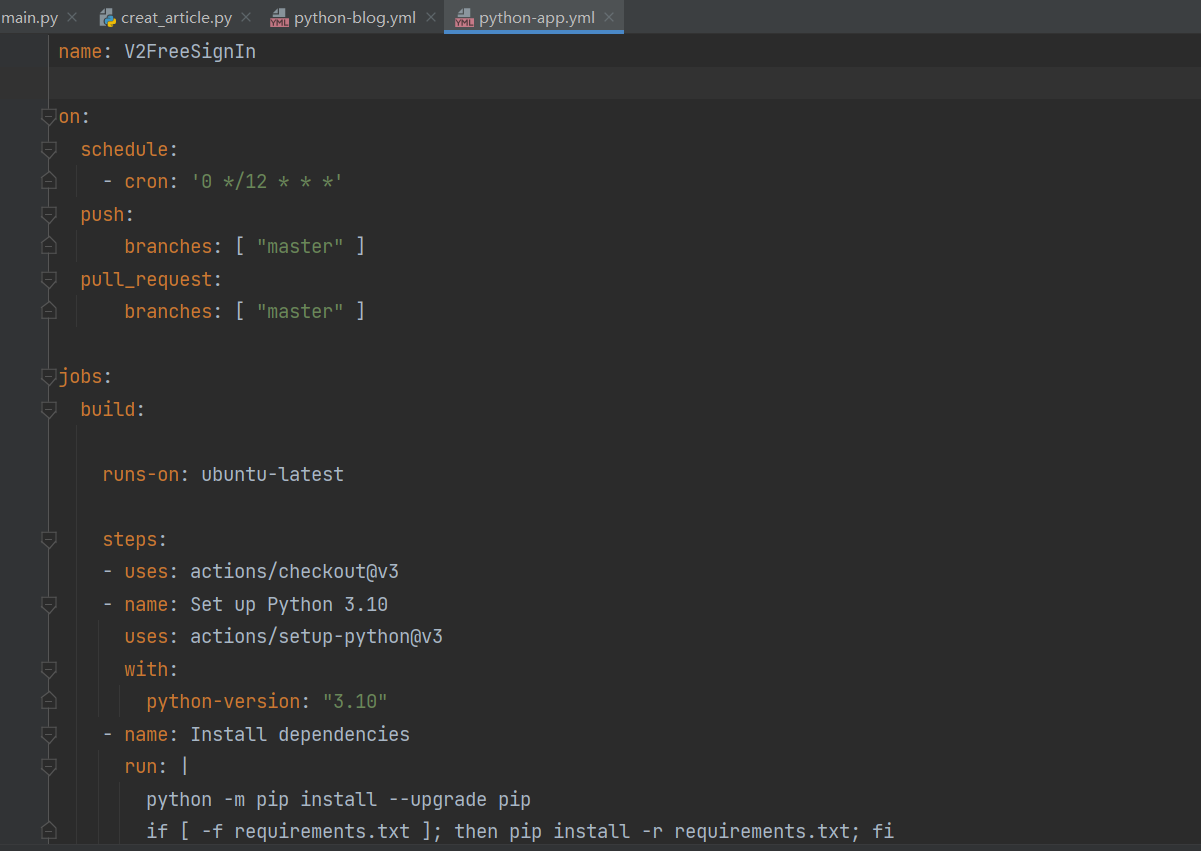

 浙公网安备 33010602011771号
浙公网安备 33010602011771号