
Nesterov Accelerated Gradient (NAG)优化算法详解
比Momentum更快:揭开NAG的真面目
文章的内容包括了Momentum、Nesterov Accelerated Gradient、AdaGrad、AdaDelta和Adam,在这么多个优化算法里面,一个妖艳的贱货(划去)成功地引起了我的注意——Nesterov Accelerated Gradient,简称NAG。原因不仅仅是它名字比别人长,而且还带了个逼格很高、一听就像是个数学家的人名,还因为,它仅仅是在Momentum算法的基础上做了一点微小的工作,形式上发生了一点看似无关痛痒的改变,却能够显著地提高优化效果。为此我折腾了一个晚上,终于扒开了它神秘的面纱……(主要是我推导公式太慢了……)
话不多说,进入正题,首先简要介绍一下Momentum和NAG,但是本文无耻地假设你已经懂了Momentum算法,如果不懂的话,强烈推荐这篇专栏:《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》,本文的实验代码也是在这篇专栏的基础上改的。
Momentum改进自SGD算法,让每一次的参数更新方向不仅仅取决于当前位置的梯度,还受到上一次参数更新方向的影响:
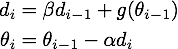
公式1,Momentum的数学形式
其中,和
分别是这一次和上一次的更新方向,
表示目标函数在
处的梯度,超参数
是对上一次更新方向的衰减权重,所以一般是0到1之间,
是学习率。总的来说,在一次迭代中总的参数更新量包含两个部分,第一个是由上次的更新量得到的
,第二个则是由本次梯度得到的
。
所以Momentum的想法很简单,就是多更新一部分上一次迭代的更新量,来平滑这一次迭代的梯度。从物理的角度上解释,就像是一个小球滚落的时候会受到自身历史动量的影响,所以才叫动量(Momentum)算法。这样做直接的效果就是使得梯度下降的的时候转弯掉头的幅度不那么大了,于是就能够更加平稳、快速地冲向局部最小点:
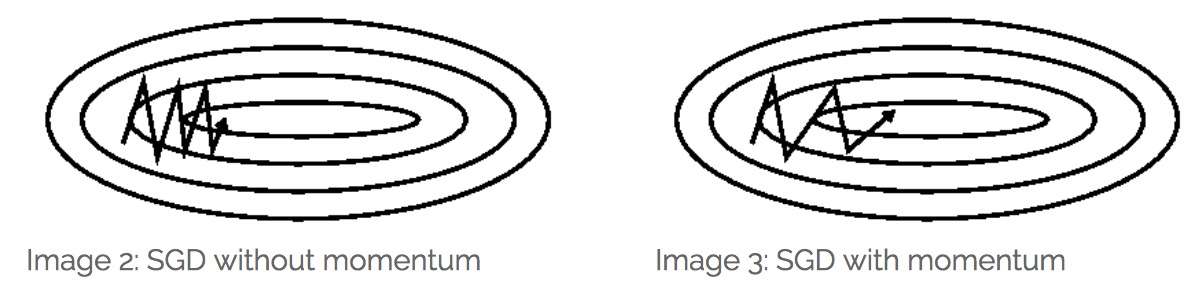
图片引自《An overview of gradient descent optimization algorithms》
然后NAG就对Momentum说:“既然我都知道我这一次一定会走的量,那么我何必还用现在这个位置的梯度呢?我直接先走到
之后的地方,然后再根据那里的梯度再前进一下,岂不美哉?”所以就有了下面的公式:
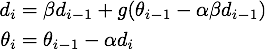
公式2,NAG的原始形式
跟上面Momentum公式的唯一区别在于,梯度不是根据当前参数位置,而是根据先走了本来计划要走的一步后,达到的参数位置
计算出来的。
对于这个改动,很多文章给出的解释是,能够让算法提前看到前方的地形梯度,如果前面的梯度比当前位置的梯度大,那我就可以把步子迈得比原来大一些,如果前面的梯度比现在的梯度小,那我就可以把步子迈得小一些。这个大一些、小一些,都是相对于原来不看前方梯度、只看当前位置梯度的情况来说的。
但是我个人对这个解释不甚满意。你说你可以提前看到,但是我下次到了那里之后不也照样看到了吗?最多比你落后一次迭代的时间,真的会造成非常大的差别?可是实验结果就是表明,NAG收敛的速度比Momentum要快:
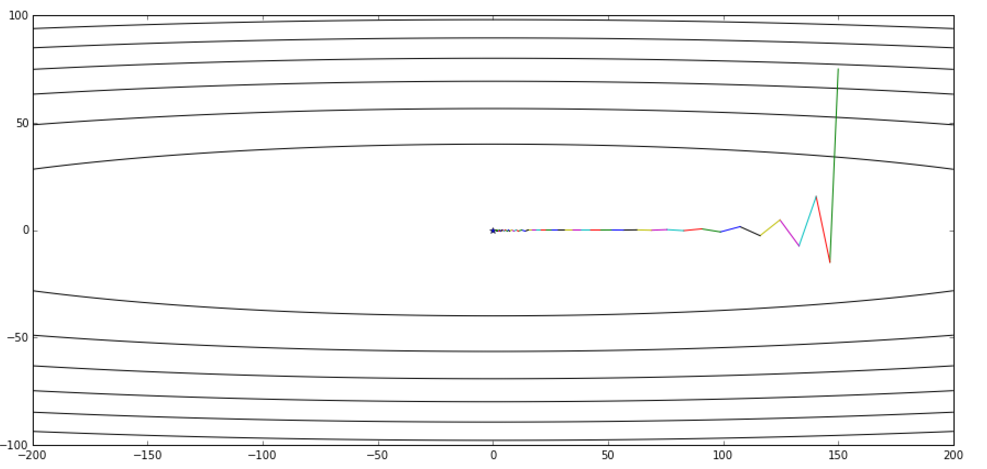
图片引自《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》,上图是Momentum的优化轨迹,下图是NAG的优化轨迹
为了从另一个角度更加深入地理解这个算法,我们可以对NAG原来的更新公式进行变换,得到这样的等效形式(具体推导过程放在最后啦):
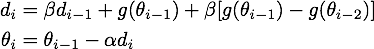
公式3,NAG的等效形式
这个NAG的等效形式与Momentum的区别在于,本次更新方向多加了一个,它的直观含义就很明显了:如果这次的梯度比上次的梯度变大了,那么有理由相信它会继续变大下去,那我就把预计要增大的部分提前加进来;如果相比上次变小了,也是类似的情况。这样的解释听起来好像和原本的解释一样玄,但是读者可能已经发现了,这个多加上去的项不就是在近似目标函数的二阶导嘛!所以NAG本质上是多考虑了目标函数的二阶导信息,怪不得可以加速收敛了!其实所谓“往前看”的说法,在牛顿法这样的二阶方法中也是经常提到的,比喻起来是说“往前看”,数学本质上则是利用了目标函数的二阶导信息。
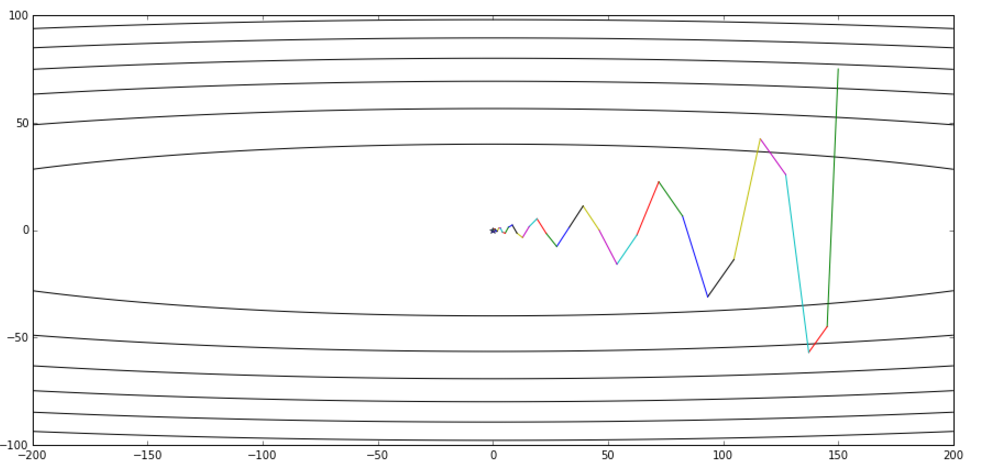
那么,变换后的形式真的与NAG的原始形式等效么?在给出数学推导之前,先让我用实验来说明吧:
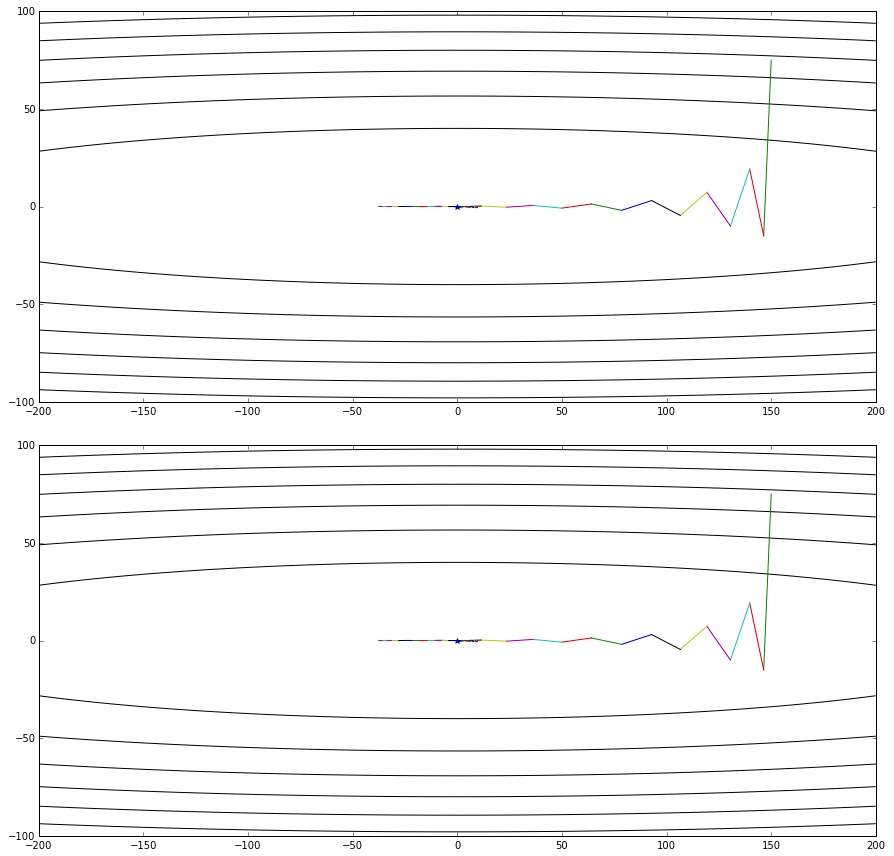
上图是公式3给出的优化轨迹,下图是公式2给出的优化轨迹——完全一样
实验代码放在Github,修改自《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》的实验代码。有兴趣的读者可以多跑几个起始点+学习率+衰减率的超参数组合,无论如何两个算法给出的轨迹都会是一样的。
最后给出NAG的原始形式到等效形式的推导。由
可得
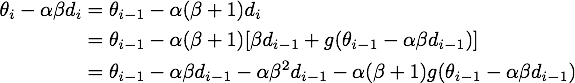 记
记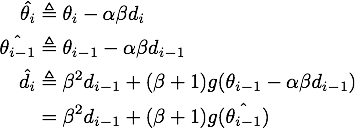
上式代入上上式,就得到了NAG等效形式的第二个式子:
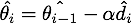 对
对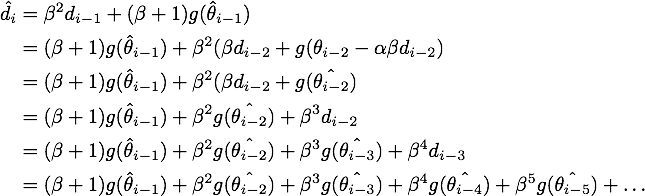
于是我们可以写出的形式,然后用
减去
消去后面的无穷多项,就得到了NAG等效形式的第一个式子:
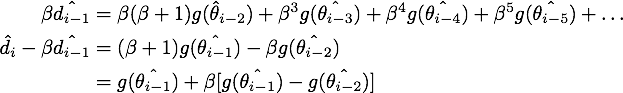
最终我们就得到了NAG的等效形式:
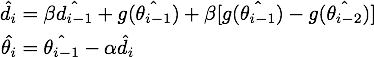
结论:在原始形式中,Nesterov Accelerated Gradient(NAG)算法相对于Momentum的改进在于,以“向前看”看到的梯度而不是当前位置梯度去更新。经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。
本文实验代码放在Github

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号