
Caffe-SSD相关源码说明和调试记录
1 对Blob的理解及其操作:
Blob是一个四维的数组。维度从高到低分别是:
(num_,channels_,height_,width_)
对于图像数据来说就是:图片个数,彩色通道个数,宽,高
Blob中数据是row-major存储的,W是变化最快的维度,例如在(n, k, h, w)处的数据,其物理偏移量计算方式为:
Blob的常用方法:
blob.data() // 返回数据
blob.diff() // 返回梯度
blob.shape() // 返回样本的形状
blob.num() // 返回样本的个数(常用)
blob.channels() // 返回通道的个数(常用)
blob.height() // 返回样本维度一,对于图像而言是高度(常用)
blob.width() // 返回样本维度二,对于图像而言是宽度(常用)
2 Layer:*.prototxt文件中各参数的说明
Data layer参数说明如下:
message ImageDataParameter {
// 指定图片数据 txt 路径.
optional string source = 1;
// batch size.
optional uint32 batch_size = 4 [default = 1];
// 随机跳过部分数据样本,以避免所有同步 sgd 客户端开始的样本相同.
// 其中,跳过的点设置为 rand_skip * rand(0,1).
// rand_skip 小于等于数据集样本数.
optional uint32 rand_skip = 7 [default = 0];
// 每个 epoch 后打乱数据顺序
optional bool shuffle = 8 [default = false];
// resize 图片到指定的 new_height 和 new_width 尺寸.
optional uint32 new_height = 9 [default = 0];
optional uint32 new_width = 10 [default = 0];
// 图片是彩色还是灰度图 color or gray
optional bool is_color = 11 [default = true];
// DEPRECATED. See TransformationParameter.
// 数据预处理时,可以进行简单的缩放(scale) 和减均值处理
// 减均值是在缩放处理前进行.
optional float scale = 2 [default = 1];
optional string mean_file: "mean.proto";
// DEPRECATED. See TransformationParameter.
// 从图片随机裁剪.
// 剪裁一个 227*227的图块,在训练阶段随机剪裁,在测试阶段从中间裁剪
optional uint32 crop_size = 227 [default = 0];
// DEPRECATED. See TransformationParameter.
// 随机水平翻转.
optional bool mirror = 6 [default = false];
optional string root_folder = 12 [default = ""];
}
window_data_param {
source: "window_data_train.txt"
batch_size: 128
crop_size: 256 # 要把bounding box warp到的大小
fg_threshold: 0.5 # 与ground truth 大于 fg_threshold 的bbox才作为正阳本
bg_threshold: 0.5 # 与ground truth 小于 bg_threshold 的bbox才作为正阳本
fg_fraction: 0.25 # 一个batch中正阳本数量的比例
crop_mode: "warp"
}
负样本的label是任意的, 但是overlap要小于threshold (绝对负样本可以将overlap 设置为 0)
卷积层参数说明:
layer {
name: "conv"
type: "Convolution"
bottom: "data"
top: "conv"
param {
lr_mult: 1 #权重的学习率 该层lr=lr_mult*base_lr
decay_mult: 1 #权重的衰减值
}
param {
lr_mult: 2 #偏置项的学习率
decay_mult: 0 #偏置项的衰减值
}
convolution_param {
num_output: 96 #该层输出的filter的个数。四维数组N*C*H*W中的N
kernel_size: 11 #卷积核大小11*11。可设定长kernel_h与宽kernel_w
stride: 4 #步长,也就是卷积核滑动的距离
weight_filler { #卷积核初始化方式
type: "gaussian" #高斯分布
std: 0.01 #标准差为0.01
}
bias_filler { #偏置项初始化方式
type: "constant" #连续分布
value: 0
}
}
}
3 Caffe中几个layer的区别:
Data对应数据库格式
WindowData对应存储在硬盘上的图片
DummyData用于开发与调试
5 caffe中的学习率的衰减机制
学习率更新,现在step exp 和multistep用的比较多。
根据 caffe/src/caffe/proto/caffe.proto 里的文件,可以看到它有以下几种学习率的衰减速机制:
(1). fixed: 在训练过程中,学习率不变;
(2). step: 它的学习率的变化就像台价一样;step by step 的; 其中的 gamma 与 stepsize需要设置的;
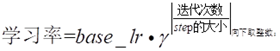
(3).exp :表示指数型的,其中参数 gamma 需要设置;
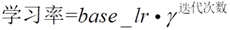
(4). inv : 其中参数 gamma 与 power 都需要设置;
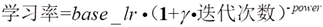
(5).multistep: 可以设置多个 stepvalue的值, 在prototxt里面也没有具体介绍, 它由参数 stepsize 与 stepvalue 决定; 它不是每时第刻都去计算 学习率,而是达到我们设定的stepvalue的时候,才去计算(根据方法2中的公式),然后更新学习率; stepvalue 可以设置多个的,下面是 stepvalue的定义;
183 repeated int32 stepvalue = 34;
(6).poly :多项式衰减 ,当到达最大次数时, 学习率变为了0;

(7).sigmoid形的:
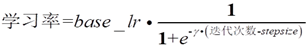
6 Caffe的solver.prototxt配置文件参数说明:
solver.prototxt文件是用来告诉caffe如何训练网络的。solver.prototxt的各个参数的解释如下:
base_lr
这个参数是用来表示网络的初始学习率的。这个值是一个浮点型实数。
lr_policy
这个参数是用来表示学习率随着时间是如何变化的。值是字符串,需要加""。学习率变化的可选参数有:
“step”——需要设置stepsize。根据gamma参数和stepsize参数来降低学习率,base_lr * gamma ^ (floor(iter / stepsize))。iter是当前迭代次数。学习率每迭代stepsize次变化一次。
“multistep”——与step类似,需要设置stepvalue,学习率根据stepvalue进行变化。
“fixed”——学习率base_lr保持不变。
“inv”——学习率变化公式为base_lr * (1 + gamma * iter) ^ (- power)
“exp”——学习率变化公式为base_lr * gamma ^ iter}
“poly”——学习率以多项式形式衰减,到最大迭代次数时降为0。学习率变化公式为base_lr * (1 - iter/max_iter) ^ (power)。
“sigmoid”——学习率以S型曲线形式衰减,学习率变化公式为base_lr * (1 / (1 + exp(-gamma * (iter - stepsize))))。
gamma
这个参数表示学习率每次的变化程度,值为实数。
stepsize
这个参数表示什么时候应该进行训练的下一过程,值为正整数。主要用在lr_policy为step的情况。
stepvalue
这个参数表示什么时候应该进行训练的下一过程,值为正整数。主要用在lr_policy为multistep的情况。
max_iter
这个参数表示训练神经网络迭代的最大次数,值为正整数。
momentum
这个参数表示在新的计算中要保留的前面的权重数量,值为真分数,通常设为0.9。
weight_decay
这个参数表示对较大权重的惩罚(正则化)因子。值为真分数。
This parameter indicates the factor of (regularization) penalization of large weights. This value is a often a real fraction.
solver_mode
这个参数用来表示求解神经网络的模式——值为CPU or GPU。
snapshot
这个参数用来表示每迭代多少次就应该保存snapshot的model和solverstate,值为正整数。
snapshot_prefix:
这个参数用来表示保存snapshot时model和solverstate的前缀,值为带引号的字符串。
net:
这个参数表示训练网络所在的位置,值为带引号的字符串。
test_iter
这个参数表示
这个参数表示每个test_interval进行多少次test迭代,值为正整数。
test_interval
这个参数表示什么时候进行数据的测试,值为正整数。
display
这个参数用来表示什么时候将输出结果打印到屏幕上,值为正整数,表示迭代次数。
type
这个参数表示训练神经网络采用的反向传播算法,值为带引号的字符串。可选的值有:
Stochastic Gradient Descent “SGD”——随机梯度下降,默认值。
AdaDelta “AdaDelta”——一种”鲁棒的学习率方法“,是基于梯度的优化方法。
Adaptive Gradient “AdaGrad”——自适应梯度方法。
Adam “Adam”——一种基于梯度的优化方法。
Nesterov’s Accelerated Gradient “Nesterov”——Nesterov的加速梯度法,作为凸优化中最理想的方法,其收敛速度非常快。
RMSprop “RMSProp”——一种基于梯度的优化方法。
2. Demo
lr_policy
# lr_policy为multisetp
base_lr: 0.01
momentum: 0.9
lr_policy: "multistep"
gamma: 0.9
stepvalue: 1000
stepvalue: 2000
stepvalue: 3000
stepvalue: 4000
stepvalue: 5000
# lr_policy为step
base_lr: 0.01
momentum: 0.9
lr_policy: "step"
gamma: 0.9
stepsize: 1000
solver.prototxt
net: "models/bvlc_alexnet/train_val.prototxt"
# 每次测试时进行1000次迭代
test_iter: 1000
# 每进行1000次训练执行一次测试
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "models/bvlc_alexnet/caffe_alexnet_train"
solver_mode: GPU
参考资料
http://www.cnblogs.com/denny402/p/5074049.html
https://github.com/BVLC/caffe/wiki/Solver-Prototxt
http://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe
7 Caffe中的SSD:
SSD 300在conv4_3生成prior box的conv4_3_norm_priorbox层prototxt定义如下:
- layer {
- name: "conv4_3_norm_mbox_priorbox"
- type: "PriorBox"
- bottom: "conv4_3_norm"
- bottom: "data"
- top: "conv4_3_norm_mbox_priorbox"
- prior_box_param {
- min_size: 30.0
- max_size: 60.0
- aspect_ratio: 2
- flip: true
- clip: false
- variance: 0.1
- variance: 0.1
- variance: 0.2
- variance: 0.2
- step: 8
- offset: 0.5
- }
- }
8 多GPU支持:
尽量一个实验用一块卡,caffe的多GPU并行做的不好。
不要-gpu 0,1,2. 用一个gpu即可
9 Tmux用法
(Ctrl+B) + (Shift+5) 打开一个新窗口
(Ctrl+B) + right/left 在不同窗口之间切换
(Ctrl+B) + [ 或 ] 进入复制模式,查看历史记录
tmux ls 列出当前会话列表
tmux attach 进入会话窗口
Ctrl+B+X 结束会话
10 Caffe-SSD安装配置记录
Github代码地址如下:
https://github.com/weiliu89/caffe/tree/ssd
安装步骤如下(github):
Installation
- Get the code. We will call the directory that you cloned Caffe into
$CAFFE_ROOT - Build the code. Please follow Caffe instruction to install all necessary packages and build it.
- Download fully convolutional reduced (atrous) VGGNet. By default, we assume the model is stored in
$CAFFE_ROOT/models/VGGNet/ - Download VOC2007 and VOC2012 dataset. By default, we assume the data is stored in
$HOME/data/ - Create the LMDB file.
- Download fully convolutional reduced (atrous) VGGNet. By default, we assume the model is stored in
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd
# Modify Makefile.config according to your Caffe installation.
cp Makefile.config.example Makefile.config
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
# (Optional)
make runtest -j8
Preparation
# Download the data.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh
Train/Eval
- Train your model and evaluate the model on the fly.
# It will create model definition files and save snapshot models in:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal.py
If you don't have time to train your model, you can download a pre-trained model at here.
- Evaluate the most recent snapshot.
- Test your model using a webcam. Note: press esc to stop.
# If you would like to test a model you trained, you can do:
python examples/ssd/score_ssd_pascal.py
# If you would like to attach a webcam to a model you trained, you can do:
python examples/ssd/ssd_pascal_webcam.py
Here is a demo video of running a SSD500 model trained on MSCOCO dataset.
- Check out
examples/ssd_detect.ipynborexamples/ssd/ssd_detect.cppon how to detect objects using a SSD model. Check outexamples/ssd/plot_detections.pyon how to plot detection results output by ssd_detect.cpp. - To train on other dataset, please refer to data/OTHERDATASET for more details. We currently add support for COCO and ILSVRC2016. We recommend using
examples/ssd.ipynbto check whether the new dataset is prepared correctly.
Models
We have provided the latest models that are trained from different datasets. To help reproduce the results in Table 6, most models contain a pretrained .caffemodel file, many .prototxt files, and python scripts.
- PASCAL VOC models:
- 07+12: SSD300*, SSD512*
- 07++12: SSD300*, SSD512*
- COCO[1]: SSD300*, SSD512*
- 07+12+COCO: SSD300*, SSD512*
- 07++12+COCO: SSD300*, SSD512*
- COCO models:
- ILSVRC models:
[1]We use examples/convert_model.ipynb to extract a VOC model from a pretrained COCO model.
13 Mean_file的生成:
sudo build/tools/compute_image_mean examples/mnist/mnist_train_lmdb examples/mnist/mean.binaryproto
带两个参数:
第一个参数:examples/mnist/mnist_train_lmdb, 表示需要计算均值的数据,格式为lmdb的训练数据。
第二个参数:examples/mnist/mean.binaryproto, 计算出来的结果保存文件。
14 ssd_detect.py的参数
def parse_args():
'''parse args'''
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
parser.add_argument('--labelmap_file',
default='data/VOC0712/labelmap_voc.prototxt')
parser.add_argument('--model_def',
default='models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt')
parser.add_argument('--image_resize', default=300, type=int)
parser.add_argument('--model_weights',
default='models/VGGNet/VOC0712/SSD_300x300/'
'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel')
parser.add_argument('--image_file', default='examples/images/fish-bike.jpg')
return parser.parse_args()
15 plot_detections.py的参数
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description = "Plot the detection results output by ssd_detect.")
parser.add_argument("resultfile",
help = "A file which contains all the detection results.")
parser.add_argument("imgdir",
help = "A directory which contains the images.")
parser.add_argument("--labelmap-file", default="",
help = "A file which contains the LabelMap.")
parser.add_argument("--visualize-threshold", default=0.01, type=float,
help = "Display detections with score higher than the threshold.")
parser.add_argument("--save-dir", default="",
help = "A directory which saves the image with detection results.")
parser.add_argument("--display-classes", default=None,
help = "If provided, only display specified class. Separate by ','")
16 ssd_detect.bin(及ssd_detect.cpp)的参数
Usage:
ssd_detect [FLAGS] model_file weights_file list_file
Flags from examples/ssd/ssd_detect.cpp:
-confidence_threshold (Only store detections with score higher than the
threshold.) type: double default: 0.01
-file_type (The file type in the list_file. Currently support image and
video.) type: string default: "image"
-mean_file (The mean file used to subtract from the input image.)
type: string default: ""
-mean_value (If specified, can be one value or can be same as image
channels - would subtract from the corresponding channel). Separated by
','.Either mean_file or mean_value should be provided, not both.)
type: string default: "104,117,123"
-out_file (If provided, store the detection results in the out_file.)
type: string default: ""
17 生成检测框并绘图
Step 1 使用训练好的模型检测图片:
build/examples/ssd/ssd_detect.bin models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt /home/daisida/ssd/models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_120000.caffemodel /home/daisida/ssd/list.txt --out_file tmp/output.txt
参数说明:
ssd_detect.bin:是ssd_detect.cpp的编译文件,类似于caffe中的classifier.bin,主要用于ssd训练模型的检测,相当main函数。
deploy.prototxt:网络结构参数
VGG_VOC0712_SSD_300×300_iter_120000.caffemodel:训练模型
test.txt:测试数据,可以是图片,可以是视频,每一行为图片或视频的路径
--file_type:文件类型,图片用image,视频用video
--out_file:检测结果输出文件
--condidence_threshold:阈值参数,这里设置为0.5,参数范围(0,1)
Step 2 结果可视化:
保存结果前需要将output.txt中的路径进行修改,去掉每行前边的路径,避免重复。
python examples/ssd/plot_detections.py tmp/output.txt /home/daisida/data/testset --labelmap-file data/VOC0712/labelmap_voc.prototxt --save-dir tmp/
报错:
/home/daisida/data/testset///home/daisida/data/testset/3.jpg does not exist
/home/daisida/data/testset///home/daisida/data/testset/9.jpg does not exist
/home/daisida/data/testset///home/daisida/data/testset/7.jpg does not exist
/home/daisida/data/testset///home/daisida/data/testset/2.jpg does not exist
/home/daisida/data/testset///home/daisida/data/testset/8.jpg does not exist
解决方案:
修改output.txt文件,去掉每行前边的路径,避免重复。
18 protobuf协议
定义一个消息类型
假设你想定义一个“搜索请求”的消息格式,每一个请求含有一个查询字符串、你感兴趣的查询结果所在的页数,以及每一页多少条查询结果。可以采用如下的方式来定义消息类型的.proto文件了:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3;
}
SearchRequest消息格式有3个字段,在消息中承载的数据分别对应于每一个字段。其中每个字段都有一个名字和一种类型。
指定字段类型
在上面的例子中,所有字段都是标量类型:两个整型(page_number和result_per_page),一个string类型(query)。当然,你也可以为字段指定其他的合成类型,包括枚举(enumerations)或其他消息类型。
分配标识号
正如上述文件格式,在消息定义中,每个字段都有唯一的一个标识符。这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。注:[1,15]之内的标识号在编码的时候会占用一个字节。[16,2047]之内的标识号则占用2个字节。所以应该为那些频繁出现的消息元素保留[1,15]之内的标识号。切记:要为将来有可能添加的、频繁出现的标识号预留一些标识号。
最小的标识号可以从1开始,最大到229 - 1, or 536,870,911。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。
指定字段规则
所指定的消息字段修饰符必须是如下之一:
required:一个格式良好的消息一定要含有1个这种字段。表示该值是必须要设置的;
optional:消息格式中该字段可以有0个或1个值(不超过1个)。
repeated:在一个格式良好的消息中,这种字段可以重复任意多次(包括0次)。重复的值的顺序会被保留。表示该值可以重复,相当于java中的List。
由于一些历史原因,基本数值类型的repeated的字段并没有被尽可能地高效编码。在新的代码中,用户应该使用特殊选项[packed=true]来保证更高效的编码。如:
repeated int32 samples = 4 [packed=true];
required是永久性的:在将一个字段标识为required的时候,应该特别小心。如果在某些情况下不想写入或者发送一个required的字段,将原始该字段修饰符更改为optional可能会遇到问题——旧版本的使用者会认为不含该字段的消息是不完整的,从而可能会无目的的拒绝解析。在这种情况下,你应该考虑编写特别针对于应用程序的、自定义的消息校验函数。Google的一些工程师得出了一个结论:使用required弊多于利;他们更愿意使用optional和repeated而不是required。当然,这个观点并不具有普遍性。
19 Caffe扩展层——ROIPooling的caffe实现
https://blog.csdn.net/jiongnima/article/details/80016683
20 多版本Python共存时的启动方式:
python2 *.py #启动Python2
python *.py #启动Python3
sudo python #启动系统Python,不加sudo,则启动用户bashrc中的Python
21 OpenCV的visualstudio2015(VC14)配置过程
(1) 下载并解压
(2) 配置环境变量:
D:\Program Files\opencv\build\x64\vc14\bin
(3) 新建控制台应用程序——空项目
(4) 选择编译模式为x64:项目右键——属性——连接器——高级——目标计算机:Machine64——右上角配置管理器——平台:新建——win32和x64
(5) 接下来有两种方案,(64位系统要选择debug模式为x64)一是此项目上右键属性,则只改变当前项目,二是视图——其他窗口——属性管理器——修改全局配置
(6) 工程上右键属性——包含目录:
D:\Program Files\opencv\build\include\opencv2
D:\Program Files\opencv\build\include\opencv
D:\Program Files\opencv\build\include
(7) 库目录:
D:\Program Files\opencv\build\x64\vc14\lib
(8) 链接器——输入——附加依赖项:
opencv_world345d.lib
opencv_world345.lib
(9) 测试代码:
#include<iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace cv;
int main()
{
// 读入一张图片(游戏原画)
Mat img = imread("pic.jpg");
// 创建一个名为 "游戏原画"窗口
namedWindow("游戏原画");
// 在窗口中显示游戏原画
imshow("游戏原画", img);
// 等待6000 ms后窗口自动关闭
waitKey(6000);
}
22 更新服务器CUDA版本
1. 删除所有服务器上的/home/public/local/cuda-7.5文件夹,只保留8.0文件夹,如果这台服务器已经安装过7.5的驱动,需要先卸载driver
卸载方法:
cd /home/public/local/cuda-7.5/bin
sudo ./uninstall_cuda_7.5.pl
(新安装机器只装了cuda8.0的直接删了cuda-7.5文件夹就可以)
2. 修改/home/bashrc文件里面的cuda路径
3. 修改自己的Makefile.config里面的cuda路径
4. 把10.90.41.188上/home/public/local/cuda-8.0.tar 和OpenCV-3.0-cuda8.0.tar 拷贝到每台机器上的/home/public/local下,并解压(没有显卡的机器也拷贝cuda8.0.tar,方便以后安装)
5. 把10.90.41.188上/home/public/local/anaconda2/lib/python2.7/site-packages/cv2.so 拷贝到对应机器上对应路径/home/public/local/anaconda2/lib/python2.7/site-packages/
重新make caffe和OpenCV
测试:
对于有显卡的机器,测试在python中import cv2
Boost 的修改过程:
为运行caffe,cd /usr/local/lib
将libboost_thread.so -> libboost_thread.so.1.68.0重命名为libboost_thread.so_bak
新建libboost_thread.so -> libboost_thread.so.1.66.0
23 OUT_OF_MEMORY
ps -aux | grep python | grep -v grep | awk '{print $2}' | xargs kill -9
24 Importing caffe results in ImportError: “No module named google.protobuf.internal” (import enum_type_wrapper)
解决方案:
pip install protobuf
25 每次运行代码之前需要考虑修改的地方
Train阶段:
(1) train.sh中的solver.prototxt路径
(2) train.sh中的caffemodel路径
(3) train.sh中的日志名称
(4) solver.prototxt中的net名称(也就是train.prototxt路径)
(5) solver.prototxt中的snapshot_prefix名称(包括路径+文件名)
(6) train.prototxt中的data层(有两个,TRAIN和TEST)输入文件的路径,即list.txt或者lmdb的路径
Test阶段:
(1) test.py脚本中的caffemodel改成训练好的caffemodel
(2) test.py中的prototxt改成deploy.prototxt
(3) test.py中的labelfile(即list.txt文件的路径)
26 从train.prototxt生成deploy.prototxt需要修改的地方
(1) 去掉输入层(有两个,phase=TRAIN或TEST),换成Input层:
layer {
name: "data_exp"
type: "ImageData"
top: "data_exp"
top: "label_exp"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 104
mean_value: 117
mean_value: 123
}
image_data_param {
source: "list.txt"
batch_size: 32
shuffle: true
}
}
改成:
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 144 dim: 144 } }
}
(2) 第一个卷积层的bottom变量要和输入层一致
(3) Loss层:从SoftmaxWithLoss改成Softmax
layer {
name: "loss_expression"
type: "SoftmaxWithLoss"
bottom: "pool10_expression"
bottom: "label_exp"
top: "loss_exp"
loss_weight: 1
include {
phase: TRAIN
}
}
改成:
layer {
name: "prob_expression"
type: "Softmax"
bottom: "pool10_expression"
top: "prob_expression"
}
(4) 去掉Accuracy层
(5) 对于多任务情况,还要去掉concat层(deploy阶段每次test只输入一张图片,同理也要去掉slice)
27 Caffe多任务训练
添加concat层以及slice层。
Concat用于拼接不同数据源的data,concat之后的数据经过网络传播,由slice层将feature分开,分别用于不同人物的训练,生成不同的loss。Slice_point就是batchsize。
train.prototxt需要修改的位置:
(1) 有几项任务,就要有几份输入数据(每项任务都要有各自的TRAIN和TEST数据输入层);同时注意batchsized的大小;
(2) 修改Concat层如下(TRAIN和TEST各有一个)
layer {
name: "concat"
bottom: "data_blink"
bottom: "data_obstacle"
bottom: "data_blur"
top: "data"
type: "Concat"
include {
phase: TRAIN
}
concat_param {
axis: 0
}
}
其中bottom是三项任务各自的输入数据层。
(3) 修改slice层(TRAIN和TEST各有一个):
layer {
name: "slice"
type: "Slice"
bottom: "fire9/concat"
top: "feature_blink"
top: "feature_obstacle"
top: "feature_blur"
include {
phase: TRAIN
}
slice_param {
axis: 0
slice_point: 128
slice_point: 256
}
}
(4) Slice层之后接不同任务的输出层:
Eg. Conv、relu、pooling、SoftmaxWithLoss、accuracy_smile
(5) 修改deploy.prototxt:

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号