
Wandb:模型训练最强辅助

如果说到深度学习中训练数据的记录工具,最先想到应该是TensorBoard(或者TensorBoardX)。不过,相比较TensorBoard而言,Wandb更加的强大,主要体现在以下的几个方面:
- 复现模型:Wandb更有利于复现模型。
这是因为Wandb不仅记录指标,还会记录超参数和代码版本。 - 自动上传云端:
如果你把项目交给同事或者要去度假,Wandb可以让你便捷地查看你制作的所有模型,你就不必花费大量时间来重新运行旧实验。 - 快速、灵活的集成:
只需5分钟即可把Wandb加到自己的项目。
下载Wandb免费的开源Python包,然后在代码中插入几行,以后你每次运行模型都会得到记录完备的指标和记录。 - 集中式指示板:
Wandb提供同样的集中式指示板。不管在哪里训练模型,不管是在本地机器、实验室集群还是在云端实例;
这样就不必花时间从别的机器上复制TensorBoard文件。 - 强大的表格:
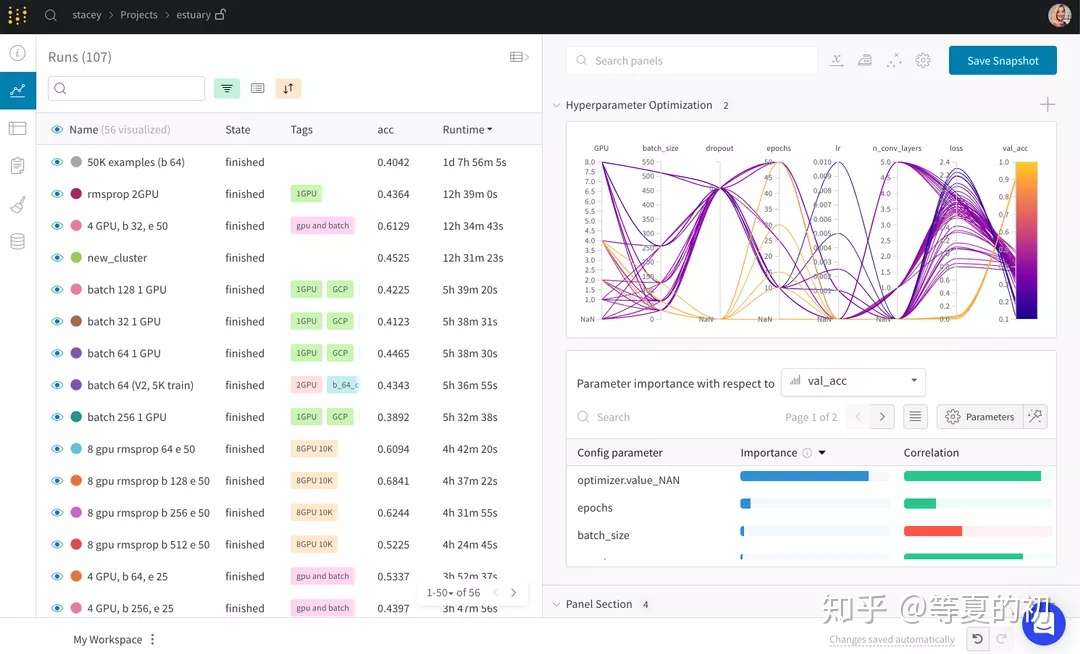
对不同模型的结果进行搜索、筛选、分类和分组。
可以轻而易举地查看成千上万个模型版本,并找到不同任务的最佳模型。
而TensorBoard本身不适合大型项目。
1 Wandb
1.1 功能
- 保存训练运行中使用的超参数
- 搜索、比较和可视化训练的运行
- 在运行的同时分析系统硬件的情况如:CPU和GPU使用率
- 在团队中分享训练数据
- 永远保存可用的实验记录
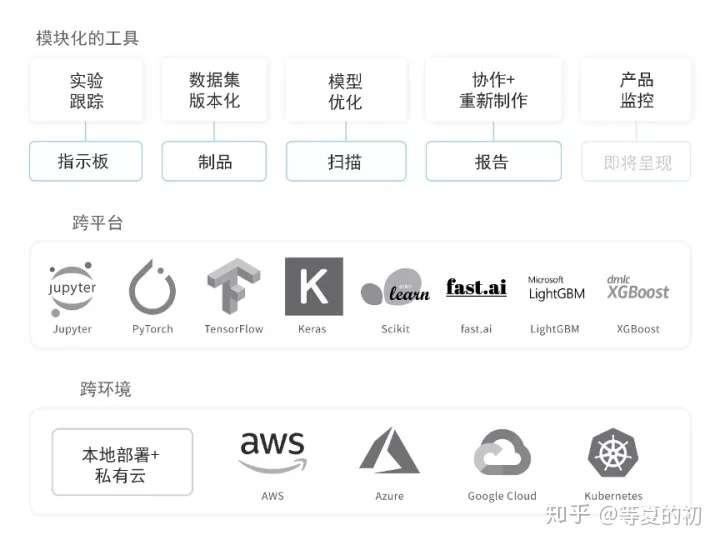
1.2 提供的工具
- Dashboard:记录实验过程、将结果可视化;
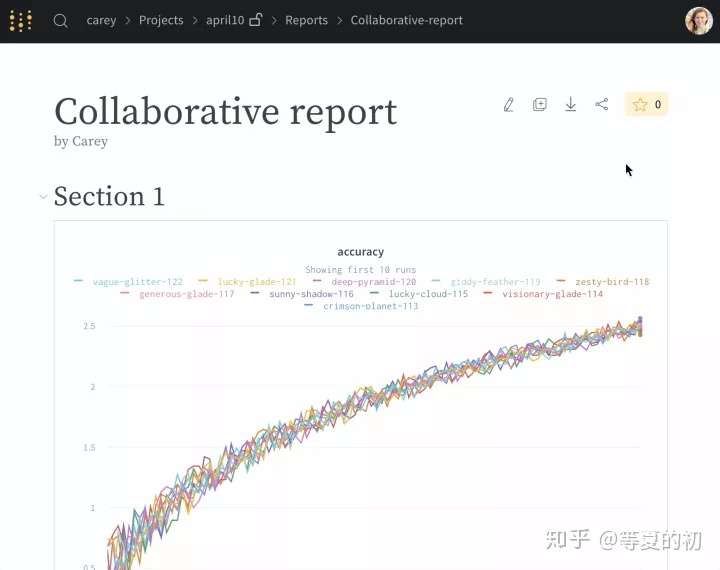
- Reports:保存和分享可复制的成果/结论;
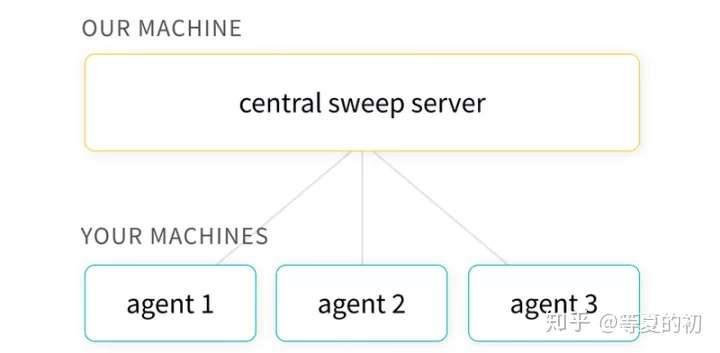
- Sweeps:通过改变超参数来优化模型;
- Artifacts:可以自己搭建pipline实现保存储存数据集和模型以及评估结果的流程。
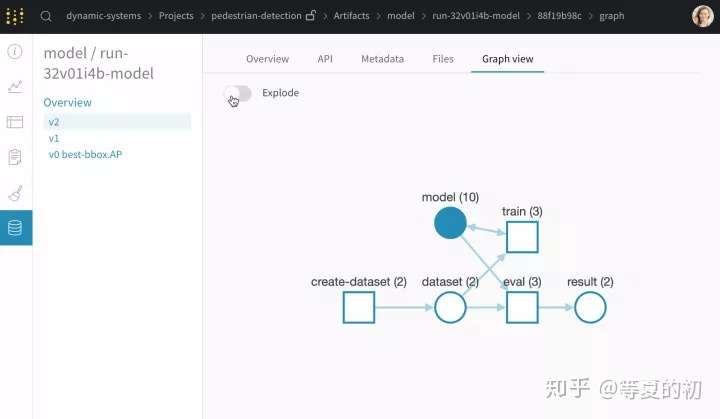
1.3 将会上传哪些内容?Wandb记录的全部数据都保存在本地机器上,位于一个wandb路径,然后同步到云端。(1)自动记录
- 系统指标:处理器和GPU使用率、网络等。由命令nvidia-smi得出这些指标,这些指标位于运行页“系统”选项卡。
- 命令行:记录标准输出和标准错误,并显示于运行页“日志”选项卡。
- git提交:记录最近的git提交,并显示于运行页“概况”选项卡。
- 文件:requirements.txt文件,以及用于运行项并保存在wandb路径的全部文件,将被上传并显示于运行页“文件”选项卡。
(2)有明确调用才记录 当涉及数据和模型指标时,你可以明确决定要记录哪些东西。
- 数据集:你必须明确记录图像或其它数据集样本,这样才能保存到权阈。
- PyTorch梯度:加入wandb.watch(模型),即可在界面中看到权值的梯度直方图。
- 配置(config):记录超参数、数据集链接以及所使用的架构名称,并作为config的参数,传值方式如下:wandb.init(config=your_config_dictionary)
- 指标:用wandb.log()记录模型的参数。如果你记录的是训练循环内的指标,如准确率、损失,就可以在界面中看到实时更新的图表。
2 Wandb的五行代码使用法
Wandb 基本接口如下:
wandb.init — 在训练脚本开头初始化一个新的运行项;
wandb.config — 跟踪超参数;
wandb.log — 在训练循环中持续记录变化的指标;
wandb.save — 保存运行项相关文件,如模型权值;
wandb.restore — 运行指定运行项时,恢复代码状态。对于Any framework,使用wandb的代码如下:
# Flexible integration for any Python script
import wandb
# 1. Start a W&B run
wandb.init(project='gpt3')
# 2. Save model inputs and hyperparameters
config = wandb.config
config.learning_rate = 0.01
# Model training here
# 3. Log metrics over time to visualize performance
wandb.log({"loss": loss})原文链接:https://zhuanlan.zhihu.com/p/342300434

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号