
隐马尔可夫模型(Hidden Markov Model,HMM)
介绍
我们通常都习惯寻找一个事物在一段时间里的变化规律。在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等。一个最适用的例子就是天气的预测。
首先,本文会介绍声称概率模式的系统,用来预测天气的变化
然后,我们会分析这样一个系统,我们希望预测的状态是隐藏在表象之后的,并不是我们观察到的现象。比如,我们会根据观察到的植物海藻的表象来预测天气的状态变化。
最后,我们会利用已经建立的模型解决一些实际的问题,比如根据一些列海藻的观察记录,分析出这几天的天气状态。
Generating Patterns
有两种生成模式:确定性的和非确定性的。
确定性的生成模式 :就好比日常生活中的红绿灯,我们知道每个灯的变化规律是固定的。我们可以轻松的根据当前的灯的状态,判断出下一状态。

非确定性的生成模式: 比 如说天气晴、多云、和雨。与红绿灯不同,我们不能确定下一时刻的天气状态,但是我们希望能够生成一个模式来得出天气的变化规律。我们可以简单的假设当前的 天气只与以前的天气情况有关,这被称为马尔科夫假设。虽然这是一个大概的估计,会丢失一些信息。但是这个方法非常适于分析。
马尔科夫过程就是当前的状态只与前n个状态有关。这被称作n阶马尔科夫模型。最简单的模型就当n=1时的一阶模型。就当前的状态只与前一状态有关。(这里要注意它和确定性生成模式的区别,这里我们得到的是一个概率模型)。下图是所有可能的天气转变情况:

对于有M个状态的一阶马尔科夫模型,共有M*M个状态转移。每一个状态转移都有其一定的概率,我们叫做转移概率,所有的转移概率可以用一个矩阵表示。在整个建模的过程中,我们假设这个转移矩阵是不变的。

该矩阵的意义是:如果昨天是晴,那么今天是晴的概率为0.5,多云的概率是0.25,雨的概率是0.25。注意每一行和每一列的概率之和为1。
另外,在一个系统开始的时候,我们需要知道一个初始概率,称为![]() 向量。
向量。

到现在,我们定义了一个一阶马尔科夫模型,包括如下概念:
状态:晴、多云、雨
状态转移概率
初始概率
马尔科夫模型也需要改进!
当 一个隐士不能通过直接观察天气状态来预测天气时,但他有一些水藻。民间的传说告诉我们水藻的状态与天气有一定的概率关系。也就是说,水藻的状态与天气时紧 密相关的。此时,我们就有两组状态:观察状态(水藻的状态)和隐含状态(天气状态)。因此,我们希望得到一个算法可以为隐士通过水藻和马尔科夫过程,在没 有直接观察天气的情况下得到天气的变化情况。
更容易理解的一个应用就是语音识别,我们的问题定义就是如何通过给出的语音信号预测出原来的文字信息。在这里,语音信号就是观察状态,识别出的文字就是隐含状态。
这里需要注意的是,在任何一种应用中,观察状态的个数与隐含状态的个数有可能不一样的。下面我们就用隐马尔科夫模型HMM来解决这类问题。
HMM
下图是天气例子中两类状态的转移图,我们假设隐状态是由一阶马尔科夫过程描述,因此他们相互连接。


HMM 定义
HMM是一个三元组 (![]() ,A,B).
,A,B).
![]() the vector of the initial state probabilities;
the vector of the initial state probabilities;
![]() the state transition matrix;
the state transition matrix; ![]()
![]() the confusion matrix;
the confusion matrix; ![]()
这其中,所有的状态转移概率和混淆概率在整个系统中都是一成不变的。这也是HMM中最不切实际的假设。
HMM的应用
有三个主要的应用:前两个是模式识别后一个作为参数估计
(1) 评估
根据已知的HMM找出一个观察序列的概率。
这 类问题是假设我们有一系列的HMM模型,来描述不同的系统(比如夏天的天气变化规律和冬天的天气变化规律),我们想知道哪个系统生成观察状态序列的概率最 大。反过来说,把不同季节的天气系统应用到一个给定的观察状态序列上,得到概率最大的哪个系统所对应的季节就是最有可能出现的季节。(也就是根据观察状态 序列,如何判断季节)。在语音识别中也有同样的应用。
我们会用forward algorithm 算法来得到观察状态序列对应于一个HMM的概率。
(2) 解码
根据观察序列找到最有可能出现的隐状态序列
回想水藻和天气的例子,一个盲人隐士只能通过感受水藻的状态来判断天气状况,这就显得尤为重要。我们使用viterbi algorithm 来解决这类问题。
viterbi算法也被广泛的应用在自然语言处理领域。比如词性标注。字面上的文字信息就是观察状态,而词性就是隐状态。通过HMM我们就可以找到一句话上下文中最有可能出现的句法结构。
(3) 学习
从观察序列中得出HMM
这是最难的HMM应用。也就是根据观察序列和其代表的隐状态,生成一个三元组HMM (![]() ,A,B)。使这个三元组能够最好的描述我们所见的一个现象规律。
,A,B)。使这个三元组能够最好的描述我们所见的一个现象规律。
我们用forward-backward algorithm 来解决在现实中经常出现的问题--转移矩阵和混淆矩阵不能直接得到的情况。
总结 HMM可以解决的三类问题
- Matching the most likely system to a sequence of observations -evaluation, solved using the forward algorithm;
- determining the hidden sequence most likely to have generated a sequence of observations - decoding, solved using the Viterbi algorithm;
- determining the model parameters most likely to have generated a sequence of observations - learning, solved using the forward-backward algorithm.
四、隐马尔科夫模型(Hidden Markov Models)
1、定义(Definition of a hidden Markov model)
一个隐马尔科夫模型是一个三元组(pi, A, B)。
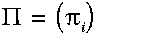 :初始化概率向量;
:初始化概率向量;
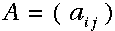 :状态转移矩阵;
:状态转移矩阵;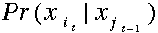
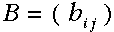 :混淆矩阵;
:混淆矩阵;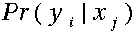
在状态转移矩阵及混淆矩阵中的每一个概率都是时间无关的——也就是说,当系统演化时这些矩阵并不随时间改变。实际上,这是马尔科夫模型关于真实世界最不现实的一个假设。
2、应用(Uses associated with HMMs)
一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态序列(解码)。第三个问题是给定观察序列生成一个HMM(学习)。
a) 评估(Evaluation)
考虑这样的问题,我们有一些描述不同系统的隐马尔科夫模型(也就是一些( pi,A,B)三元组的集合)及一个观察序列。我们想知道哪一个HMM最有可能产生了这个给定的观察序列。例如,对于海藻来说,我们也许会有一个“夏季”模型和一个“冬季”模型,因为不同季节之间的情况是不同的——我们也许想根据海藻湿度的观察序列来确定当前的季节。
我们使用前向算法(forward algorithm)来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率,并因此选择最合适的隐马尔科夫模型(HMM)。
在语音识别中这种类型的问题发生在当一大堆数目的马尔科夫模型被使用,并且每一个模型都对一个特殊的单词进行建模时。一个观察序列从一个发音单词中形成,并且通过寻找对于此观察序列最有可能的隐马尔科夫模型(HMM)识别这个单词。
b) 解码( Decoding)
给定观察序列搜索最可能的隐藏状态序列。
另一个相关问题,也是最感兴趣的一个,就是搜索生成输出序列的隐藏状态序列。在许多情况下我们对于模型中的隐藏状态更感兴趣,因为它们代表了一些更有价值的东西,而这些东西通常不能直接观察到。
考虑海藻和天气这个例子,一个盲人隐士只能感觉到海藻的状态,但是他更想知道天气的情况,天气状态在这里就是隐藏状态。
我们使用Viterbi 算法(Viterbi algorithm)确定(搜索)已知观察序列及HMM下最可能的隐藏状态序列。
Viterbi算法(Viterbi
algorithm)的另一广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单
词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标
注。
C)学习(Learning)
根据观察序列生成隐马尔科夫模型。
第三个问题,也是与HMM相关的问题中最难的,根据一个观察序列(来自于已知的集合),以及与其有关的一个隐藏状态集,估计一个最合适的隐马尔科夫模型(HMM),也就是确定对已知序列描述的最合适的(pi,A,B)三元组。
当矩阵A和B不能够直接被(估计)测量时,前向-后向算法(forward-backward algorithm)被用来进行学习(参数估计),这也是实际应用中常见的情况。
3、总结(Summary)
由一个向量和两个矩阵(pi,A,B)描述的隐马尔科夫模型对于实际系统有着巨大的价值,虽然经常只是一种近似,但它们却是经得起分析的。隐马尔科夫模型通常解决的问题包括:
1. 对于一个观察序列匹配最可能的系统——评估,使用前向算法(forward algorithm)解决;
2. 对于已生成的一个观察序列,确定最可能的隐藏状态序列——解码,使用Viterbi 算法(Viterbi algorithm)解决;
3. 对于已生成的观察序列,决定最可能的模型参数——学习,使用前向-后向算法(forward-backward algorithm)解决。
未完待续:前向算法1
本文翻译自:http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
部分翻译参考:隐马尔科夫模型HMM自学
转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:http://www.52nlp.cn/hmm-learn-best-practices-four-hidden-markov-models
http://blog.sciencenet.cn/blog-641976-533895.html

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号