
对 GAN 的 value function 的理解
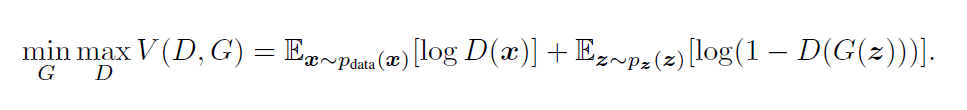
上式分为两个步骤:
- 第一步:调整discriminative model D的权重,使得V中两项取得最大值
- 第二步:调整generative model G的权重,使得V中第二项取得最小值
首先,分析log D(x)的含义:
- D(x)表示discriminative model D对一个原始样本的评分,评分越高,表示D越趋向于相信该样本是一个真实样本
- D(G(z))表示discriminative model D对一个生成样本的评分,评分越高,表示D越趋向于把一个生成样本当成了一个真实样本
因此,网络训练过程总结如下:
- 第一步:训练D,使得上述两个期望最大
- 第一项期望值最大,表示D将一个真实样本给出一个高的评分
- 第二项期望值最大,表示D将一个生成样本给出一个低分
第二步:训练G,使得期望值的第二项最小
- 第二项期望值最小,即:找到一个G,使其生成的样本能够在discriminative model D中获得一个较高的评分
图:GAN的训练收敛过程
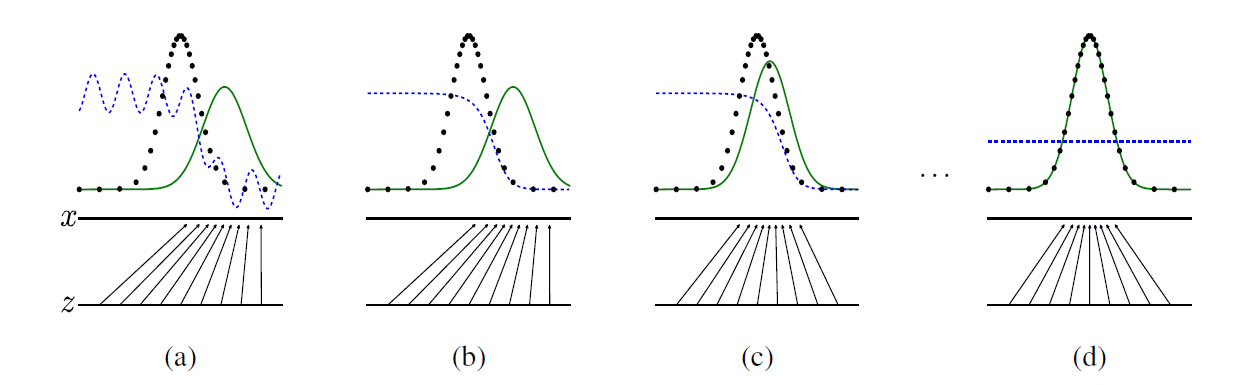
蓝色表示D
绿色表示G
黑色表示原数据
2019年8月18日
于南湖畔

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号