
Unsupervised pre-training
如图所示:
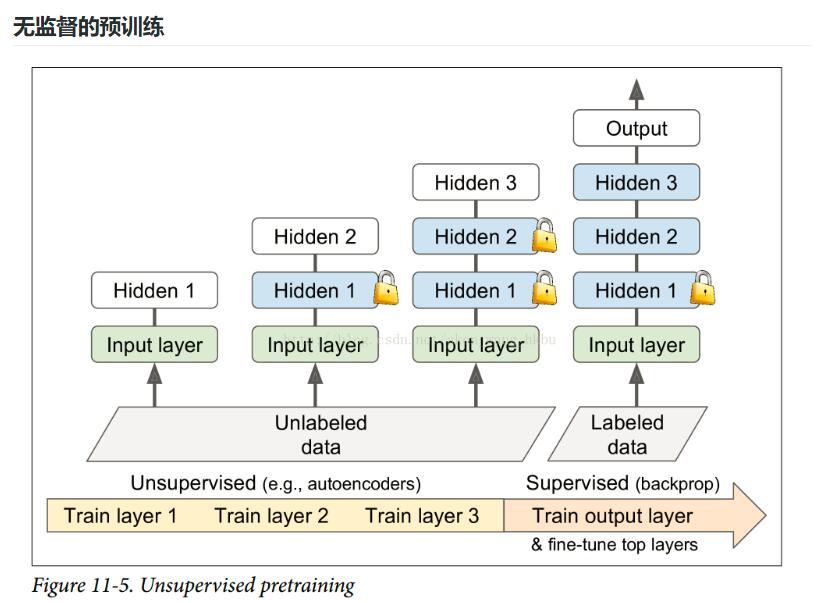
假设你想要解决一个复杂的任务,你没有太多的标记的训练数据,但不幸的是,你不能找到一个类似的任务训练模型。 不要失去所有希望! 首先,你当然应该尝试收集更多的有标签的训练数据,但是如果这太难或太昂贵,你仍然可以进行无监督的训练(见图 11-5)。 也就是说,如果你有很多未标记的训练数据,你可以尝试逐层训练层,从最低层开始,然后上升,使用无监督的特征检测算法,如限制玻尔兹曼机(RBM;见附录 E)或自动编码器(见第 15 章)。 每个层都被训练成先前训练过的层的输出(除了被训练的层之外的所有层都被冻结)。 一旦所有层都以这种方式进行了训练,就可以使用监督式学习(即反向传播)对网络进行微调。
这是一个相当漫长而乏味的过程,但通常运作良好。 实际上,这是 Geoffrey Hinton 和他的团队在 2006 年使用的技术,导致了神经网络的复兴和深度学习的成功。 直到 2010 年,无监督预训练(通常使用 RBM)是深度网络的标准,只有在梯度消失问题得到缓解之后,纯训练 DNN 才更为普遍。 然而,当您有一个复杂的任务需要解决时,无监督训练(现在通常使用自动编码器而不是 RBM)仍然是一个很好的选择,没有类似的模型可以重复使用,而且标记的训练数据很少,但是大量的未标记的训练数据。(另一个选择是提出一个监督的任务,您可以轻松地收集大量标记的训练数据,然后使用迁移学习,如前所述。 例如,如果要训练一个模型来识别图片中的朋友,你可以在互联网上下载数百万张脸并训练一个分类器来检测两张脸是否相同,然后使用此分类器将新图片与你朋友的每张照片做比较。)

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号