
流式计算形态下的大数据分析
1 介 绍
1.1 流式计算介绍
流式大数据计算主要有以下特征:
1)实时性。流式大数据不仅是实时产生的,也是要求实时给出反馈结果。系统要有快速响应能力,在短时间内体现出数据的价值,超过有效时间后数据的价值就会迅速降低。
2)突发性。数据的流入速率和顺序并不确定,甚至会有较大的差异。这要求系统要有较高的吞吐量,能快速处理大数据流量。
3)易失性。由于数据量的巨大和其价值随时间推移的降低,大部分数据并不会持久保存下来,而是在到达后就立刻被使用并丢弃。系统对这些数据有且仅有一次计算机会。
4)无限性。数据会持续不断产生并流入系统。在实际的应用场景中,暂停服务来更新大数据分析系统是不可行的,系统要能够持久、稳定地运行下去,并随时进行自我更新,以便适应分析需求。
1.2 应用场景介绍
互联网领域就是很好的流式大数据应用场景。该领域在日常运营中会产生大量数据,包括系统自动生成的用户、行为、日志等信息,也包括用户所实时分享的各类数据。互联网行业的数据量不仅巨大,其中半结构化和非结构化所呈现的数据也更多。由于互联网行业对系统响应时间的高要求,这些数据往往需要实时的分析和计算,以便及时为用户提供更理想的服务。
流式计算在互联网大数据中的典型应用场景如下:
1)社交网站。在社交网站中,要对用户信息进行实时分析,一方面将用户所发布的信息推送出去,另一方面也要为用户及时发现和推荐其感兴趣的内容,及时发现和防止欺诈行为,增进用户使用体验。
2)搜索引擎。搜素引擎除了向用户反馈搜索结果以外,还要考虑和计算用户的搜索历史,发掘用户感兴趣的内容和偏好,为用户推送推广信息。
3)电子商务。电子商务侧重于大数据技术中的用户偏好分析和关联分析,以便有针对性地向用户推荐商品。同时,随着大量电子商务开始内嵌互联网消费金融服务,对用户的风险分析和预警也是非常重要的。
可以预见,随着技术的不断发展、互联网与物联网等领域的不断深入连接,未来要分析的数据量必然还会爆炸性增长。传统的批量计算方式并不适合这类对响应时间要求很高的场景,能持续运行、快速响应的流式计算方法,才能解决这一方面的需求。
1.3 随机森林方法介绍
随机森林是目前海量数据处理中应用最广的分类器之一,在响应速度、数据处理能力上都有出色表现[10, 13]。随机森林是决策树{h(x,θk),k=1,…}的集合H,其中h(x,θk)是元分类器,是用CART算法生成的1棵没有剪枝的回归分类树;x为输入向量,{θk }是独立而且同分布随机向量,决定每一棵决策树的生长过程。
每个元分类器h∈H,都等价于从输入空间X到输出类集Y的映射函数。对输入空间X中的每一条输入xi,h都可以得到h(xi)=yi,yi为分类器h给出的决策结果。
定义决策函数D,则分类器集合H对输入xi所得到的最终结果y就可以定义如下:
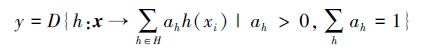
在随机森林中,单棵树的生长过程如下:
1)针对原始训练集,使用Bagging方法在原始样本集S中进行有放回的随机数据选取,形成有区别的训练集Tset。
2)采用抽样的方式选取特征。假设数据集一共有N个特征,选择其中M个特征,M≤N。每个抽取出来的训练集,使用随机选取的M个特征来进行节点分裂。
3)所有生成的决策树自由生长,不进行剪枝。每一棵决策树的输出结果之间可采用简单的多数投票法(针对分类问题)或者结果平均法(针对回归问题)组合成最终的输出结果。
随机森林方法是组合分类器算法的一种,是决策树的组合。它拥有Bagging和随机特征选择这2种方法的优点。在大数据环境下,随机森林方法还有以下优点:
① 随机森林方法可以处理大数据量,能够应对突发性数据;
② 随机森林方法生成较为简单的决策树,易于解读;
③ 随机森林方法适用于分布式和并行环境,扩展性好,适用于对分布式架构有很高要求的流式大数据处理环境;
4)决策树分类器非常简单,能以极高效率对新数据进行处理,适用于流式大数据环境下对响应速度要求高的特点;
在流式大数据环境下,随机森林方法也存在一些问题,其中最核心的问题,就是流式大数据环境中数据具有实时性和易失性的特点,经典随机森林方法难以适应。以训练集数据为基础所生成的决策树会过期,对新数据进行分类的准确度下降。
2 流式大数据环境下的算法改进2.1 方法改进思路
以往对随机森林方法的改进主要集中在几个方面:
将随机森林与Hadoop、MapReduce等计算框架结合,实现分布式随机森林方法,提高算法的处理效率。
对数据进行预处理,降低数据集的不平衡性,以此提升算法在非平衡性数据集上的准确度和分类性能。
针对标准随机森林方法采用C4.5作为节点分裂算法的情况,用效率更高的节点分裂算法如CHI2来替换C4.5,可以提高算法处理大数据集的能力。
基于分类器相似性度量和分类间隔概念,对冗余的分类器进行修剪,以取得更好的分类效果与更小的森林规模。
这几种改进方法可以有效地在特定环境下提高随机森林算法的表现,但都不能完全满足流式大数据环境对算法的要求。鉴于流式大数据算法需求所表现出来的鲜明特征,从流式大数据的特征出发,对经典的随机森林方法进行改造,思路如下:
1)使用随机森林方法实时处理数据,由于随机森林是一种比较简单的分类器,对数据的响应时间可以得到保障,能够满足实时性要求。
2)仅对一段时间内的数据进行存储,在内存可用的条件下处理少量数据,这样就可以解决流式大数据的易失性和无限性特点。
3)由于数据的无序性,经典随机森林所产生的分类器无法满足所有的输入数据,必须令分类器能够随着新数据的输入不断更新,保持对数据的敏感性和准确度。因为数据的易失性,所以分类器的更新就必须基于算法所临时保存的有限训练数据进行。
4)分类器更新方法必须是可伸缩的、高效的,不能影响到分类器对数据的正常处理。
2.2 改进后的随机森林方法
首先定义随机森林中决策树h的准确度(accurate)Ah:
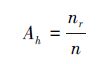
式中,nr是决策树h给出正确结果的次数,n是决策树h所处理过的所有数据数量。准确度给出了在一定时间内某棵树给出正确结果的比例。
在回归问题中,决策树h给出的分类结果如与最终结果一致,则认为该决策树得出了正确结果。计算决策树h给出结果xi与最终结果之间的差值,并取其标准差作为h的准确度:
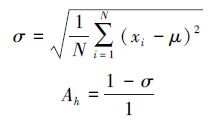
准确度衡量一棵树在一段时间内判定结果的准确程度。算法在执行过程中跟踪每棵树的准确度,并定期对随机森林进行更新,淘汰其中准确度最低的树:
1)按照标准的随机森林方法构造决策树群H。
2)为每一棵决策树h,h∈H建立1张记录表Th,记录随机森林在处理数据过程中生成的结果。
3)一段时间后,对所有决策树的结果记录表进行扫描,删除其中准确度最低的树。
通过准确度进行筛选后,森林中树的数量会越来越少,实现决策树集的剪枝。但数量的过分减少,也会造成整个决策树集在准确度上的降低[11]。
为了保持一定数量的决策树,在剪枝的同时,也要对数据集进行跟踪,生成新的决策树来保持整个森林的质量。为了从数据集中筛选出对生成新的决策树更有用的样本,引入间隔(margin)定义如下: 间隔指随机森林在1条给定样本数据(x,y)上的整体决策正确度,定义为:
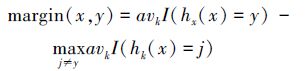
式中,avk( )是一个求均值函数,I( )是一个度量函数。如果在随机森林中大部分决策树对样本(x,y)得到正确结果,则margin(x,y)大于零。如果margin(x,y)小于零或某一阈值,则说明该样本被大部分决策树识别失误,算法对该样本得出了错误结论。
margin(x,y)大于零的样本,说明决策树集可以得到正确结果。与已有的决策树相似度高的树并不会提高整个森林的准确度,此类样本不需要再次处理。为了让新生成的决策树能够提高整个森林的准确度,记录margin(x,y)小于等于零的样本,形成新的训练数据集S′。数据集S′的特点,是只占当前数据集S中的一小部分,但其数据特征与其他数据不同。
在数据集S′上使用随机森林方法,获得一个新的决策树集合{h′(x,θk),k=1,…}。数据集S′只代表了全部数据集中的一部分数据,在S′中筛选一定比例的决策树,加入原来的决策树集合中。
根据S′与S之间的比例确定要筛选出的决策树数量:
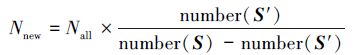
筛选方法可以有以下几种:
S′筛选法:利用S′进行检验,并按照准确度对所有决策树排序,选择其中准确度最高的Nnew棵决策树。
S筛选法:利用全部数据集S进行检验,并按准确度对所有决策树排序,选择准确度最高的Nnew棵树。
Margin筛选法:计算每棵树在数据集S′上的margin均值与margin方差之比[18],作为每一棵决策树的重要性衡量指标,选择最重要的Nnew棵树。
改进后的随机森林方法流程如图 1所示。

|
| 图 1 改进后随机森林方法流程图 |
|
图选项
|
① 使用初始训练数据集S生成最初的随机森林H;
② 使用随机森林H对当前待处理的数据集Si进行分类:
a) 用随机森林中的每一棵树hj对Si中的每一条数据xj进行分类;
b) 记录每一棵树和每一条数据的分类结果,同时计算该条数据分类结果的间隔值margin(xj,y);
c) 如果margin(xj,y)小于给定阈值,则将xj加入新训练数据集S′。
③ Si分类完毕后,计算每棵树的准确度,并进行剪枝;
④ 在新训练数据集S′上执行随机森林方法,生成新的随机森林H′;
⑤ 对新的随机森林进行剪枝,将剪枝后的H′与H合并,形成新的随机森林H;
⑥ 清空训练数据集S′,开始处理下一批数据。
2.3 新随机森林方法的优点
新的随机森林方法有着以下优点:
1)新方法每次所处理的数据集是有限的,在实际应用中,可以根据内存大小设计每次处理的数据集大小,保证数据的实时计算和计算效率;
2)新方法中,需要存储的只有结果记录表和新训练数据集,相比原始数据流小了很多,满足流式大数据的易失性特点,在大数据量下的伸缩性更好;
3)对新数据的处理只需要使用随机森林进行验证和投票,执行效率高,能够实时反馈数据的处理结果;
4)该系统可以持续地更新运行下去,并能够不断使用数据的新特性来更新自身,满足流式大数据环境的无序性和无限性特点。

如果这篇文章帮助到了你,你可以请作者喝一杯咖啡


 浙公网安备 33010602011771号
浙公网安备 33010602011771号