
A3C——异步A2C算法
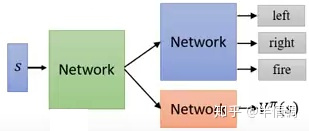
A2C算法是一种强化学习算法,全称为Advantage Actor-Critic算法。它结合了演员评论算法和优势函数,用于学习策略以最大化预期奖励。在A2C算法中,有两个神经网络:一个用于演员,一个用于评论家。演员网络基于当前状态选择动作,评论家网络评估当前状态的价值。优势函数用于估计某个动作相对于平均动作的优越程度。A2C算法的优点是简单易懂,易于实现,而且在小型环境中表现良好。然而,在大型环境中,A2C算法可能会受到训练不稳定、样本效率低等问题的影响。
A3C算法(Asynchronous Advantage Actor-Critic)是A2C算法(Advantage Actor-Critic)的并行化版本。A2C算法是一种强化学习算法,结合了演员评论算法和优势函数,用于学习策略以最大化预期奖励。A3C算法与A2C算法的不同之处在于,它使用多个代理并行运行,并更新共享模型,以加快学习速度和提高性能。因此,A3C算法可以更快地学习到更好的策略,但也需要更多的计算资源。
A2C全称为优势动作评论算法(Advantage Actor Critic)。
A2C使用优势函数代替Critic网络中的原始回报,可以作为衡量选取动作值和所有动作平均值好坏的指标。
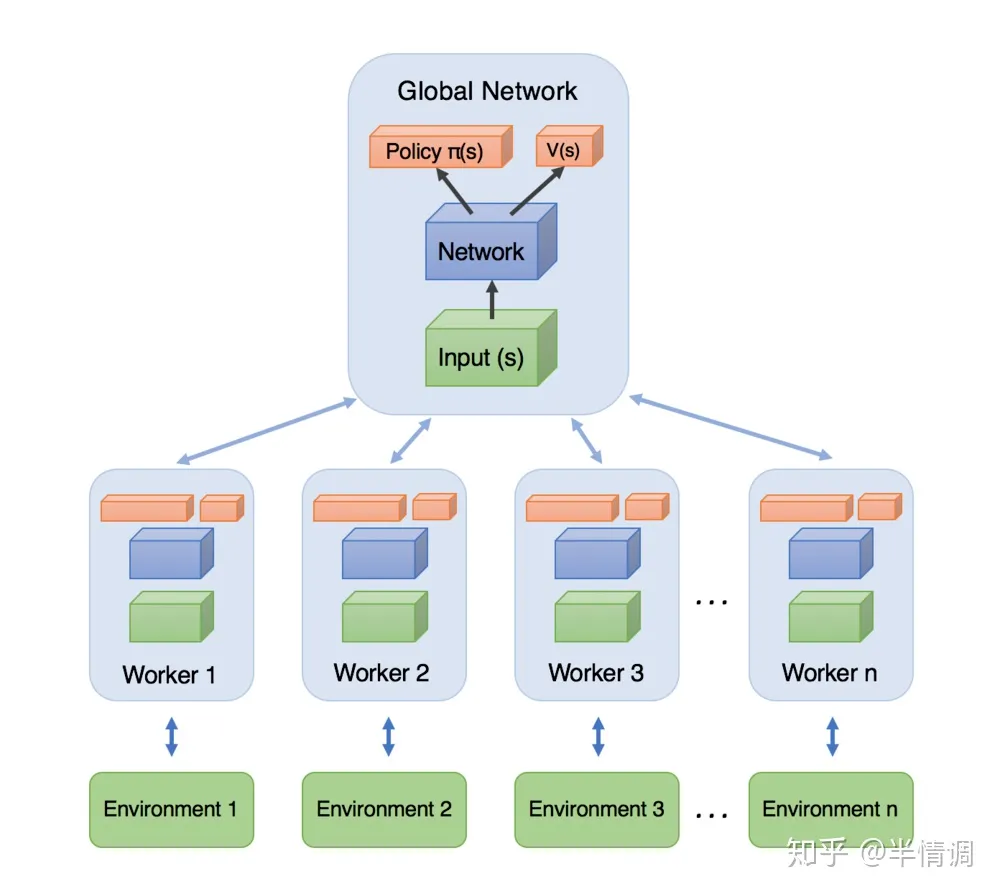
A3C模型如下图所示,每个Worker直接从Global Network中拿参数,自己与环境互动输出行为。利用每个Worker的梯度,对Global Network的参数进行更新。每一个Worker都是一个A2C。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号