
PEGASUS:SOTA的抽象文本摘要模型
学生的任务通常是阅读文档并生成摘要(例如读书报告),以展示阅读理解和写作能力。这种抽象文本摘要是自然语言处理中最具挑战性的任务之一,涉及理解长段落、信息压缩和语言生成。训练机器学习模型以执行此操作的主要范例是序列到序列(seq2seq) 学习,其中神经网络学习将输入序列映射到输出序列。虽然这些 seq2seq 模型最初是使用递归神经网络开发的,但 Transformer编码器-解码器模型最近受到青睐,因为它们可以更有效地对摘要中遇到的长序列中存在的依赖项进行建模。
结合自监督预训练的 Transformer 模型(例如,BERT、GPT-2、 RoBERTa、XLNet、ALBERT、T5、ELECTRA) 已被证明是产生通用语言学习的强大框架,在对广泛的语言任务进行微调时可实现最先进的性能。在之前的工作中,预训练中使用的自我监督目标在某种程度上与下游应用无关,有利于通用性;我们想知道如果自我监督的目标更接近最终任务,是否可以实现更好的性能。
在“ PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization ”(将出现在2020 年国际机器学习会议上)中,我们设计了一个预训练自监督目标(称为gap-sentence generation) 用于 Transformer 编码器-解码器模型,以提高抽象摘要的微调性能,在 12 个不同的摘要数据集上取得最先进的结果。作为本文的补充,我们还在GitHub上发布了训练代码和模型检查点。
自我监督的总结目标
我们的假设是预训练自监督目标越接近最终的下游任务,微调性能越好。在 PEGASUS 预训练中,从文档中删除了几个完整的句子,模型的任务是恢复它们。预训练的示例输入是缺少句子的文档,而输出由串联在一起的缺失句子组成。这是一项极其艰巨的任务,甚至对于人来说似乎也是不可能的,我们也不期望模型能够完美地解决它。然而,这样一项具有挑战性的任务鼓励模型学习语言和关于世界的一般事实,以及如何从整个文档中提取信息以生成与微调摘要任务非常相似的输出。
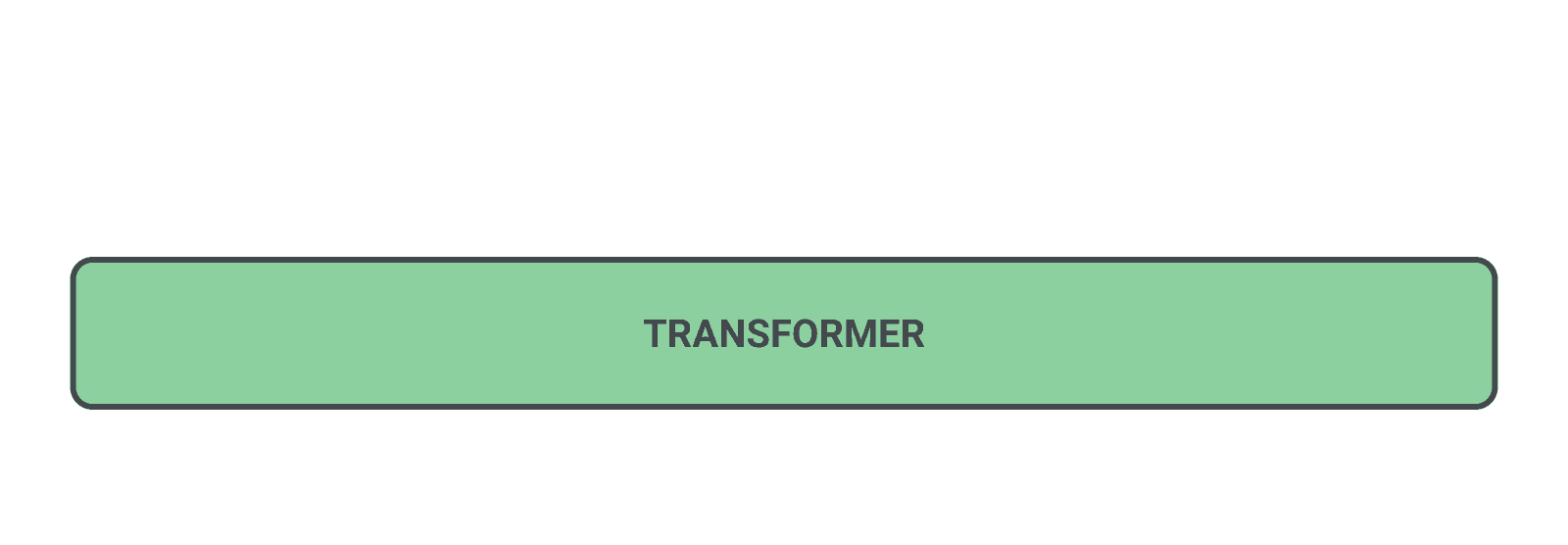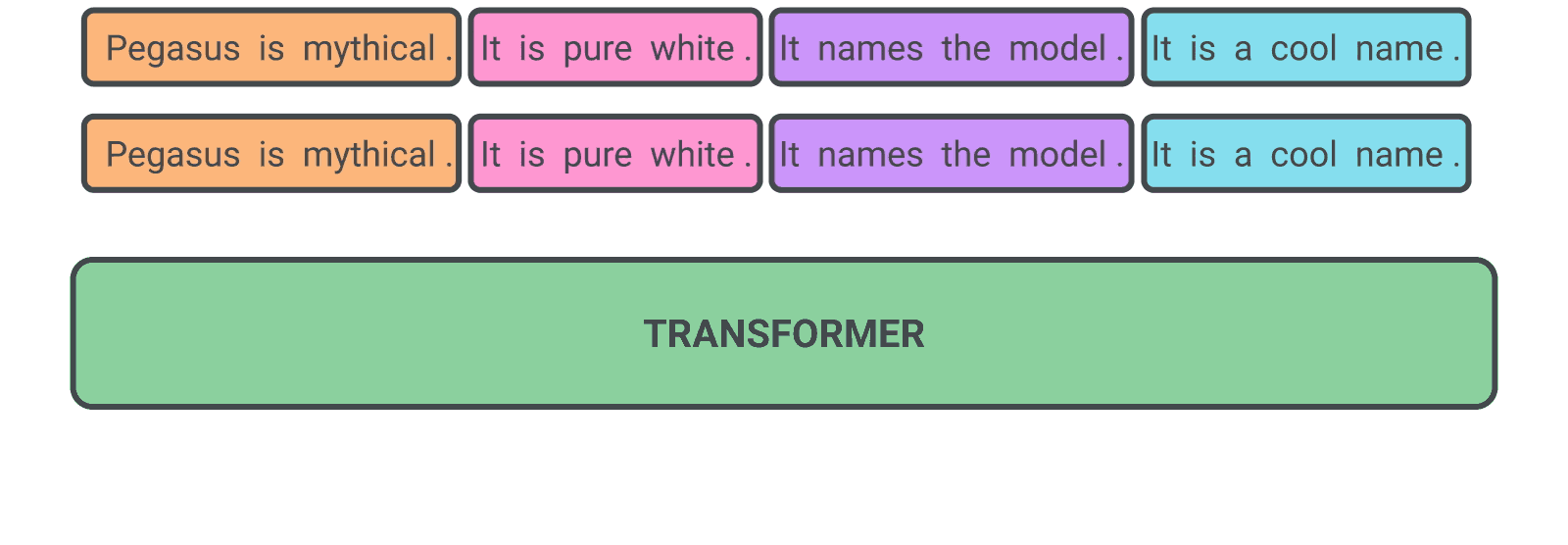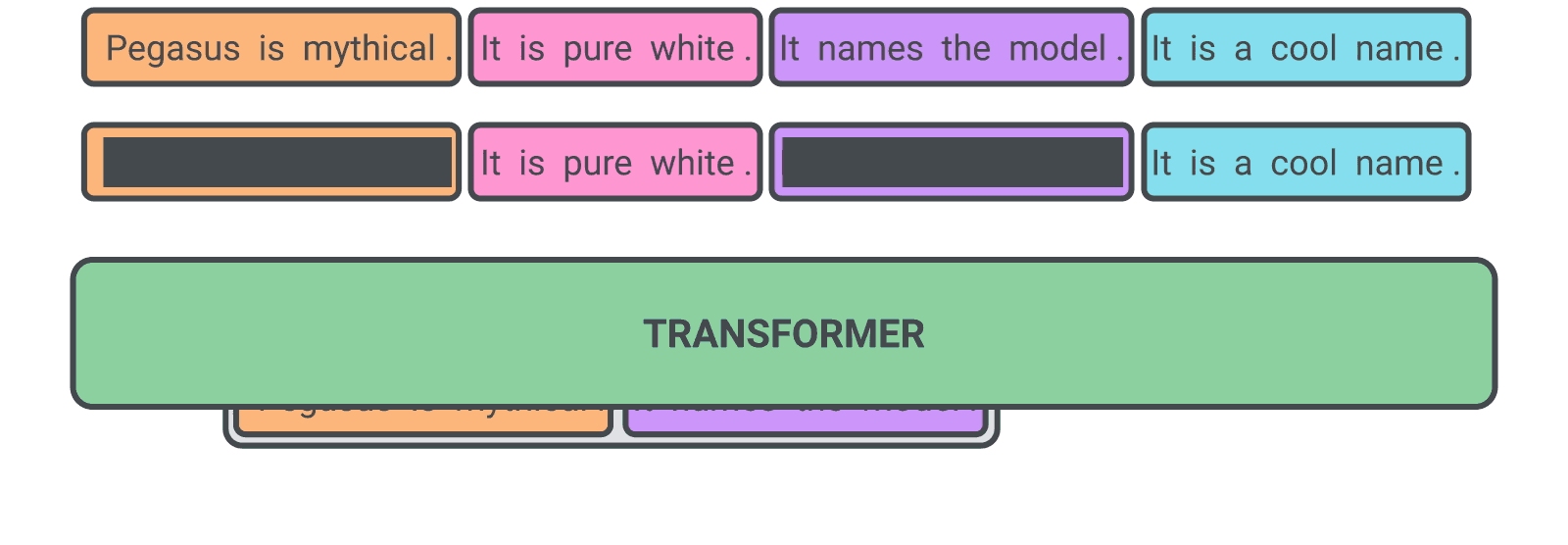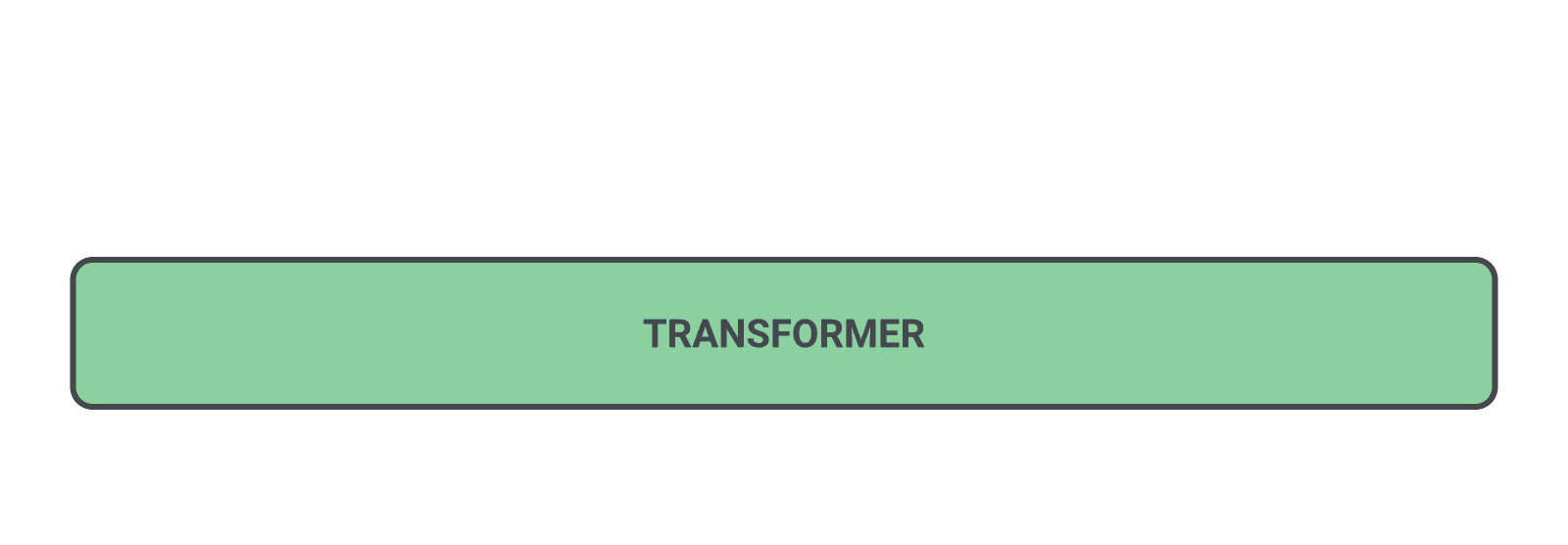 |
| 预训练期间 PEGASUS 的自我监督示例。该模型被训练为输出所有被屏蔽的句子。 |
类似于其他最近的方法,例如T5,我们在一个非常大的网络抓取文档语料库上预训练了我们的模型,然后我们在 12 个公共下游抽象摘要数据集上对模型进行了微调,从而产生了新的最先进的结果,通过自动测量指标,而仅使用 T5 参数数量的 5%。选择的数据集多种多样,包括新闻文章、科学论文、专利、短篇小说、电子邮件、法律文件和操作指南,表明该模型框架适用于广泛的主题。
使用少量示例进行微调
虽然 PEGASUS 在大型数据集上表现出卓越的性能,但我们惊讶地发现该模型不需要大量示例即可进行微调以接近最先进的性能:
 |
| ROUGE分数(三个变体,越高越好)与四个选定摘要数据集中的监督示例数量。虚线显示了具有完全监督但没有预训练的 Transformer 编码器-解码器性能。 |
人类素质总结
虽然我们发现诸如 ROUGE 之类的自动指标是衡量模型开发过程中进度的有用代理,但它们仅提供有限的信息,并不能告诉我们整个故事,例如流畅性或与人类表现的比较。为此,我们进行了人工评估,评估者被要求将我们模型的摘要与人类模型进行比较(不知道哪个是哪个)。这与图灵测试有一些相似之处。
 |
| 人类评分者被要求在不知道哪个是哪个的情况下对模型和人工编写的摘要进行评分。该文件在此处被截断以供说明,但评分者可以看到全文。 |
理解测试:计算船只
在这篇文章之后是一篇示例文章来自 XSum 数据集以及模型生成的抽象摘要。该模型正确地将四艘命名的护卫舰(HMS Cumberland、HMS Campbeltown、HMS Chatham 和 HMS Cornwall)抽象和解释为“四艘皇家海军护卫舰”,这是提取方法无法做到的,因为“四”在任何地方都没有提到。这是侥幸还是模型真的算数?找出答案的一种方法是添加和删除船只以查看计数是否发生变化。
如下图所示,该模型成功地将船只“数”为 2 到 5。但是,当我们添加第六艘船“HMS Alphabet”时,它会将其误算为“七”。因此,该模型似乎已经学会了对列表中的少量项目进行计数,但还没有像我们希望的那样优雅地概括。尽管如此,我们认为这种基本的计数能力令人印象深刻,因为它没有被明确编程到模型中,并且它展示了模型的有限数量的“符号推理”。
PEGASUS 代码和模型发布
为了支持该领域的持续研究并确保可重复性,我们在GitHub上发布了 PEGASUS 代码和模型检查点。这包括可用于使 PEGASUS 适应其他摘要数据集的微调代码。
致谢
这项工作是 Jingqing Zhang、Yao Zhao、Mohammad Saleh 和 Peter J. Liu 的共同努力。我们感谢 T5 和 Google News 团队为 PEGASUS 的预训练提供数据集。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号