
YOLO v1 ~ YOLO v5 论文解读和实现细节
戴思达
YOLOv1
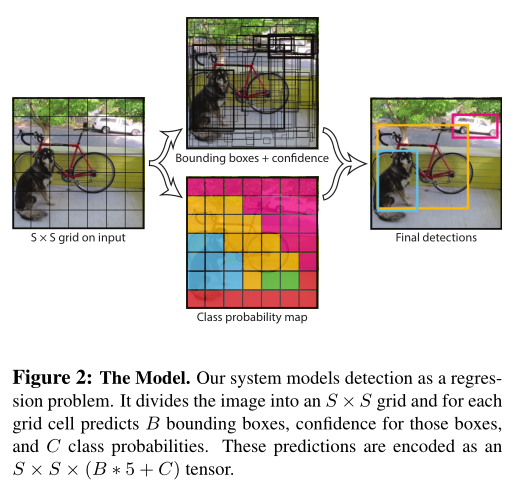
使用来自整张图像的特征来预测每个bounding box
将整张图分成S*S的网格,如果一个物体的中心落在某个网格中,就用该网格检测这个物体。
每个网格预测B个bounding box,以及对应的置信度。
置信度的含义:
- 模型确定这个box包含有物体的程度
- 模型认为box属于预测出来的物体的准确程度
置信度的定义:
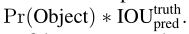
也就是,cell里边没有物体时,等于零,否则,等于IOU
每个bounding box包括五个预测值:xywh+confidence
(x, y)代表box的中心相对于网格边界的坐标
宽w和高h根据整个图像进行预测
置信度confidence代表预测框和GT之间的IOU
每个网格还预测了C个条件概率:
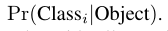
无论每个网格预测的bounding box数目B是多少,我们都只为一个网格预测一组类别概率
在test阶段,将条件概率和每个box的confidence相乘:

得到每个box的每个类别的置信度confidence
这个得分反映了:
- 对应类别在该box中出现的概率
- 预测的box拟合物体位置的程度
对于VOC数据集:
S=7
B=2
C=20
最终预测7*7*30 tensor(30 = 20类的条件概率+(x+y+w+h+confidence)*B)
网络设计
24卷积+2全连接

交替的1*1卷积层:减少特征空间
在ImageNet-1000类上预训练(使用一半的分辨率224*224input),在detection阶段使用448*448
网络的最终输出为7*7*30张量
Fast YOLO:
使用9卷积层而不是24,每层卷积核也更少,其他一样
训练
预训练:
使用前20个卷积层,接平均值池化,最后接全连接
训了大约一个星期,在ImageNet 2012 val set上top-5 acc是88%
训练和推断使用darknet框架
依据文献[29],向预训练网络增加卷积层和连接层可以增强performance
[29] S. Ren, K. He, R. B. Girshick, X. Zhang, and J. Sun. Object detection networks on convolutional feature maps. CoRR, abs/1504.06066, 2015. 3, 7
接下来转换模型,用于目标检测:
跟据[29],增加四个卷积层和两个全连接层(随机权重)
detection需要细粒度的视觉信息,因此把输入分辨率从224*224提高到448*448
关于bounding boxd 宽高wh:根据图像宽高,normalize to [0, 1]
关于坐标xy:参数化成相对于某一个网格的偏置,也归一到[0, 1]
结合代码理解:
关于predict_boxes的输出,我们知道predict_boxes的输出是网络前向传播后预测的候选框。固定思维让我们认为,predict_boxes的值就是类似gt_box坐标那样的(x,y,d,h)坐标。错!保持这个固有的思维,这段代码就无法看懂了,我也是不断推测的,才知道实际上道predict_boxes各个坐标的含义。

predict_boxes中心坐标真实含义
其实predict_boxes中的前两位,就是中心点坐标(x,y)代表的含义如上图,是predict_boxes中心坐标离所属格子(response)左上角的坐标。而predict_boxes中的后两位,其实并不是predict_boxes的宽度高度,而是predict_boxes的宽度高度相对于图片的大小(归一化后)的开方。
那么我们所说的输入predict中包含的坐标信息,就不是
(中心横坐标,
中心纵坐标,
宽,
高)
而是
(中心横坐标离所属方格左上角坐标的横向距离(假设每个方格宽度为1),
中心纵坐标离所属方格左上角坐标的纵向距离(假设每个方格高度为1),
宽度(归一化)的开方,
高度(归一化)的开方)
这里理解了,后面理解起来就很easy了。
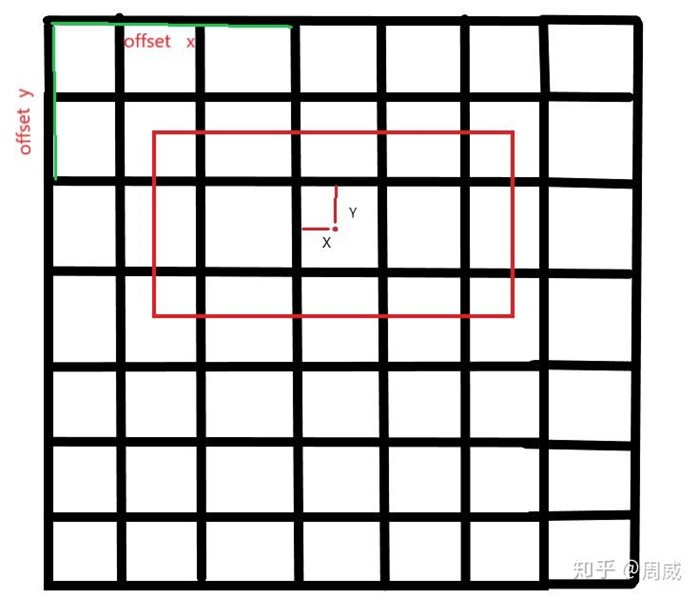
来自 <https://zhuanlan.zhihu.com/p/89143061>
这里注意:
对比V3,在YOLOv3实现代码里,这里是先生成一个416*416的灰色色块(R、G、B的值均为128),然后将resize之后的原图粘贴到灰色块中间
激活函数:
最后一层使用线性激活函数,其他层使用leaky RELU
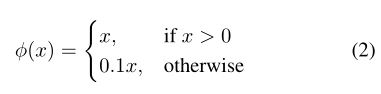
loss:
一开始使用平方和,但是:
- 平等对待位置损失和分类损失
- 大多数网格不包含检测的物体,这些网格的confidence接近于0,导致这类样本比含有物体的样本多,导致模型偏斜
解决方案1:
增加bounding box坐标产生的loss,减少不包含物体的预测结果loss
为两个loss添加权重:

问题2:
平方和将大box和小box的error看做平等的
解决方案2:
预测bounding box的h,w的平方根,而不是直接预测bbox
loss function:
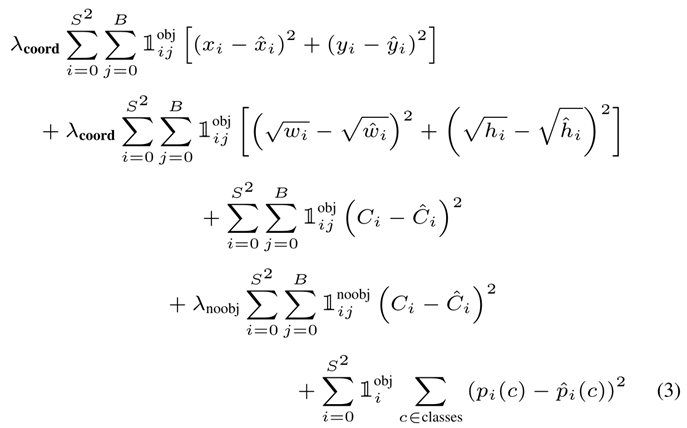
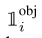
表示物体是否在网格cell_i中出现
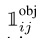
表示第i个网格(cell)中的第j个bbox与预测结果相关联
第三行与第四行,都是预测框的置信度C。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积)。
第五行为物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
训练参数:
train:VOC2007 and VOC2012
135epoch
当在2012上test时,还训练集还包括了VOC2007test
batchsize=64
momentum=0.9
decay=0.0005
lr:

使用了droupout=0.5,在第一个全连接之后
数据增强:
随机缩放、位移、曝光、饱和度
推断
非极大值抑制
局限性
- 每个网格预测两个bbox,且只能有一个分类结果
对于成群出现的小目标,效果不好
- 对于新的/异常的长宽比或配置,效果不好
- 使用了多个下采样,只是用粗粒度特征
- loss平等对待小bbox和大bbox,主要的error来源是错误的位置
总结YOLOv1要点点:
- YOLO: 45 FPS,Fast YOLO: 155 FPS
- 将图像分成S*S的网格,每个网格预测B个bbox,对每个bbox预测其置信度confidence(IOU)
- 每个网格预测C个条件类别概率,C是类别数目,之预测一组C个条件概率,无论B的取值为多少
- 对VOC,S=7,B=2,C=20,网络输出为7*7*30,其中30=20+(xywh+confidence)*B
- 24卷积+2全连接
- 训练和测试阶段的分辨率不同:detection需要细粒度的视觉信息,因此把输入分辨率从224*224提高到448*448
- leaky RELU
- lambda参数对loss进行加权:增加bounding box坐标产生的loss,减少不包含物体的预测结果loss,为两个loss添加权重
- 预测bounding box的h,w的平方根,而不是直接预测bbox,平方和将大box和小box的error看做平等的
- 数据增强和NMS
YOLO v2 (YOLO 9000)
性能:
YOLOv2,VOC2007:
67FPS,76.8mAP,
40FPS,78.6mAP,
YOLO9000:
在训练和检测任务上联合训练
COCO(检测)+ImageNet(分类)
因此,YOLO 9000可以检测那些没有在检测数据集中被标注的物体类别
validation:
ImageNet detection val set:19.7mAP
提出问题:
通常,目标检测数据集的;类别数要小于分类数据集(原因:检测标签标注成本比分类高)
例如:
常见目标检测数据集包括几千~几十万张图片,几十~几百类标签,
而常见的分类数据集有几百万张图片,几万~几十万个类别
如ImageNet:
训练数据包含 1000 个类别和 120 万张图片
说明:ImageNet全部1千多万的数据,但是一般不用,没有用到1500万(对应了2万多类),常用的是ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)比赛用的子数据集,也就是:
训练集:1,281,167张图片+标签
验证集:50,000张图片+标签
测试集:100,000张图片
解决方案:
ImageNet+COCO联合训练YOLO9000
YOLO V2的改进:

batch normalization:
使用BN,可以取消dropout
BN论文:
[7] S. Ioffe and C. Szegedy. Batch normalization: Accelerating
deep network training by reducing internal covariate shift.
arXiv preprint arXiv:1502.03167, 2015. 2, 5
关于BN: https://www.cnblogs.com/guoyaohua/p/8724433.html
High Resolution Classifier:
YOLOv1:训练分辨率是224*224,测试阶段是448*448
YOLOv2:
先在 ImageNet 分类数据集上预训练 Darknet-19,此时模型输入为 224 * 224 ,共训练 160 个 epochs
首先fine-tune分类网络,使用448*448,10个epoch,在ImageNet上
然后fine-tune的得到的网络,在detection上
得到4%mAP提升
Convolutional With Anchor Boxes:
Faster-RCNN手工选取先验框,使用RPN(region proposal network)预测先验框的偏置和置信度confidence
移除YOLO的全连接,使用anchor box,预测bbox
- 首先:移除一个池化层,使卷积输出分辨率提高
-
然后,缩小输入,从448*448缩小到416
- 目的:这样feature map产生奇数个位置,使featuremap的位置是奇数,因为物体通常出现在中心
- 对416的解释:
YOLO的卷积层将图像缩小为32倍,因此通过使用416的输入图像,我们得到了13×13的输出特征映射。使用448,将得到14*14的feature map
- YOLO的卷积层降采样32倍,从416降至13*13
-
为每个anchor box预测类别:
- GT和box之间的IOU
- 给定box含有物体的条件下,物体类别的条件概率
- 得到acc的小幅提升,YOLOv1每张图像预测98个box(7*7*2),但是使用anchor box之后,这个值达到上千个
- mAP下降,但是recall上升
Dimension Clusters维度聚类:
使用anchor box的第一个问题:
box的维度是手工选取的
- 使用k-means,聚类训练集的bbox,寻找先验
- 如果使用标准k-means,使用欧氏距离,那么大的box的error比小box更大
- 因此聚类使用的metric是:

-
表一对比了性能:
- Sum of Squared Errors (SSE)
- IOU
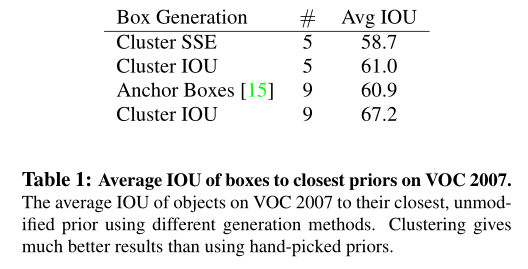
- 聚类过程:
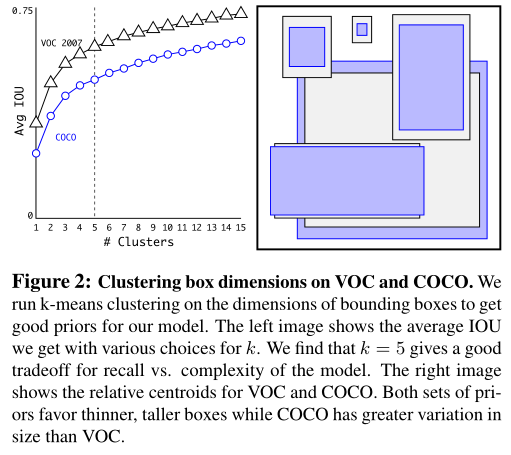
这里不考虑框的位置信息,只考虑长宽,所以两个框计算iou的过程,可以理解为框的左下角重合在一起然后计算iou。
来自 <https://zhuanlan.zhihu.com/p/43632519>
Direct location prediction
使用anchor box的第二个问题:
模型的不稳定性(尤其在早期iter)
不稳定性大多来自于预测box的(x, y)位置
在RPN(region proposal network)中,网络预测的是t_x和t_y的值:
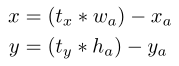
预测tx=1就会把box向右移动Anchor Box的宽度,预测tx=-1就会把Box向左移动相同的距离。
这个公式没有任何限制,无论在什么位置进行预测,任何Anchor Boxes可以在图像中任意一点。模型随机初始化之后将需要很长一段时间才能稳定预测敏感的物体偏移。因此作者没有采用这种方法,而是预测相对于Grid Cell的坐标位置,同时把Ground Truth限制在0到1之间(利用Logistic激活函数约束网络的预测值来达到此限制)。
YOLO:
每个网格(cell)预测5个bbox
每个bbox预测5组坐标:
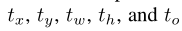
网格cell距离图像左上角的offset:
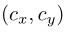
bbox的先验宽高:
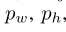
则,预测结果为:
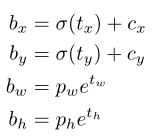
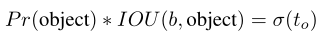

由于σ(sigmoid)函数的处理,bbox的中心坐标会约束在当前cell内部防止偏移
约束了边界框的位置预测值,参数就更容易学习。
上述设置使得参数更易于学习,网络更稳定
Fine-Grained Features
YOLOv2在13*13的特征图上预测检测结果
根据YOLOv2代码实现,作者先采用64个1*1卷积核进行对高分辨率特征图卷积,然后再进行passthrough处理,这样26*26*512的特征图得到13*13*256的特征图。

其中,passthrough layer拆分方式如下图所示:
Multi-Scale Training
每隔10个batch,网络随机选择一个新的图像尺寸(image dimension size)
由于网络降采样的因子是32,因此image size从如下32的倍数中选择:{320,352, ...,608}
共计十个数

Faster:
YOLO v1使用了基于Googlenet改进的自定义网络,比VGG更快
YOLO v2提出Darknet-19
类似VGG:
大多是3*3卷积
池化之后channel数目翻倍
NIN:network in network,根据NIN的工作,使用全局平均池化,1*1卷积核
batch norm
19卷积层、5 maxpooling
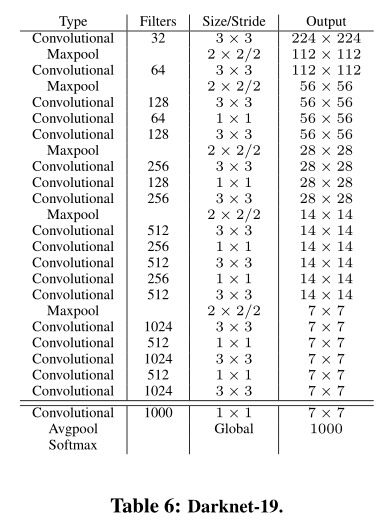
上边的darknet-19用于训练分类器
5.58 billion operations
训练分类器:
在ImageNet1000类上训练160epoch,使用darknet
训练中使用标准数据增强:
随机裁切
旋转
色度饱和度曝光度飘移
初始训练:224*224,fine tune:448*448
训练检测器:
对于上述网络(darknet-19),移除最后卷积层
添加3个3*3卷积(1024个滤波器),每个后边接1*1卷积
对于VOC:
每张图5个box+5组坐标each box
每个box20类
所以: 5*(20+5)=125
对比YOLO1的final output:
7*7*((xywh+confidence)*B+20)
7*7*(5*2+20)=7*7*30(=1,470)
YOLO2的输出是13*13*5*(4+1+20),现在YOLO9000的输出是13*13*3*(4+1+9418)。假设输入是416*416*3。
YOLO2网络中第0-22层是Darknet-19网络,后面第23层开始,是添加的检测网络。

route层的作用是进行层的合并
route层是合并的意思,比如28层的route把27层和24层合并到一起输出到下一层,第27层的输出是13 13 256,24层输出是13 13 1024,所以在第三个维度上做拼接就是28层的输出了,同样也是29层的输入:13 13 1280。同理,第24层route只有16,那么就不做合并了,直接把16层的输出拿过来作为24层输出:26 26 512。
来自 <https://flashgene.com/archives/5928.html>
reorg就是前边的passthrough
YOLO2 的loss function(来自网络):

根据YOLO3论文,这里的loss是平方误差之和。
t_hat是坐标预测值对应的GT,预测值是t,则梯度计算来自t_hat-t
这个GT的值可以通过下式的反变换来求解:
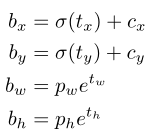
tx = Gx - Cx
ty = Gy - Cy
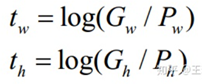
关于坐标映射关系的介绍: https://zhuanlan.zhihu.com/p/49995236
Stronger
本文提供了一种联合训练分类+检测数据的方法
网络输入一张检测任务标注的图像,则基于YOLOv2的loss function进行传播
网络输入一张分类图像,则仅在分类部分进行传播
这带来的问题:
检测任务的标签是一般物体,例如猫、狗
而分类任务的标签则涵盖广泛,例如贝灵顿狗
需要一种一致的方法来对两种label进行融合
使用softmax的前提是类别之间是排他的(相互独立、互不包含的)
因此,本文使用多标签模型(构建反应类别之间关系的树)
Hierarchical classification
ImageNet的label提取自wordnet

Joint classification and detection
使用COCO检测数据集+full ImageNet中的Top9000类
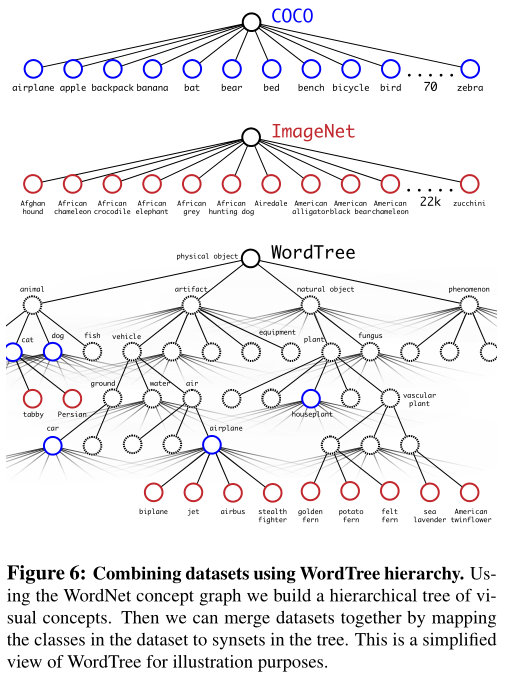
如何使用WordTree进行分类:
在树的每个节点预测给定那个同义词集、每个下位词的条件概率
例如,对于terrier这个节点,预测其所有下位词的条件概率:

从根节点到某节点的路径上所有条件概率之乘积,就是绝对概率
例如:

对于分类问题,假设图像包含一个物体:
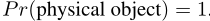
本文将ImageNet1000类扩展到1369
例如,一个节点label为"Norfolk terrier",那么,这个节点还具有标签dog、mammal(一直到树的根节点)
本模型预测一个1396维向量,其中,同一个概念的下位词之间进行softmax
在训练COCO+ImageNet数据集时,使用3个prior ,而不是5个
YOLO2的输出是13*13*5*(4+1+20),现在YOLO9000的输出是13*13*3*(4+1+9418)。假设输入是416*416*3。
分类loss:仅反向传播该点及其上边的节点的label
仅反向传播分类loss:
找到预测某一类别的最高概率的bbox,然后在tree上计算loss
假设预测框与GT重叠至少0.3IOU,基于这个假设进行反向传播
YOLOv3
回顾YOLO 9000:
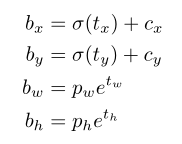
YOLO3 使用逻辑回归为每个bbox预测物体得分
faster R-CNN:
[17] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: To-
wards real-time object detection with region proposal net-
works. arXiv preprint arXiv:1506.01497, 2015. 2
与faster r-cnn不同的是,本文为每个GT分配一个bbox prior
如果一个bbox prior没有与object GT关联,则不计入坐标loss和classloss,只计objectness
对此训练策略的理解:
- 预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
- 正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出 t_x, t_y, t_w, t_h);类别标签对应类别为1,其余为0;置信度标签为1。
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
- 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
来自 <https://zhuanlan.zhihu.com/p/76802514>
类别预测:
每个bbox包含的class,使用多标签分类来预测
不使用softmax,而是使用独立的逻辑回归分类器
训练阶段:BCE loss(binary cross entropy)
原因:
使用open image dataset,包含有重叠关系的label,例如女人和人物
最后一层预测输出的维度:(COCO)
N ×N ×[3∗(4 + 1 + 80)]
4:bbox offset
1:是否有物体
80:类别
然后:从两层之前提取feature map,上采样2倍
再从前边的卷积层提取feature map,与上采样的特征concat拼接
优势:
从上采样的feature中提取语义信息,从早期的特征图中提取细粒度信息
最后,再一次应用上述过程
使用k-means聚类决定bbox先验:
对于COCO,先验是
(10×13),(16×30),(33×23),(30×61),(62×45),(59×
119),(116 × 90),(156 × 198),(373 × 326).
YOLO2使用Darknet-19,YOLOv3添加了一些shortcut connection
Darknet-53:
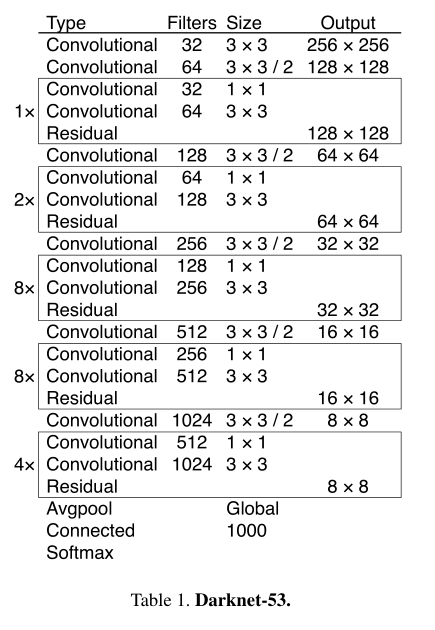
YOLOv3网络框架:
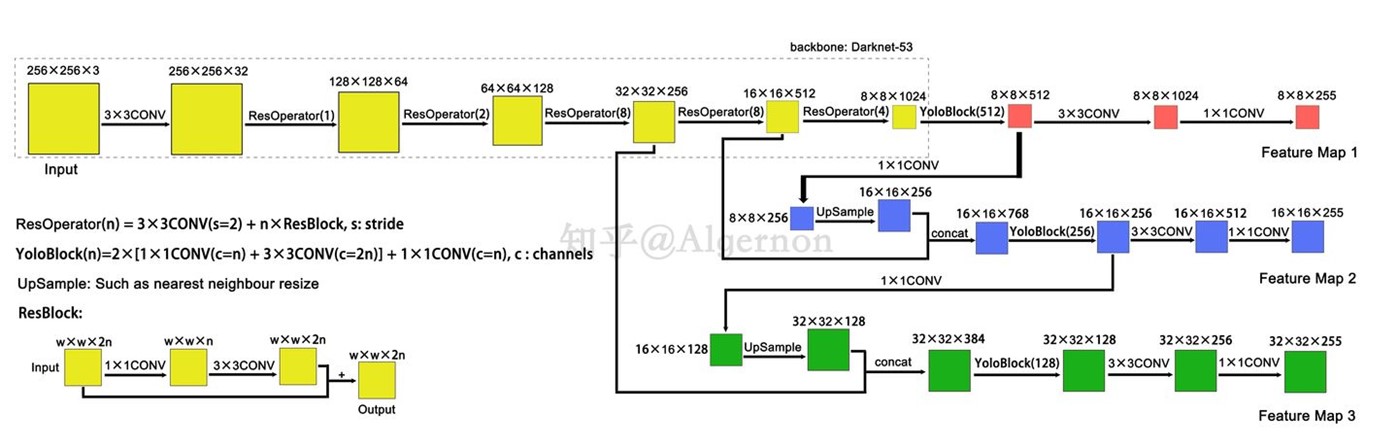
训练:
no hard negative mining
使用多尺度训练、数据增强、BN
loss:
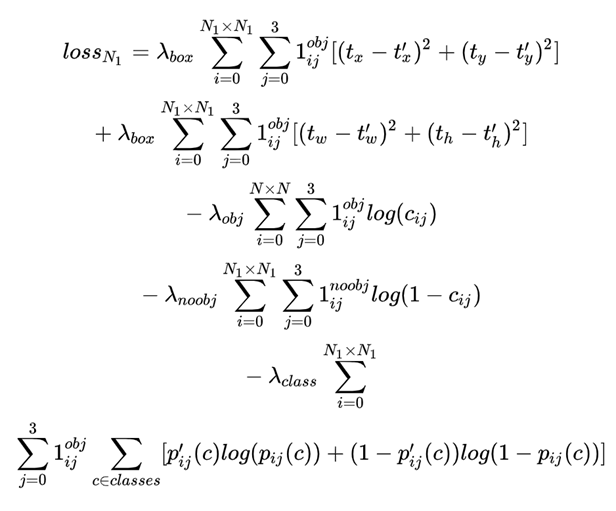

作者尝试但没有起作用的方法:
Anchor box x, y offset predictions.
Linear x, y predictions instead of logistic.
Focal loss
Dual IOU thresholds and truth assignment.
YOLO v4
We use new features: WRC, CSP,
CmBN, SAT, Mish activation, Mosaic data augmentation,
CmBN, DropBlock regularization, and CIoU loss,
一个一般的检测器通常分为两部分:
- backbone,用ImageNet预训练
- head,用于预测类别和bbox
- neck,近年来出现的检测器在backbone和head中间插入一些层,用于收集来自不同stage的feature map,neck一般包括bottom-up path和top-down path,使用neck的网络包括FPN、PAN、BiFPN、NAS-FPN


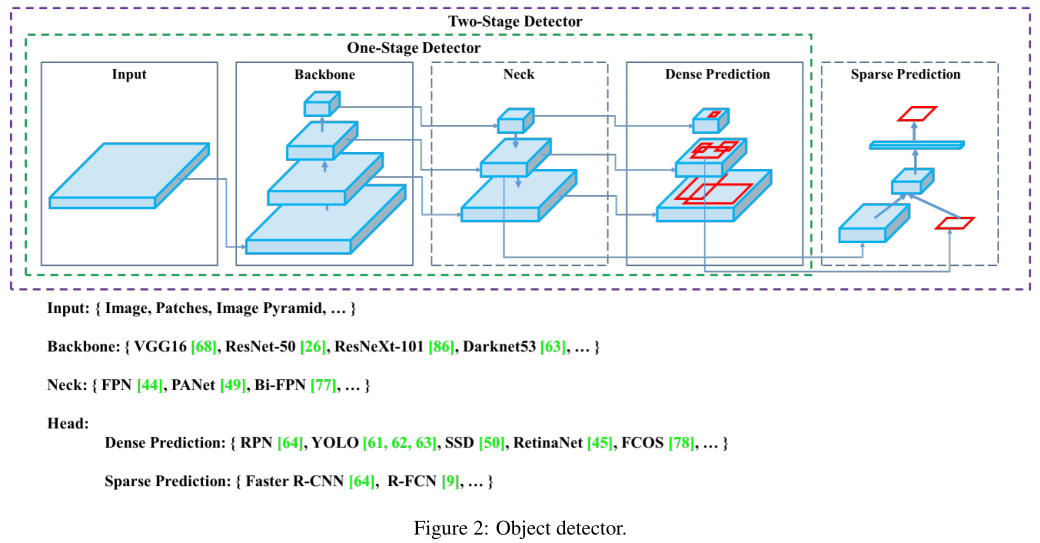
Bag of freebies
只增加训练时间,不增加推理时间的改进,称为freebies
常用:数据增强
-
光度畸变(Photometric Distortions)
- 随机亮度(Random Brightness)
- 随机对比度,色调和饱和度(Random Contrast, Hue, Saturation)
- 随机光噪声(RandomLightingNoise)
-
几何畸变(Geometric Distortions)
- 随机尺寸(Random Scaling)
- 随机裁剪(Random Cropping)
- 随机翻转(Random Flipping)
- 随机旋转(Random rotating)
上述方法都是逐像素的调整,保留了原始像素信息
另一些工作模拟了物体遮挡( object occlusion )
例如:
- random erase [100] and CutOut [11]:随机选取矩形区域,填充随机值或者0
- hide-and-seek [69] and grid mask [6]:随机或者平均地选取多个矩形区域,填充0
- DropOut [71], DropConnect [80], and DropBlock [16]:强类似的方法应用在feature map上
- MixUp [92] 使用两个像素乘以不同的比例系数并叠加,然后利用这些叠加比例调整标签
- CutMix [91],将裁切后的图像覆盖到另一图像的矩形区域内,根据混合区域大小调整标签label
- style transfer GAN [15]也可用于数据增强,能够减少CNN学习到的纹理偏差
另一些方法用于解决数据集语义分部的偏差问题(semantic distribution bias)
two-stage 检测器使用的方法:
- hard negative example mining [72]
- online hard example mining [67]
one-stage检测器使用的方法:
- focal loss [45]
- label smoothing [73]:将硬标签转换成软标签
- knowledge distillation [33]:可以获得更好的软标签,label refine network
bbox回归目标函数:
传统方案:MSE,直接回归xywh,或者两点的坐标
anchor-based方法:估计xywh或者左上右下两点的偏置量offset
缺陷:
直接预测坐标值,相当于把这些点看成是相互独立的变量,没有考虑物体本身
IOU loss [90]
GIOU loss [65]:除了覆盖区域之外,还包括了物体形状和方向
DIOU [99]:考虑物体中心距离
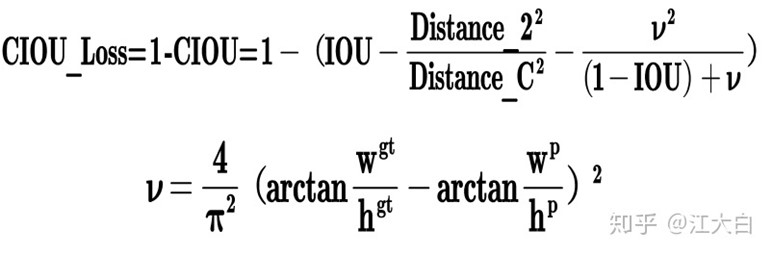
CIOU loss [99]:考虑物体中心的距离外,还同时考虑重叠区域,中心点距离,长宽比
CIOU收敛速度和acc更好
Bag of specials
少量增加推理开销,显著增加检测准确率的方法,称 Bag of specials
增强感受野的方法(模块):
SPP [25], ASPP [5], and RFB [47].
SPP来源于SPM[39],SPM将feature map分成d*d的block,形成空间金字塔
然后提取词袋特征
SPP将SPM引入CNN,使用最大池化代替词袋
SPP的出输出是一维向量,因此不能用于全卷积网络
因此在YOLO3中,作者改进了SPP,使用k*k卷积核拼接max-pooling输出结果(k={1, 5, 9, 13}),stride=1
ASPP[5] 和改进的SPP之间的区别是:
- k*k 卷积核,max-pooling,stride=1
- 使用几个3*3卷积核,膨胀系数k,膨胀卷积stride=1
RFB模块:
使用几个dilated卷积(k*k卷积核),膨胀系数k,stride=1
attention模块:
- channel-wise attention,例如Squeeze-and-Excitation(SE)[29]
- point-wise attention,例如Spatial Attention Module(SAM)[85]
特征融合:
早期实践是skip connection [51] or hyper-column [22]
流行的方法如FPN等多尺度方法:
SFAM [98]:使用SE模块对多尺度feature map进行逐通道的加权拼接
ASFF [48]:使用softmax进行逐点加权,然后将不同scale的feature map相加
BiFPN [77]:多输入加权残差连接,进行逐尺度(scale-wise)的加权
激活函数:
LReLU [54], PReLU [24], ReLU6 [28], Scaled Exponential
Linear Unit (SELU) [35], Swish [59], hard-Swish [27], and
Mish [55], etc.
后处理:
常用方法:NMS
但是NMS没有考虑上下文信息,所以添加R-CNN中的分类置信度——greedy NMS
还有soft NMS、DIoU NMS
方法论
基本目标:神经网络的快速操作
GPU - 使用几组(1-8)卷积层:CSPResNeXt50 / CSPDarknet53
VPU - 分组卷积,避免使用SE blocks :EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3
架构选择:
ILSVC2012(ImageNet)上的物体分类:CSPResNext50比CSPDarknet53好
COCO上的目标检测:相反
针对分类问题优化的模型并不总是适用于检测问题
检测器与分类器的区别:
- 输入网络分辨率更高(用于检测小物体)
- 更多的层数(更高的感受野来覆盖输入网络的增大)
- 更多的参数(模型检测多种物体、多种大小的能力更强)

不同感受野大小的影响:
- 感受野达到物体大小:能够看到整个物体
- 感受野达到网络大小:允许网络看到物体的上下文
- 感受野超过网络大小:增加图像点与最终激活之之间的连接数
本文作者在CSPDarknet上加了SPP block
使用PANet进行不同backbone level参数聚合以替代YOLOv3中的FPN
YOLOv4=
CSPDarknet53 backbone
+ SPP addi-tional module
+PANet path-aggregation neck
+YOLOv3 (anchor based) head
没有使用 Cross-GPU Batch Normalization (CGBN or SyncBN)或者昂贵的特殊设备
GTX 1080Ti or RTX 2080Ti.
BoF和BoS的选择:
通常情况下,CNN用于提升目标检测训练的方法包括:

使用DropBlock(正则化)
其他改进:
- 新的数据增强:Mosaic,以及Self-Adversarial Training (SA T)
- 遗传算法,找到最优超参
- 改进了现有方法: modified SAM, modified PAN, and Cross mini-Batch Normalization (CmBN)

SAT:第一个stage,网络修改原始图像而不是修改weights(相当于网络对自身做了一个对抗攻击),生成图像中没有目标,第二阶段,正常训练
CmBN:
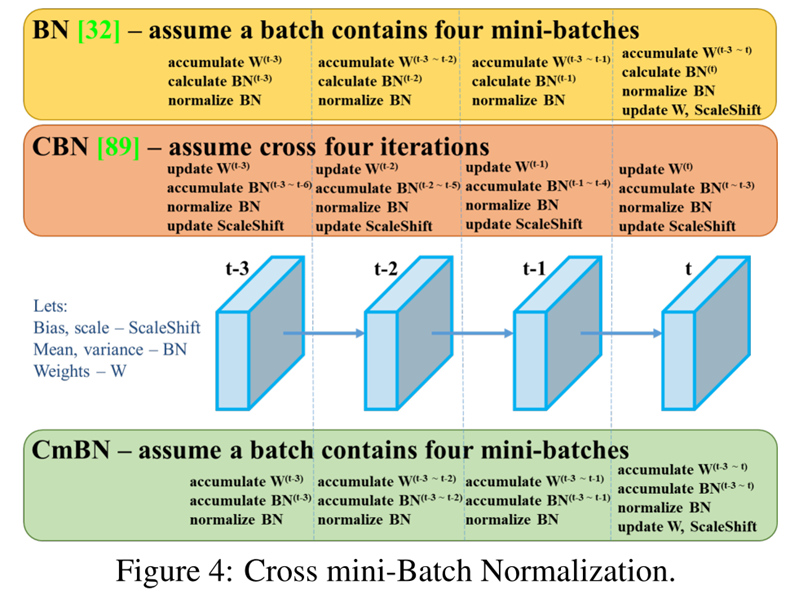
修改:SAM将spatial-wise attention 修改成point-wise
PAN的shortcut修改成拼接(concatenation)
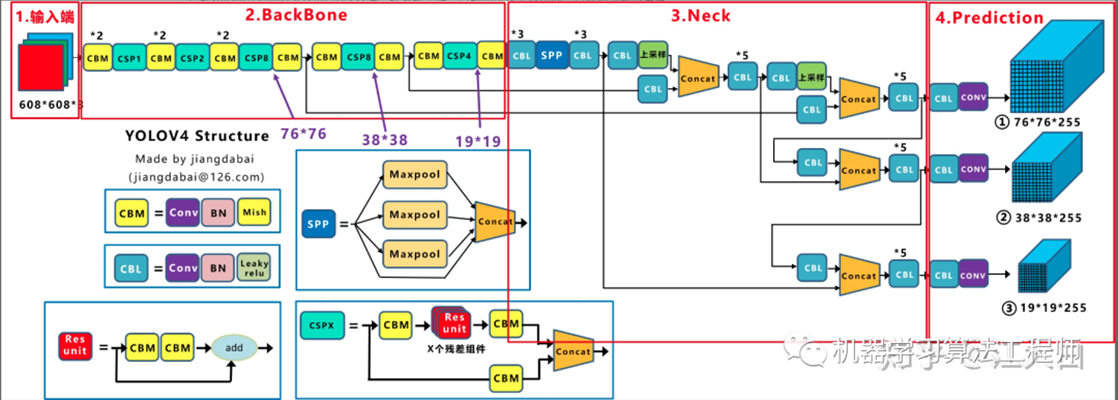
YOLO v4:

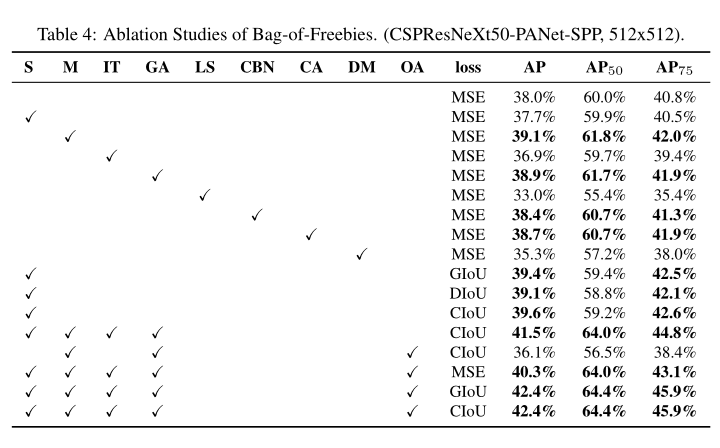
evaluation



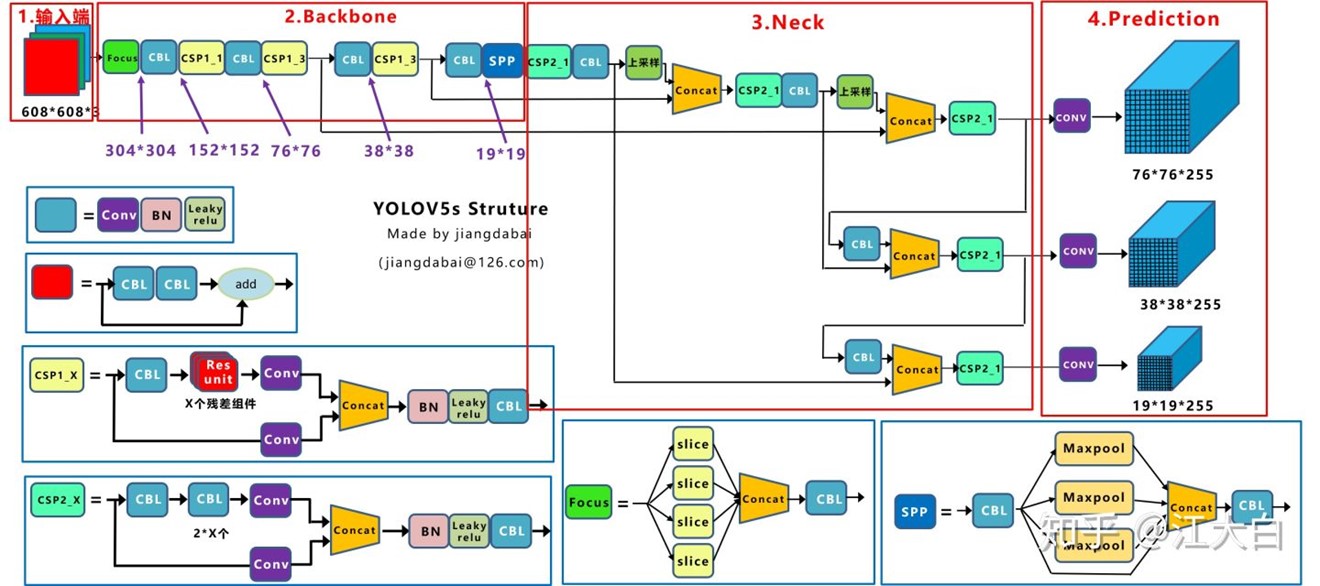
YOLO v5
没有paper
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
Yolov5s:
自适应锚框计算:
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中(可关闭),每次训练时,自适应的计算不同训练集中的最佳锚框值。
自适应图片缩放:
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

第三步:计算黑边填充数值
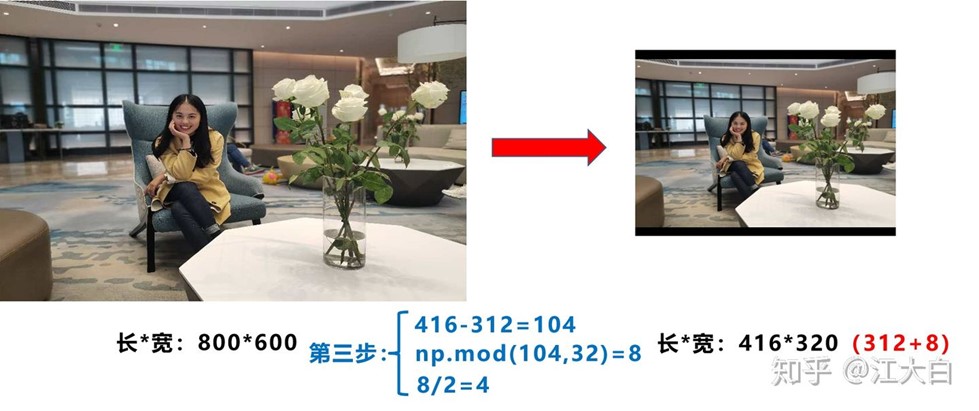
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
Focus结构
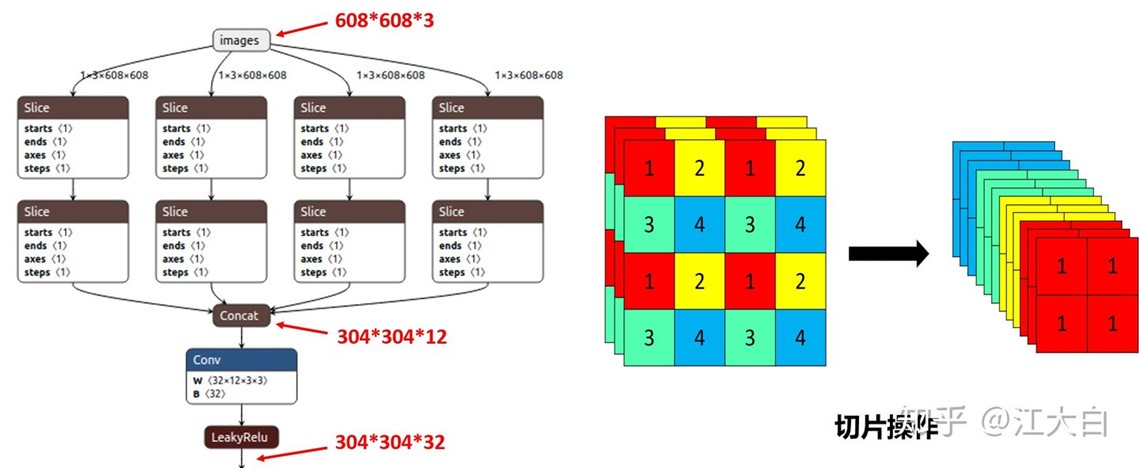
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
YOLOv4中的CSP结构:
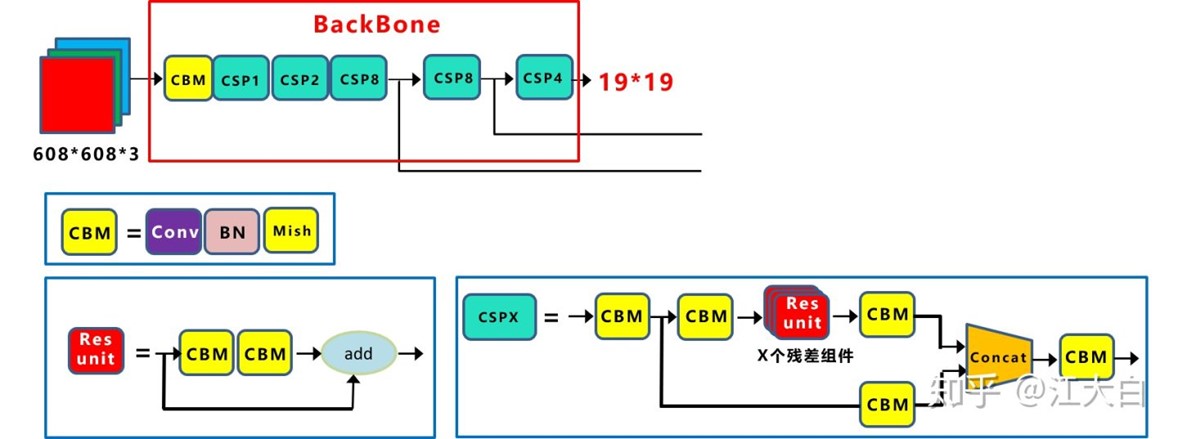
Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
Yolov5中采用GIOU_Loss做Bounding box的损失函数。
2021年5月12日
于北京

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号