
课程式学习(Curriculum Learning)
机器学习之课程式学习(Curriculum Learning)
在2009年的国际顶级机器学习会议ICML上,以机器学习领军人物Bengio为首的研究团队首次提出了课程式学习(Curriculum Learning)的概念,引起了机器学习领域的极大轰动。其后数十年间,众多关于课程式学习、自步学习(Self-paced Learning)的研究工作被相继提出。
在本次论文分享中,笔者将带领读者一起来细细品味Curriculum Learning的精髓和魅力。

* Paper Download:http://nxw.so/3WMWv
1、Overview:
人类和动物的学习过程一般都遵循着由易到难的顺序,而Curriculum Learning正是借鉴了这种学习思想。相较于不加区分的机器学习一般范式,该论文模仿人类学习的过程,首次提出了Curriculum Learning,主张让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。
论文给出了Curriculum Learning的数学化描述,并通过多个toy experiments说明了Curriculum Learning对于机器学习有如下两个层面的帮助:
- 可以加速机器学习模型的训练。在达到相同的模型性能条件下,Curriculum Learning可以加速训练,减少训练迭代步数;
- 使模型获得更好的泛化性能,即能让模型训练到更好的局部最优值状态。
2、Key Insight:
Curriculum Learning会根据样本的难易程度,给不同难度的训练样本分配不同的权重。初始阶段,给简单样本的权重最高,随着训练过程的持续,较难样本的权重将会逐渐被调高。这样一个对样本进行权重动态分配的过程被论文称之为课程(Curriculum),课程初始阶段简易样本居多,课程末尾阶段样本难度增加。
需要注意的是,这种对Curriculum的定义是开放式的,针对不同的实际问题可以设置不同的样本难易程度评价标准。
3、Toy Experiments:
论文构建了如下几个toy experiments来为了验证Curriculum Learning思想应用于机器学习问题的有效性:
* Experiment 1:SVM分类实验
基于两个二维的高斯分布产生二类数据,并算出贝叶斯分类器的决策面。将严格处于决策面两侧的视为简单样本,其它为噪声样本,即复杂样本。
仅用简单样本训练得到的SVM分类器所实现的分类错误率为16.3%,而用所有样本训练得到的SVM分类器错误率则有17.3%。这个实验没有涉及curriculum learning的方法步骤,只是简单地为了让读者直观地理解简单样本是很有用的。
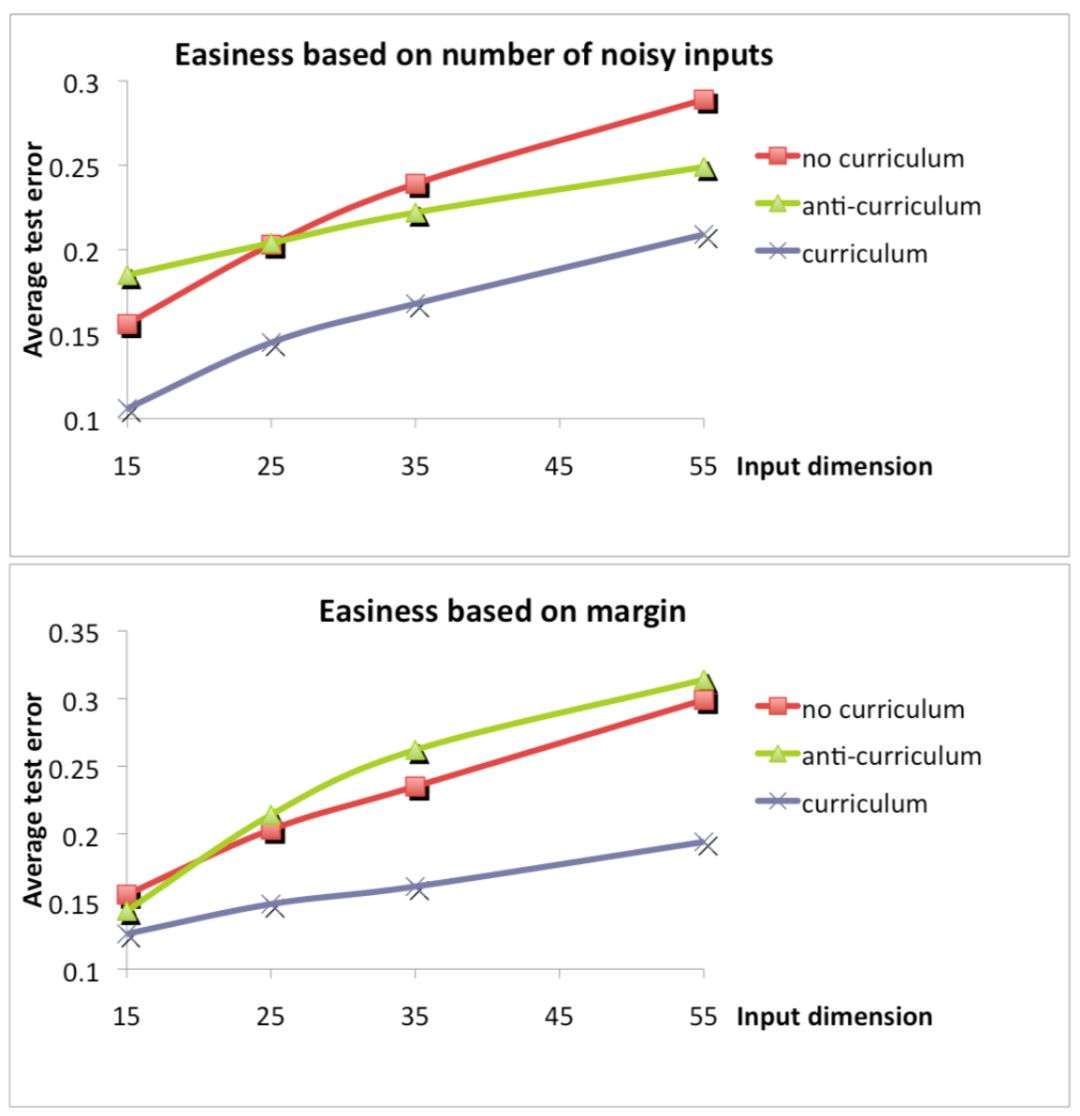
* Experiment 2:感知器实验在该实验中,论文定义了两种样本的难易标准:
输入x向量有一部分元素是干扰量,干扰越少,即干扰位数为0的数目越多,样本越简单;
ywx的margin大小,margin越大说明x越容易区分,即样本越简单。Curriculum Learning策略就是按照样本简单程度由简单到复杂依次进行训练。多次实验表明这种引入Curriculum机制的训练模型可以达到更好的泛化能力,即测试错误率越低,在有限的迭代步数下也能达到更好的性能。
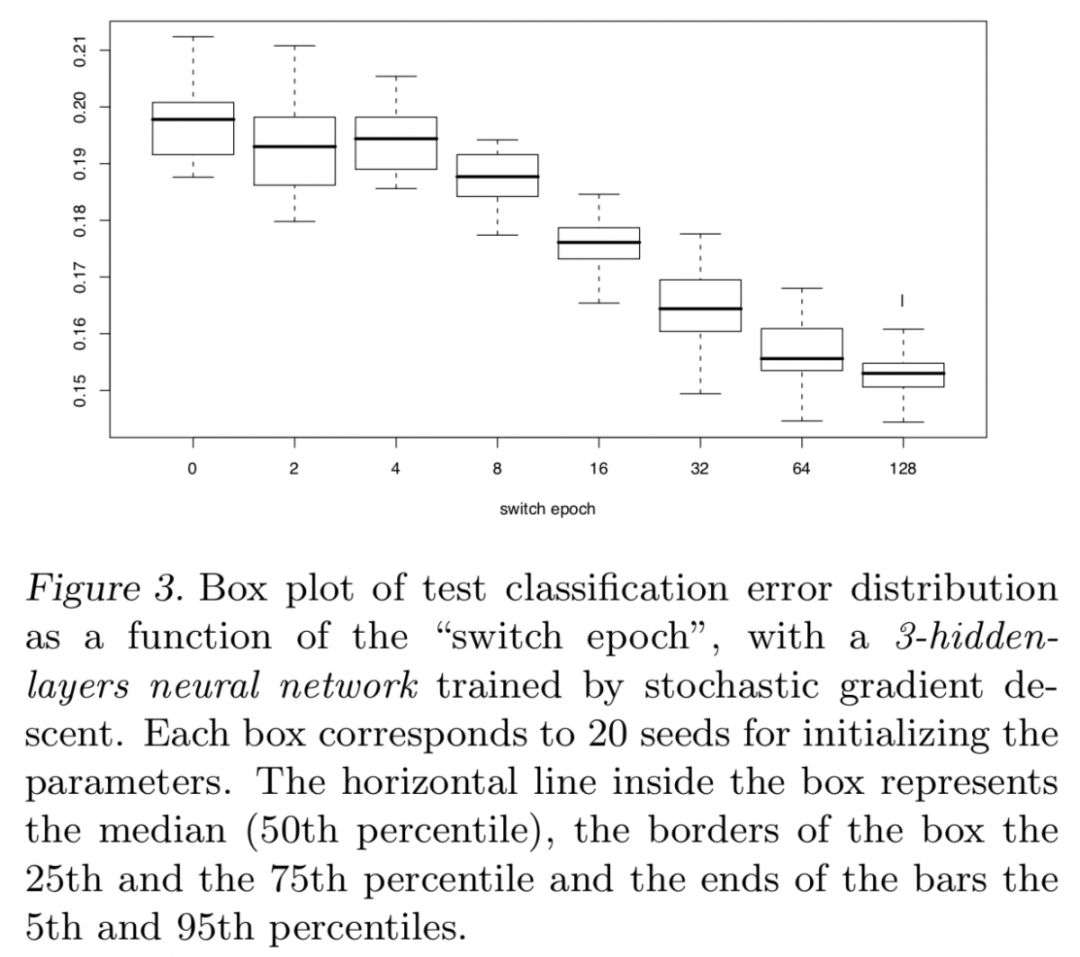
* Experiment 3:神经网络进行形状识别实验
该实验涉及到两个数据集:
- BasicShapes包含等边三角形、正方形、圆形三种类别
- GeomShapes包含三角形、矩阵、椭圆三种类别
显然,第一个数据集是第二种数据集的特例,可以理解为更“简单”的样本。Curriculum策略是先用第一个数据集对神经网络进行训练,训练到一定的switch epoch后再用第二个数据集进行训练。No curriculum策略则是直接只用第二个数据集进行训练。通过比较两种训练机制下得到的模型的泛化错误率可以发现:先用简单的知识训练对模型的提高会有帮助,并且简单的知识学得越好(即switch epoch越大),则对模型最终的泛化性能越有利。但是该实验也说了自己的问题,可以认为是curriculum learning看到了更多的样本所导致的效果。但是作者也声明说,如果用两个数据集一起训练模型,达到的性能也并没有curriculum得到的好(相当于switch epoch=16的效果)。

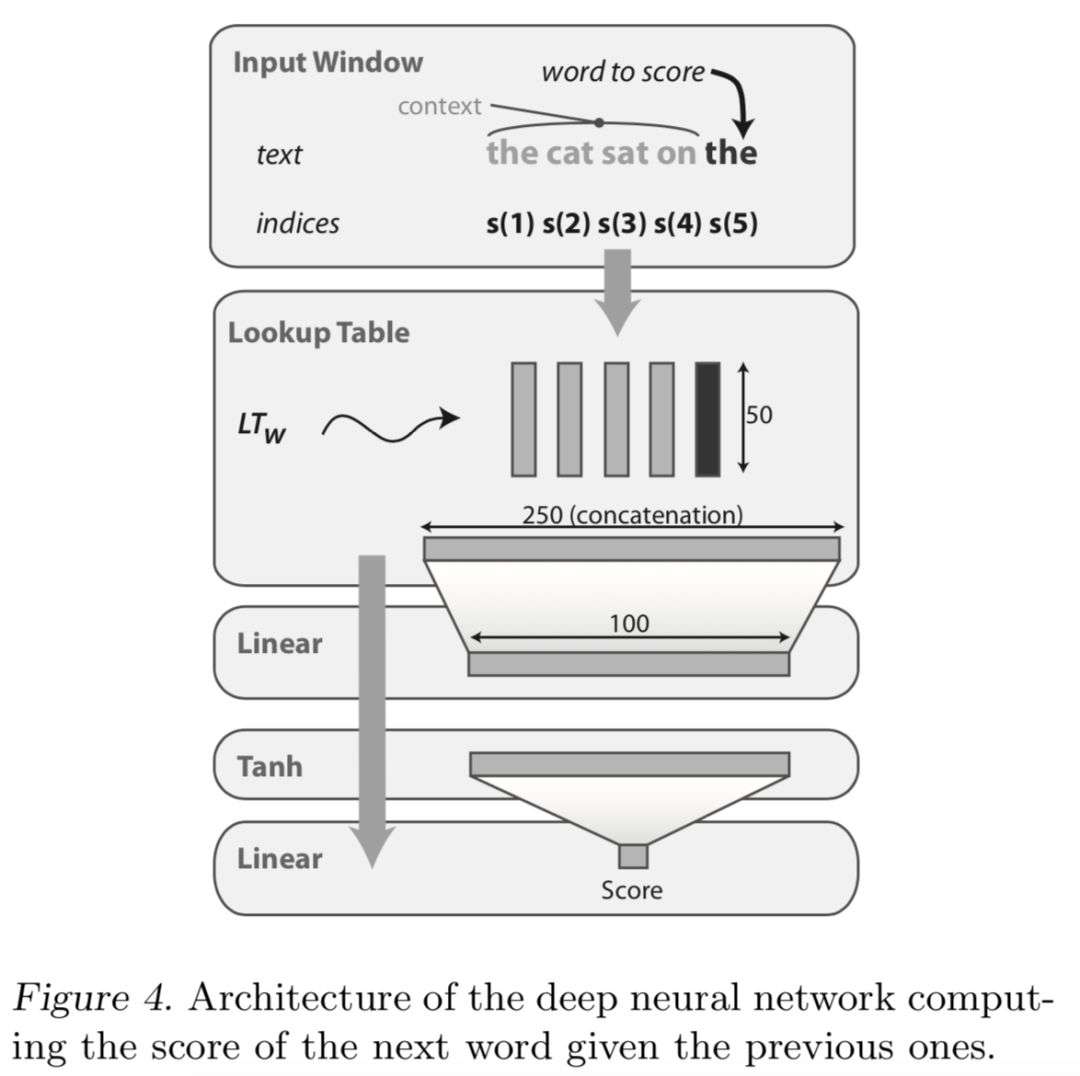
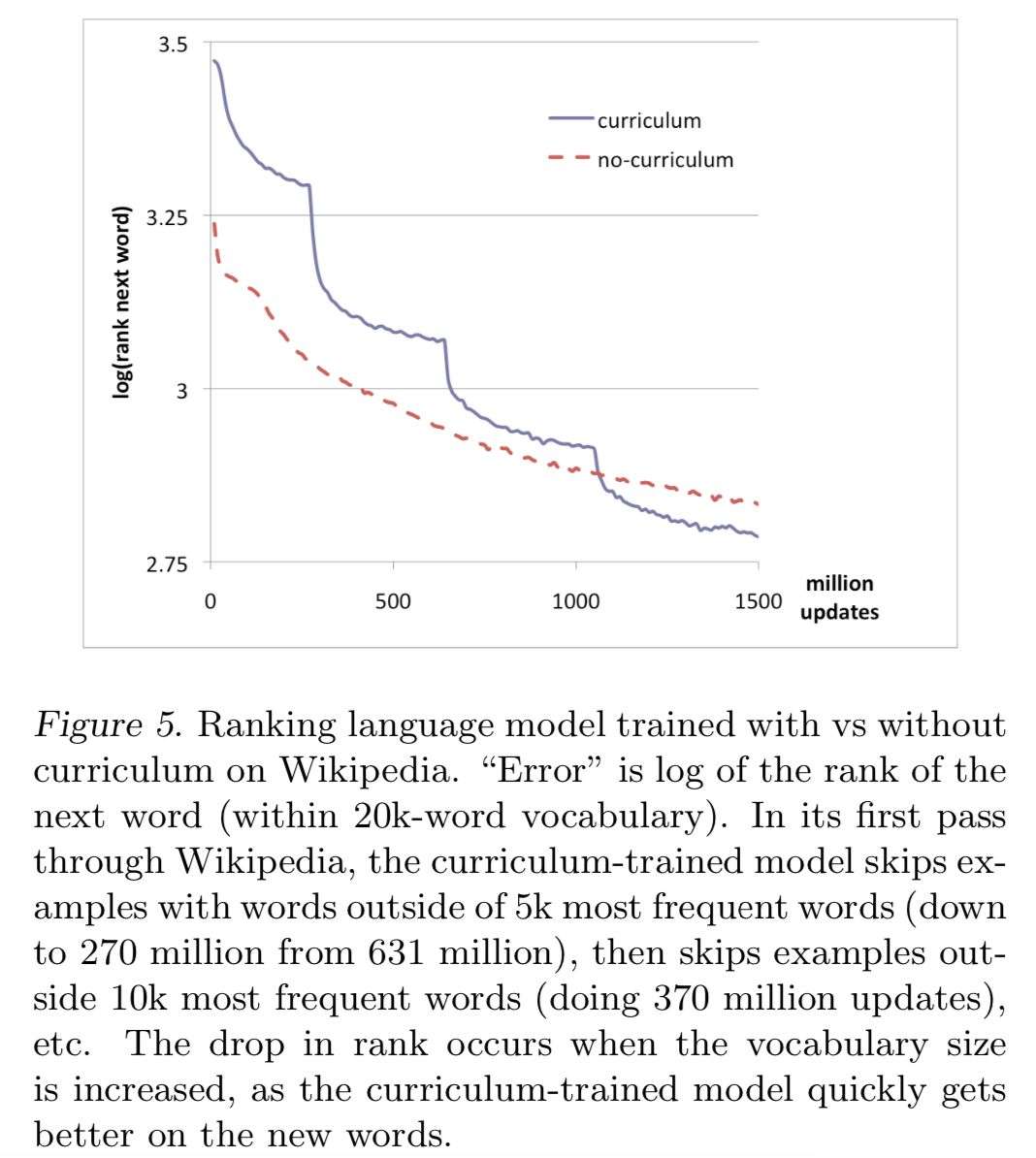
* Experiment 4:language modeling实验即给定一句话,除了最后一个单词没给定之外,需要模型能够填出最后一个词。实验利用维基百科的数据,训练集从631百万的句子中产生,词库大小为20000。Curriculum策略是:先从词库中选择5000个最常见的words,先只用含有这些word的训练样本进行模型的训练,即将这些样本作为简单样本。而后再扩展到10000,15000,20000,这样就实现了先简单后困难的学习过程。最后这种Curriculum Learning的策略在测试集上的错误率在学习过程的后阶段会超过不采用Curriculum策略的学习方法,说明Curriculum能让模型更快地达到更好的泛化能力。
4、Remarks:
这篇论文的意义在于首次提出了Curriculum Learning的研究思想,并用实验说明了这种“先易后难”的训练策略会使得机器学习更快地达到更好的模型泛化性能。当然,对于“简单性”这样一个标准的指定,会因为任务的不同而不同,它是一个task-specific的问题。另外,Curriculum Learning之所以有效,笔者认为可以从如下2个方面来解释:
- 该策略使得模型在训练初期能够花更少的时间在复杂的训练样本上;
- 该策略可以引导模型的训练朝更好的局部最优而进行,并依次实现更好的泛化效果。总之,如何寻找更好的Curriculum将会是该方向未来的研究方向,而Curriculum Learning也一直会是机器学习领域的热点问题。
想要更快速、更精准的向大佬靠齐?获得更多科研知识?
请持续关注爱科研 “科研笔记” ,带给你更多、更有趣的paper分析、科研经验分享,让我们一起读paper、写paper、发paper吧~
那些年被发paper支配的恐惧,终于有尽头了!CS方向科研项目推荐,详情咨询:
线上强化科研 | 全美CS专排第一,使用机器学习的方法构造脑机界面,开始报名啦!线上科研 | 加州大学伯克利分校,深度学习与计算机视觉项目实战!开启报名通道!Stanford计算机视觉课题——利用深度学习探测房间整洁度!线上科研 | MIT自然语言处理专题,自选课题,春季班招募中!线上科研 | 探索Google猜画小歌背后的深度学习奥秘,报名开启!本文内容由Researchera与文章作者联合整理发出,转载需注明出处!
原文链接:https://zhuanlan.zhihu.com/p/114825029

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号