
Pytorch 分布式训练
Pytorch DDP分布式训练介绍
近期一直在用torch的分布式训练,本文调研了目前Pytorch的分布式并行训练常使用DDP模式(Distributed DataParallell ),从基本概念,初始化启动,以及第三方的分布式训练框架展开介绍。最后以一个Bert情感分类给出完整的代码例子:torch-ddp-examples。
基本概念
DistributedDataParallel(DDP)是依靠多进程来实现数据并行的分布式训练方法(简单说,能够扩大batch_size,每个进程负责一部分数据)。在使用DDP分布式训练前,有几个概念或者变量,需要弄清楚,这样后面出了bug大概知道从哪里入手,包括:
- group: 进程组,一般就需要一个默认的
- world size: 所有的进程数量
- rank: 全局的进程id
- local rank:某个节点上的进程id
- local_word_size: 某个节点上的进程数 (相对比较少见)
这里需要注意的是,目前为止所有的概念的基本单元都是进程,与GPU没有关系,一个进程可以对应若干个GPU。 所以world_size 并不是等于所有的GPU数量,而人为设定的,这一点网上的很多描述并不准确。只不过平时用的最多的情况是一个进程使用一块GPU,这种情况下 world_size 可以等于所有节点的GPU数量。
假设所有进程数即 world_size为W,每个节点上的进程数即local_world_size为L,则每个进程上的两个ID:
- rank的取值范围:[0, W-1],rank=0的进程为主进程,会负责一些同步分发的工作
- local_rank的取值:[0, L-1]
官方的示意图的非常形象,如下,
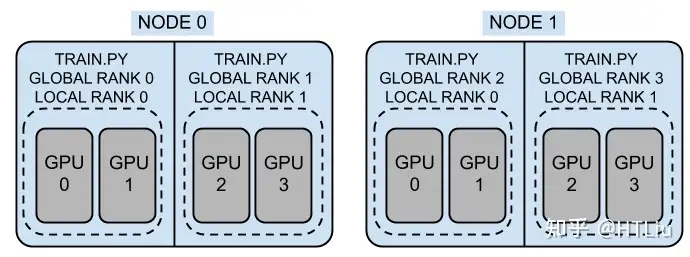
假定有2个机器或者节点,每个机器上有4块GPU。图中一共有4个进程,即world_size=4,那这样每个进程占用两块GPU,其中rank就是[0,1,2,3],每个节点的local_rank就是[0,1]了,其中local_world_size 也就是2。 这里需要注意的是,local_rank是隐式参数,即torch自动分配的。比如local_rank 可以通过自动注入命令行参数或者环境变量来获得) 。
从torch1.10开始,官方建议使用环境变量的方式来获取local_rank, 在后期版本中,会移除命令行的方式。
一些简单的测试:
import torch.distributed as dist
import argparse, os
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=ine, default=0)
args = parser.parse_args()
dist.init_process_group("nccl")
rank = dist.get_rank()
local_rank_arg = args.local_rank # 命令行形式ARGS形式
local_rank_env = int(os.environ['LOCAL_RANK']) # 在利用env初始ENV环境变量形式
local_world_size = int(os.environ['LOCAL_WORLD_SIZE'])
print(f"{rank=}; {local_rank_arg=}; {local_rank_env=}; {local_world_size=}")使用python3 -m torch.distributed.launch --nproc_per_node=4 test.py 在一台4卡机器上执行, 样例输出:
rank=2; local_rank_arg=2; local_rank_env=2, local_world_size=4
rank=0; local_rank_arg=0; local_rank_env=0, local_world_size=4
rank=3; local_rank_arg=3; local_rank_env=3, local_world_size=4
rank=1; local_rank_arg=1; local_rank_env=1, local_world_size=4一般的分布式训练都是为每个进程赋予一块GPU,这样比较简单而且容易调试。 这种情况下,可以通过local_rank作为当前进程GPU的id。
分布式训练的场景很多,单机多卡,多机多卡,模型并行,数据并行等等。接下来就以常见的单机多卡的情况进行记录。
DDP启动
初始化
torch的distributed分布式训练首先需要对进程组进行初始化,这是核心的一个步骤,其关键参数如下:
torch.distributed.init_process_group(backend, init_method=None, world_size=-1, rank=-1, store=None,...)首先需要指定分布式的后端,torch提供了NCCL, GLOO,MPI三种可用的后端,这三类支持的分布式操作有所不同,因此选择的时候,需要考虑具体的场景,按照官网说明,CPU的分布式训练选择GLOO, GPU的分布式训练就用NCCL即可。
接下来是初始化方法,有两种方法:
- 显式指定
init_method,可以是TCP连接、File共享文件系统、ENV环境变量三种方式,后面具体介绍。 - 显式指定
store,同时指定world_size 和 rank参数。这里的store是一种分布式中核心的key-value存储,用于不同的进程间共享信息。
这两种方法是互斥的,其实本质上第一种方式是对第二种的一个更高的封装,最后都要落到store上进行实现。如果这两种方法都没有使用,默认使用init_method='env'的方式来初始化。
对于三种init_method:
init_method='tcp://ip:port': 通过指定rank 0(即:MASTER进程)的IP和端口,各个进程进行信息交换。 需指定 rank 和 world_size 这两个参数。init_method='file://path':通过所有进程都可以访问共享文件系统来进行信息共享。需要指定rank和world_size参数。init_method=env://:从环境变量中读取分布式的信息(os.environ),主要包括MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE。 其中,rank和world_size可以选择手动指定,否则从环境变量读取。
可以发现,tcp和env两种方式比较类似(其实env就是对tcp的一层封装),都是通过网络地址的方式进行通信,也是最常用的初始化方法。
接下来看具体TCP/ENV初始化的的一个小例子:
import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
if args.init_method == 'TCP':
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)假设单机双卡的机器上运行,则开两个终端,同时运行下面的命令,
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV如果开启的进程未达到 word_size 的数量,则所有进程会一直等待,直到都开始运行,可以得到输出如下:
# rank0 的终端:
rank 0 is initialized
tensor([1, 2, 3, 4], device='cuda:0')
# rank1的终端
rank 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')可以看出,在初始化DDP的时候,能够给后端提供主进程的地址端口、本身的RANK,以及进程数量即可。初始化完成后,就可以执行很多分布式的函数了,比如dist.get_rank, dist.all_gather等等。
上面的例子是最基本的使用方法,需要手动运行多个程序,相对繁琐。实际上本身DDP就是一个python 的多进程,因此完全可以直接通过多进程的方式来启动分布式程序。 torch提供了以下两种启动工具来更加方便的运行torch的DDP程序。
mp.spawn
第一种方法便是使用torch.multiprocessing(python的multiprocessing的封装类) 来自动生成多个进程,使用方法也很简单,先看看基本的调用函数spawn:
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False)其中:
- fn: 进程的入口函数,该函数的第一个参数会被默认自动加入当前进程的rank, 即实际调用:
fn(rank, *args) - nprocs: 进程数量,即:world_size
- args: 函数fn的其他常规参数以tuple的形式传递
具体看一个例子:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def fn(rank, ws, nums):
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765',
rank=rank, world_size=ws)
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
torch.cuda.set_device(rank)
tensor = torch.tensor(nums).cuda()
print(tensor)
if __name__ == "__main__":
ws = 2
mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))直接执行一次命令 python3 test_ddp.py 即可,输出如下:
rank = 0 is initialized
rank = 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')这种方式同时适用于TCP和ENV初始化。
launch/run
第二种方法则是torch提供的 torch.distributed.launch工具,可以以模块的形式直接执行:
python3 -m torch.distributed.launch --配置 train.py --args参数常用配置有:
- --nnodes: 使用的机器数量,单机的话,就默认是1了
- --nproc_per_node: 单机的进程数,即单机的worldsize
- --master_addr/port: 使用的主进程rank0的地址和端口
- --node_rank: 当前的进程rank
在单机情况下, 只有--nproc_per_node 是必须指定的,--master_addr/port和node_rank都是可以由launch通过环境自动配置,举例如下:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)使用也很方便,通过python3 -m torch.distribued.launch --nproc_per_node=2 test_ddp.py 运行,输出如下:
rank = 0 is initialized in 127.0.0.1:29500; local_rank = 0
rank = 1 is initialized in 127.0.0.1:29500; local_rank = 1
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')torch1.10开始用终端命令torchrun来代替torch.distributed.launch,具体来说,torchrun实现了launch的一个超集,不同的地方在于:
- 完全使用环境变量配置各类参数,如
RANK,LOCAL_RANK, WORLD_SIZE等,尤其是local_rank不再支持用命令行隐式传递的方式 - 能够更加优雅的处理某个worker失败的情况,重启worker。需要代码中有
load_checkpoint(path)和save_checkpoint(path)这样有worker失败的话,可以通过load最新的模型,重启所有的worker接着训练。具体参考 imagenet-torchrun - 训练的节点数目可以弹性变化。
同样上面的代码,直接使用 torchrun --nproc_per_node=2 test_gpu.py 运行即可,不用写那么长长的命令了。
需要注意的是, torchrun或者launch对上面ENV的初始化方法支持最完善,TCP初始化方法的可能会出现问题,因此尽量使用env来初始化dist。
DDP模型训练
上面部分介绍了一些细节如何启动分布式训练,接下来介绍如何把单机训练模型的代码改成分布式运行。基本流程如下:
- 分布式训练数据加载。Dataloader需要把所有数据分成N份(N为worldsize), 并能正确的分发到不同的进程中,每个进程可以拿到一个数据的子集,不重叠,不交叉。这部分工作靠 DistributedSampler完成,具体的函数签名如下:
torch.utils.data.distributed.DistributedSampler(dataset,
num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)- dataset: 需要加载的完整数据集
- num_replicas: 把数据集分成多少份,默认是当前dist的world_size
- rank: 当前进程的id,默认从dist的rank
- shuffle:是否打乱
- drop_last: 如果数据长度不能被world_size整除,可以考虑是否将剩下的扔掉
- seed:随机数种子。这里需要注意,从源码中可以看出,真正的种子其实是
self.seed+self.epoch这样的好处是,不同的epoch每个进程拿到的数据是不一样,因此需要在每个epoch开始前设置下:sampler.set_epoch(epoch)
其实Sampler的实现也很简单,核心代码就一句:
indices[self.rank: self.total_size: self.num_replicas]
假设4卡12条数据的话,rank=0,1,2,3, num_replicas=4, 那么每个卡取的数据索引就是:
rank0: [0 4 8]; rank1: [1 5 9]; rank2: [2 6 10]; rank3: [3 7 11]
保证不重复不交叉。这样在分布式训练的时候,只需要给Dataloader指定DistributedSampler即可,简单示例如下:
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for epoch in range(start_epoch, n_epochs):
sampler.set_epoch(epoch) # 设置epoch 更新种子
train(loader)- 模型的分布式训练封装。将单机模型使用
torch.nn.parallel.DistributedDataParallel进行封装,如下:
torch.cuda.set_device(local_rank)
model = Model().cuda()
model = DistributedDataParallel(model, device_ids=[local_rank])
# 要调用model内的函数或者属性. model.module.xxxx这样在多卡训练时,每个进程有一个model副本和optimizer,使用自己的数据进行训练,之后反向传播计算完梯度的时候,所有进程的梯度会进行all-reduce操作进行同步,进而保证每个卡上的模型更新梯度是一样的,模型参数也是一致的。
这里有一个需要注意的地方,在save和load模型时候,为了减小所有进程同时读写磁盘,一般处理方法是以主进程为主,rank0先save模型,在map到其他进程。这样的另外一个好处,在最开始训练时,模型随机初始化之后,保证了所有进程的模型参数保持一致。
【注:其实在torch的DDP封装的时候,已经做到了这一点,即使开始随机初始化不同,经过DDP封装,所有进程都一样的参数】简洁代码如下:
model = DistributedDataParallel(model, device_ids=[local_rank])
CHECKPOINT_PATH ="./model.checkpoint"
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# barrier()其他保证rank 0保存完成
dist.barrier()
map_location = {"cuda:0": f"cuda:{local_rank}"}
model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))
# 后面正常训练代码
optimizer = xxx
for epoch:
for data in Dataloader:
model(data)
xxx
# 训练完成 只需要保存rank 0上的即可
# 不需要dist.barrior(), all_reduce 操作保证了同步性
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)总结一下的话,使用DDP分布式训练的话,一共就如下个步骤:
- 初始化进程组
dist.init_process_group - 设置分布式采样器
DistributedSampler - 使用
DistributedDataParallel封装模型 - 使用
torchrun或者mp.spawn启动分布式训练
补充一点使用分布式做evaluation的时候,一般需要先所有进程的输出结果进行gather,再进行指标的计算,两个常用的函数:
dist.all_gather(tensor_list, tensor): 将所有进程的tensor进行收集并拼接成新的tensorlist返回,比如:dist.all_reduce(tensor, op)这是对tensor的in-place的操作, 对所有进程的某个tensor进行合并操作,op可以是求和等:
import torch
import torch.distributed as dist
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.arange(2) + 1 + 2 * rank
tensor = tensor.cuda()
print(f"rank {rank}: {tensor}")
tensor_list = [torch.zeros_like(tensor).cuda() for _ in range(2)]
dist.all_gather(tensor_list, tensor)
print(f"after gather, rank {rank}: tensor_list: {tensor_list}")
dist.barrier()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"after reduce, rank {rank}: tensor: {tensor}")通过torchrun --nproc_per_node=2 test_ddp.py 输出结果如下:
rank 1: tensor([3, 4], device='cuda:1')
rank 0: tensor([1, 2], device='cuda:0')
after gather, rank 1: tensor_list: [tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')]
after gather, rank 0: tensor_list: [tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')]
after reduce, rank 0: tensor: tensor([4, 6], device='cuda:0')
after reduce, rank 1: tensor: tensor([4, 6], device='cuda:1')在evaluation的时候,可以拿到所有进程中模型的输出,最后统一计算指标,基本流程如下:
pred_list = []
for data in Dataloader:
pred = model(data)
batch_pred = [torch.zeros_like(label) for _ in range(world_size)]
dist.all_gather(batch_pred, pred)
pred_list.extend(batch_pred)
pred_list = torch.cat(pred_list, 1)
# 所有进程pred_list是一致的,保存所有数据模型预测的值第三方库
前面一部分基本介绍了Pytorch DDP的基本概念,启动方式和如何将单进程代码 改成分布式训练的步骤,总体来看,其实DDP的使用方法已经足够简洁了。 不过近年来还是产生了不少优秀的封装更加higher,使用起来更简单的分布式训练库,本文主要介绍2个亲测还不错的框架。
其实不管哪个分布式框架,都是把上述的几个流程进行一层封装【初始化、包装模型、优化器、数据加载】。一般从以下几个方面衡量框架的易用性:
- 支持分布式训练模式丰富,如CPU,单机单卡,单机多卡,多机多卡,FP16等
- 代码简单,不需要改动大量代码即可进行分布式训练
- 接口丰富,方便自定义。比如能调用和访问底层分布式的一些变量如rank,worldsize,或实现或封装一些分布式函数,比如dist.gather/reduce等。
Accelerator
第一个是由大名鼎鼎的huggingface发布的Accelerator,专门适用于Pytorch的分布式训练框架:
将单进程代码改为多进程分布式的非常简单:
import accelerate
accelerator = accelerate.Accelerator()
device = accelerator.device #获取当前进程的设备
...
# 进行封装
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
#训练时 loss.backward() 换为:
accelerator.backward(loss)运行方法使用CLI命令行的方式,先使用accelerator config 配置一次分布式训练的参数,之后就使用 acceleratoe launch运行。具体的可以看官网例子。
除此之外,accelerator还提供了一些很便利的接口,基本覆盖了分布式训练中需要用到的方法,比如:
accelerator.print:仅仅在主进程输出accelerator.process_index: 当前进程ID,没有使用rank命名,而是用的process_index来表示accelerator.is_local_main_process/is_main_processs:: 是否local_rank 或则rank为0, 主进程accelerator.wait_for_everyone(): 类似 dist.barrier() , 等所有进程到达这一步。accelerator.save: 保存模型kwargs_handlers: 可以定义DDP初始化的一些参数,比如最常用的就是 find_unused_parameters,比如:
import accelerate
from accelerate import DistributedDataParallelKwargs as DDPK
kwargs = DDPK(find_unused_parameters=True)
accelerator = accelerate.Accelerator(kwargs_handlers=[kwargs])总体来说,accelerator这个库基本已经满足使用Pytorch进行分布训练的需求。 而且十分的符合huggingface的风格,把某个小项目做到最好用,类似的还有transformers, tokenizers, datasets等等。
不足的话,就是accelerate支持的collective function比较少,目前只有all_gather。
Horovod
第二个常用的分布式库Horovod是一个通用的深度学习分布式训练框架,支持Tensorflow,Pytorch,MXNet,Keras等等,因此比Accelerator要更加重些,但是功能也会更加丰富,这里以Pytorch为例来简单介绍。多说一下,Horovod的安装相对复杂一些,需要针对具体的环境参考readme进行安装。
Horovod的使用也很简单,基本也是那几个流程:
import horovod.torch as hvd
# 初始化
hvd.init()
# Samapler
# *此处num_replicas=hvd.size(), rank=hvd.rank()必须*
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
# 优化器包装
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# 模型分发广播
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
# 模型训练不需要修改horovod支持的运行方式非常多,最常用的就是horovodrun了,比如单机四卡运行:
horovodrun -np 4 -H localhost:4 python3 train.pyhorovod相比accelerate来说,功能更加丰富,支持的接口,函数,框架都要多, 比如 hvd.all_reduce, hvd.all_gather等等。
综合看,这两个其实都是非常易用的分布式框架了,选择哪个都可以。 当然除了这两个外, 还有一些其他的,比如pytorch-lightning,deepspeed这里就不多介绍了。
最后,以bert情感分类为例子,介绍了如何使用原生DDP和上面2个框架来进行分布式训练,代码见:https://github.com/ShomyLiu/torch-ddp-examples
总结
总算把这篇鸽了很旧的博客写完了, 内容比较基础。目前网上一些教程要么直接给出一个代码例子,要么翻译下官方的例子或者API,很少有比较系统完整的讲解。 本文算是结合自己在用分布式训练时候遇到的一些问题或者困惑来展开介绍的。 其实分布式训练是非常复杂的,比如需要考虑弹性训练恢复等,本文并未涉及。 文中有不严谨的地方,欢迎指出。
参考

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号