
MobileNet V1 深度可分离卷积(depthwise & pointwise convolution)
论文地址:
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNet的核心就是Depthwise separable convolution(深度可分离卷积),它将一般的卷积过程分为了depthwise convolution(逐深度卷积)和pointwise convolution(逐点卷积),在损失一点精度的情况下,计算量大幅下降,速度更快,模型更小。
先来看看一般的卷积过程,如下图:
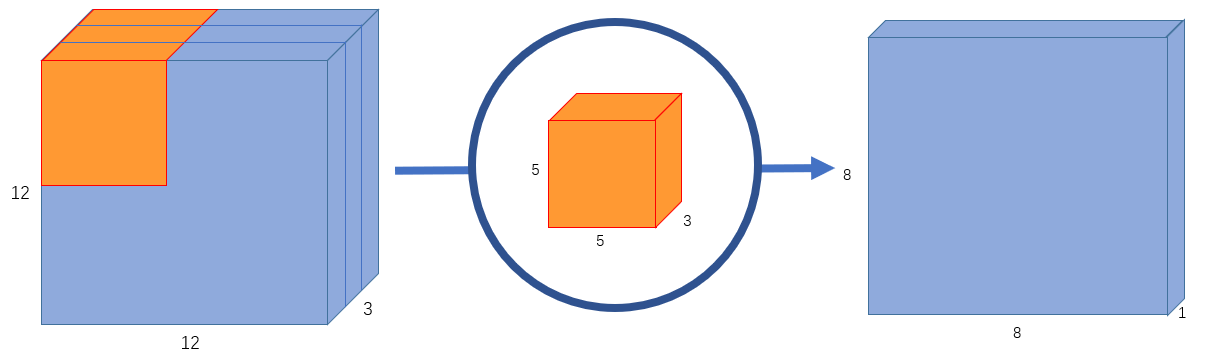
输入 的图像,即
,使用
的卷积核,
,无
,则卷积后,输出
的图像。
为了得到下图 的输出:
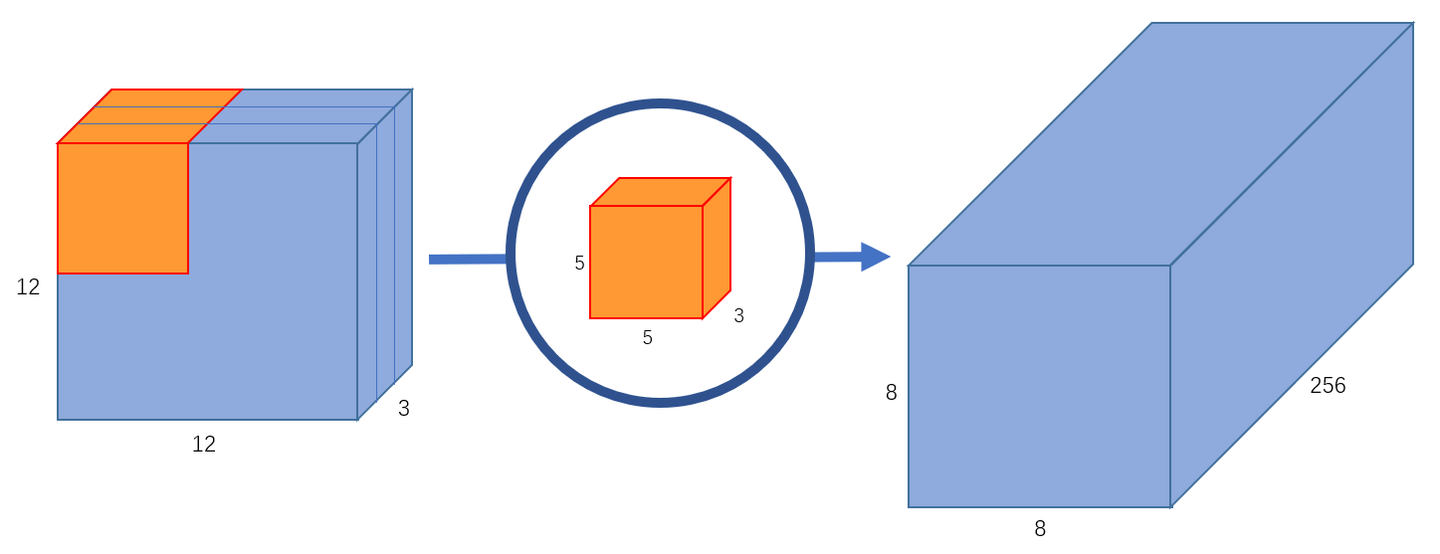
那么就需要256个卷积核(一个卷积核输出一个channel),因此总的计算量就为 ,即一个卷积核要在输入图像上滑动
个位置,每个位置进行
次运算,一共有
个卷积核。
如果用 表示卷积核的尺寸,
表示输入feature map的尺寸,
表示输入channel数,
表示输出channel数,那么在
且有
的情况下,总的计算量为:
Depthwise separable convolution的第一步是depthwise convolution,如下图:
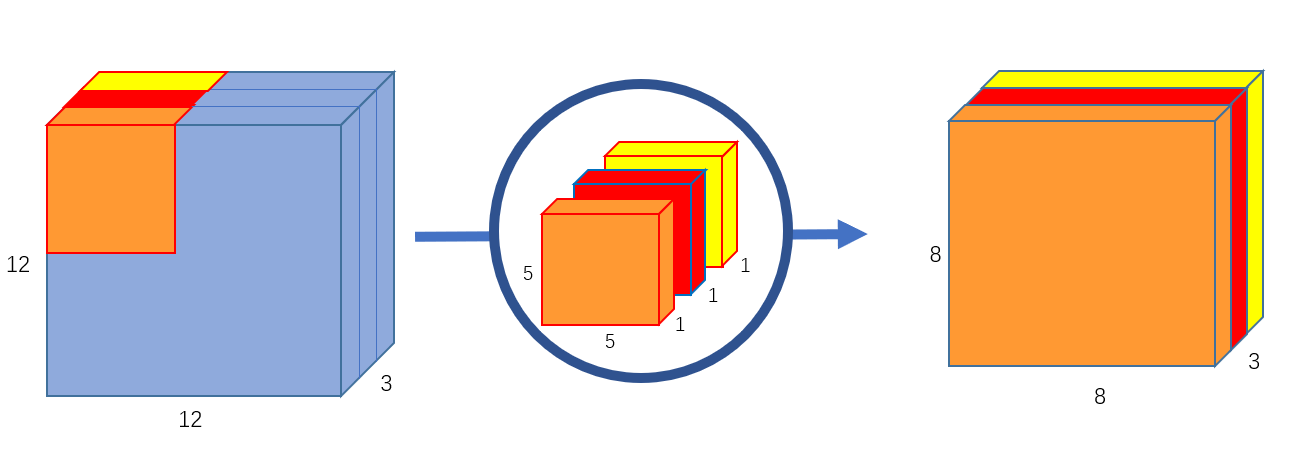
将原来的 的卷积核变为了3个
的卷积核,
卷积核常被用来减少channel数。每个卷积核只在输入图像的一个channel上操作,最后得到一个
的输出。
这一步的计算量为
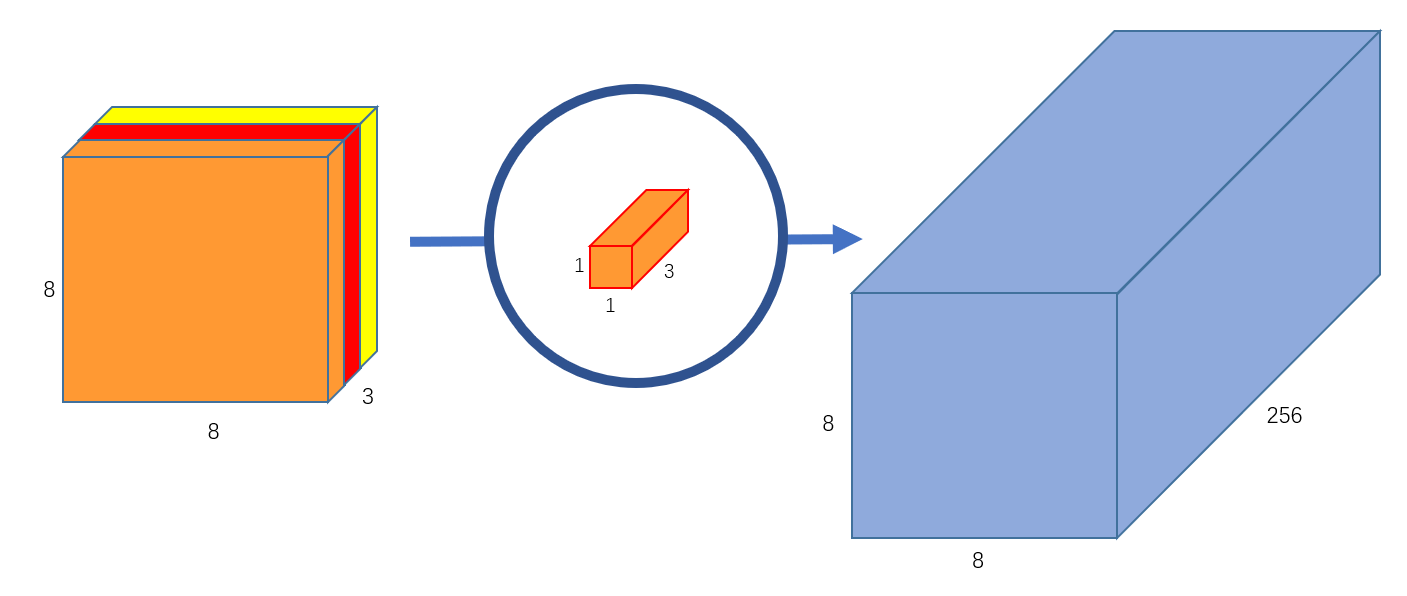
第二步是pointwise convolution,如下图:
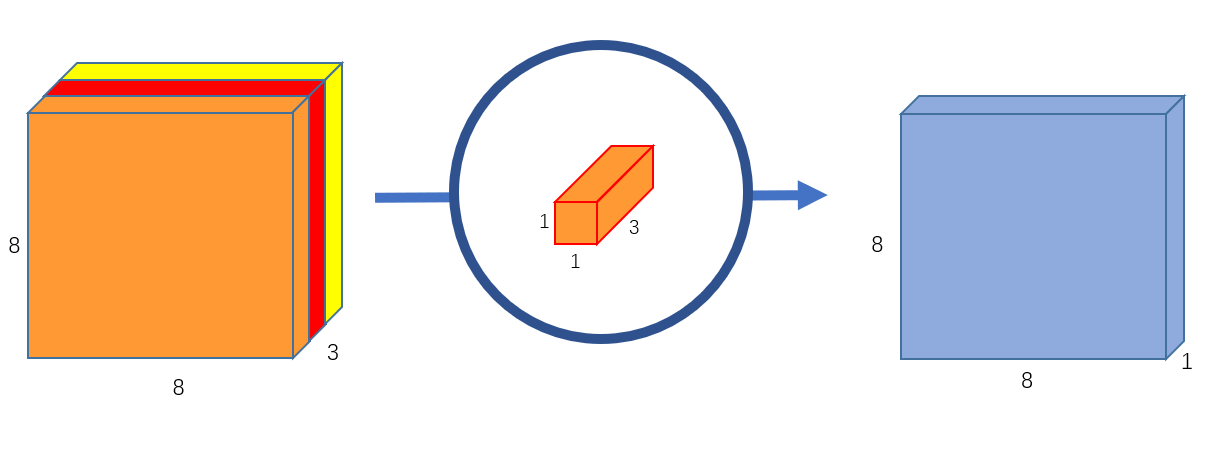
它使用一个 的卷积核对depthwise convolution的输出图像进行逐点卷积,最终就得到了
的输出。
如果使用256个 的卷积核就能得到
的输出图像了。
这一步的计算量为
因此这两步的计算量之和就为 ,只有原来的
倍的计算量。
于是 ,用上面的符号来表示的话,那么在 且有
的情况下,
depthwise convolution的计算量为:
pointwise convolution的计算量为:
因此Depthwise separable convolution就为一般卷积计算量的:
现在的问题是,为什么这么做了只损失了一点精度呢?(当然,对于原本就较小的模型来说,使用Depthwise separable convolution的话参数就更少了,性能就会大幅下降而不是只下降一点了)但卷积的一些东西本来就是黑盒,我们并不知道它的详细原理,只知道这么做是有效的。
参考
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号