UE调用Cuda
本文记录了UE4调用cuda静态链接库的过程, 参考文章 https://www.sciement.com/tech-blog/c/cuda_in_ue4/
一.安装visual studio & CUDA
确保先安装visual studio, 然后安装cuda,链接-> https://developer.nvidia.com/cuda-downloads
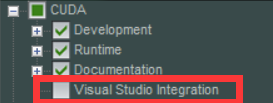
安装CUDA时需要勾选 visual studio Integration 选项
二.创建一个CUDA项目
-
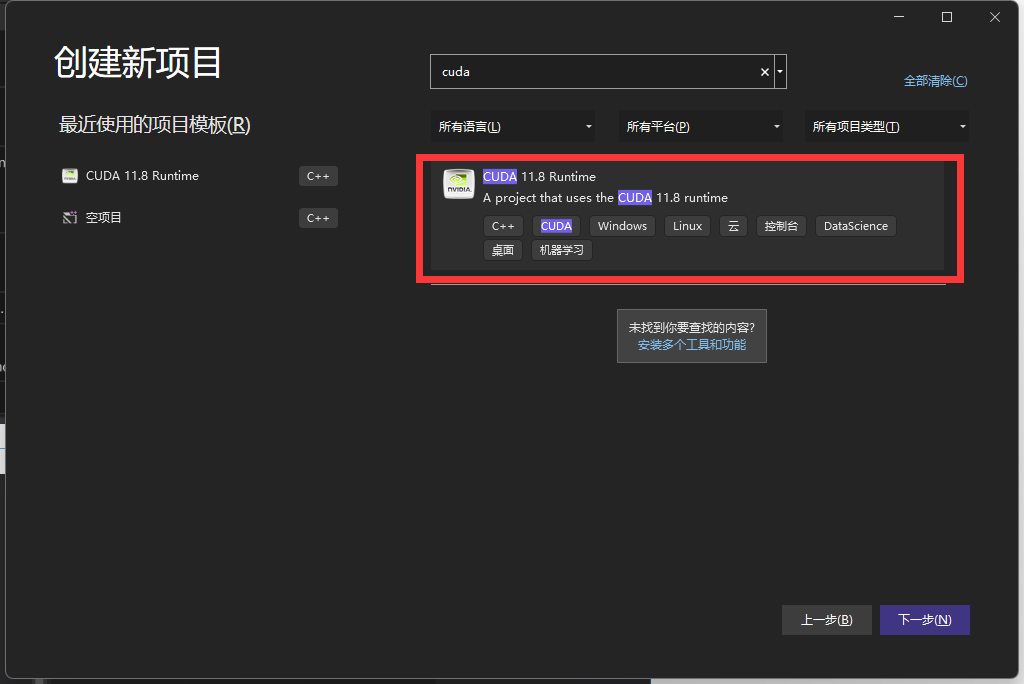
1.打开VS,创建一个CUDA项目
-
2.静态库lib生成设置
- 从debug模式切换到release模式
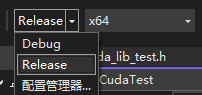
- 右键项目,选择属性
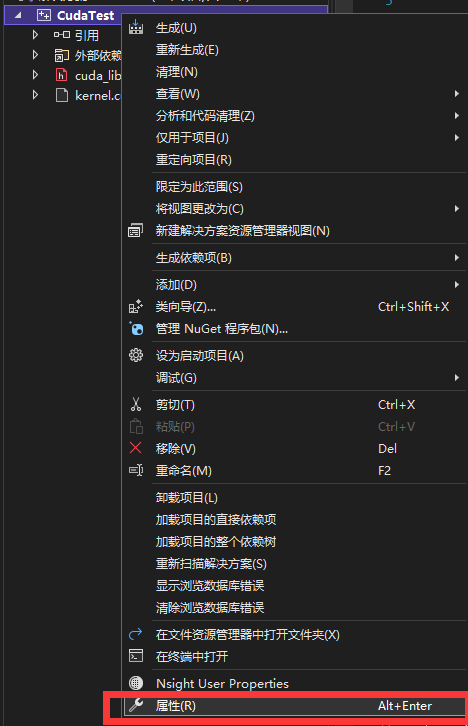
- 确保配置为 release, 且常规-配置类型 选择 静态链接库lib
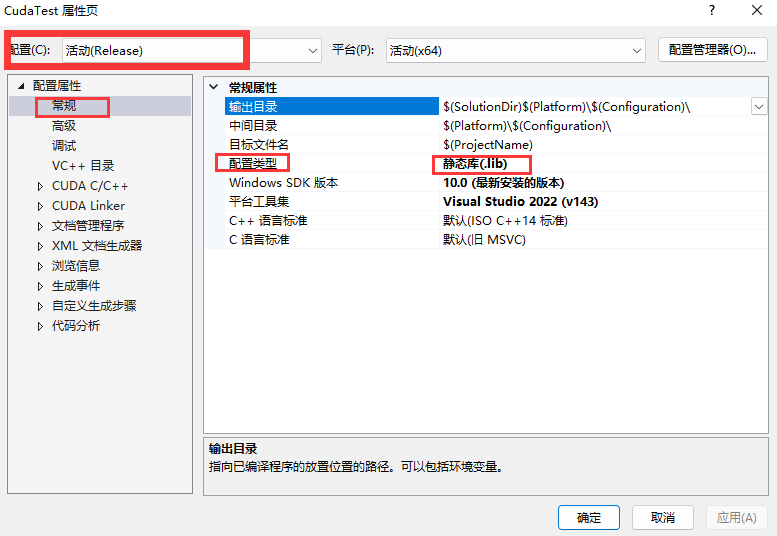
- 从debug模式切换到release模式
-
3.CUDA函数的实现
默认情况下,会自动创建一个名为kernel.cu 的CUDA 示例函数。
为了确保 CUDA 的独特类型可以在 Unreal Engine 4 上毫无问题地使用,所以我制作了 addWithCuda2,它除了 addWithCuda 之外还使用 int4 类型。
当然,剪掉头文件也是必要的。- kernel.cu file
#include "cuda_lib_test.h" __global__ void addKernel(int* c, const int* a, const int* b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } __global__ void addKernel2(int4* c, const int4* a, const int4* b) { int i = threadIdx.x; c[i].x = a[i].x + b[i].x; c[i].y = a[i].y + b[i].y; c[i].z = a[i].z + b[i].z; c[i].w = a[i].w + b[i].w; } // Helper function for using CUDA to add vectors in parallel. cudaError_t addWithCuda(int* c, const int* a, const int* b, unsigned int size, std::string* error_message) { int* dev_a = 0; int* dev_b = 0; int* dev_c = 0; cudaError_t cuda_status; // Choose which GPU to run on, change this on a multi-GPU system. cuda_status = cudaSetDevice(0); if (cuda_status != cudaSuccess) { *error_message = "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"; goto Error; } // Allocate GPU buffers for three vectors (two input, one output) . cuda_status = cudaMalloc((void**)&dev_c, size * sizeof(int)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } cuda_status = cudaMalloc((void**)&dev_a, size * sizeof(int)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } cuda_status = cudaMalloc((void**)&dev_b, size * sizeof(int)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } // Copy input vectors from host memory to GPU buffers. cuda_status = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } cuda_status = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } // Launch a kernel on the GPU with one thread for each element. addKernel << <1, size >> > (dev_c, dev_a, dev_b); // Check for any errors launching the kernel cuda_status = cudaGetLastError(); if (cuda_status != cudaSuccess) { *error_message = "addKernel launch failed: " + std::string(cudaGetErrorString(cuda_status)); goto Error; } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cuda_status = cudaDeviceSynchronize(); if (cuda_status != cudaSuccess) { *error_message = "cudaDeviceSynchronize returned error code " + std::to_string(cuda_status) + " after launching addKernel!"; goto Error; } // Copy output vector from GPU buffer to host memory. cuda_status = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } Error: cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return cuda_status; } // Helper function for using CUDA to add vectors in parallel. cudaError_t addWithCuda2(int4* c, const int4* a, const int4* b, std::string* error_message) { int4* dev_a = 0; int4* dev_b = 0; int4* dev_c = 0; const unsigned int size = 1; cudaError_t cuda_status; // Choose which GPU to run on, change this on a multi-GPU system. cuda_status = cudaSetDevice(0); if (cuda_status != cudaSuccess) { *error_message = "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"; goto Error; } // Allocate GPU buffers for three vectors (two input, one output) . cuda_status = cudaMalloc((void**)&dev_c, size * sizeof(int4)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } cuda_status = cudaMalloc((void**)&dev_a, size * sizeof(int4)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } cuda_status = cudaMalloc((void**)&dev_b, size * sizeof(int4)); if (cuda_status != cudaSuccess) { *error_message = "cudaMalloc failed!"; goto Error; } // Copy input vectors from host memory to GPU buffers. cuda_status = cudaMemcpy(dev_a, a, size * sizeof(int4), cudaMemcpyHostToDevice); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } cuda_status = cudaMemcpy(dev_b, b, size * sizeof(int4), cudaMemcpyHostToDevice); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } // Launch a kernel on the GPU with one thread for each element. addKernel2 << <1, size >> > (dev_c, dev_a, dev_b); // Check for any errors launching the kernel cuda_status = cudaGetLastError(); if (cuda_status != cudaSuccess) { *error_message = "addKernel launch failed: " + std::string(cudaGetErrorString(cuda_status)); goto Error; } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cuda_status = cudaDeviceSynchronize(); if (cuda_status != cudaSuccess) { *error_message = "cudaDeviceSynchronize returned error code " + std::to_string(cuda_status) + " after launching addKernel!"; goto Error; } // Copy output vector from GPU buffer to host memory. cuda_status = cudaMemcpy(c, dev_c, size * sizeof(int4), cudaMemcpyDeviceToHost); if (cuda_status != cudaSuccess) { *error_message = "cudaMemcpy failed!"; goto Error; } Error: cudaFree(dev_c); cudaFree(dev_a); cudaFree(dev_b); return cuda_status; }- cuda_lib_test.h file
#pragma once #include <string> #include "cuda_runtime.h" #include "vector_types.h" #include "vector_functions.h" #include "device_launch_parameters.h" cudaError_t addWithCuda(int* c, const int* a, const int* b, unsigned int size, std::string* error_message); cudaError_t addWithCuda2(int4* c, const int4* a, const int4* b, std::string* error_message); -
4.创建一个CUDA静态库lib
- 构建项目,在 ProjectPath/x64/Release 文件夹中创建了一个 .lib
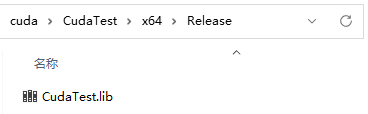
- 构建项目,在 ProjectPath/x64/Release 文件夹中创建了一个 .lib
-
5.创建一个UE4项目
-
使用UE4创建一个空的c++项目, 然后创建一个合适的 C++ 类来编写代码。我创建了一个名为 CActor 的 Actor 继承类。
目录结构如下
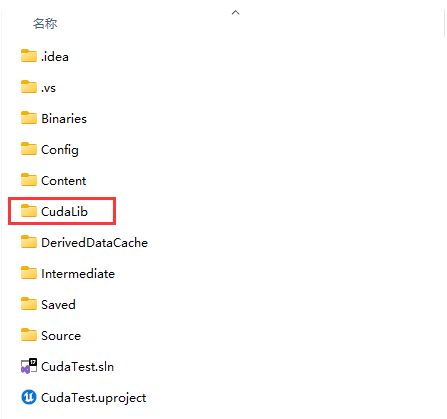
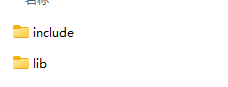
在这里,我创建了一个 CUDALib 文件夹,然后是一个 include 文件夹和一个 lib 文件夹,并分别复制了 header(cuda_lib_test.h) 和 .lib (kernel.cu)文件。
-
-
6.Bulid.cs设置
// Copyright Epic Games, Inc. All Rights Reserved. using UnrealBuildTool; using System.IO; public class CudaTest : ModuleRules { private string poject_root_path { get { return Path.Combine(ModuleDirectory, "../.."); } } public CudaTest(ReadOnlyTargetRules Target) : base(Target) { PCHUsage = PCHUsageMode.UseExplicitOrSharedPCHs; PublicDependencyModuleNames.AddRange(new string[] { "Core", "CoreUObject", "Engine", "InputCore" }); PrivateDependencyModuleNames.AddRange(new string[] { }); string custom_cuda_lib_include = "CudaLib/include"; string custom_cuda_lib_lib = "CudaLib/lib"; PublicIncludePaths.Add(Path.Combine(poject_root_path, custom_cuda_lib_include)); PublicAdditionalLibraries.Add(Path.Combine(poject_root_path, custom_cuda_lib_lib, "CudaTest.lib")); string cuda_path = "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8"; string cuda_include = "include"; string cuda_lib = "lib/x64"; PublicIncludePaths.Add(Path.Combine(cuda_path, cuda_include)); //PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "cudart.lib")); PublicAdditionalLibraries.Add(Path.Combine(cuda_path, cuda_lib, "cudart_static.lib")); // Uncomment if you are using Slate UI // PrivateDependencyModuleNames.AddRange(new string[] { "Slate", "SlateCore" }); // Uncomment if you are using online features // PrivateDependencyModuleNames.Add("OnlineSubsystem"); // To include OnlineSubsystemSteam, add it to the plugins section in your uproject file with the Enabled attribute set to true } } -
7.编辑CActor.h,在头文件中写了实现,因为它是为了验证
// Fill out your copyright notice in the Description page of Project Settings.
#pragma once
#include "CoreMinimal.h"
#include "GameFramework/Actor.h"
#include "cuda_lib_test.h"
#include "CActor.generated.h"
UCLASS()
class CUDATEST_API ACActor : public AActor
{
GENERATED_BODY()
public:
// Sets default values for this actor's properties
ACActor();
UFUNCTION(BlueprintCallable, Category = "CUDATest")
bool SimpleCUDATest() {
// ----- addWithCuda test -----
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
std::string error_message;
// Add vectors in parallel.
cudaError_t cuda_status = addWithCuda(c, a, b, arraySize, &error_message);
if (cuda_status != cudaSuccess) {
UE_LOG(LogTemp, Warning, TEXT("addWithCuda failed!\n"));
UE_LOG(LogTemp, Warning, TEXT("%s"), *FString(error_message.c_str()));
return false;
}
UE_LOG(LogTemp, Warning, TEXT("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}"), c[0], c[1], c[2], c[3], c[4]);
// ----- addWithCuda2 test -----
const int4 a_int4 = make_int4(1, 2, 3, 4);
const int4 b_int4 = make_int4(10, 20, 30, 40);
int4 c_int4;
// Add vectors in parallel.
cuda_status = addWithCuda2(&c_int4, &a_int4, &b_int4, &error_message);
if (cuda_status != cudaSuccess) {
UE_LOG(LogTemp, Warning, TEXT("addWithCuda failed!\n"));
UE_LOG(LogTemp, Warning, TEXT("%s"), *FString(error_message.c_str()));
return false;
}
UE_LOG(LogTemp, Warning, TEXT("{1,2,3,4} + {10,20,30,40} = {%d,%d,%d,%d}"), c_int4.x, c_int4.y, c_int4.z, c_int4.w);
return true;
}
protected:
// Called when the game starts or when spawned
virtual void BeginPlay() override;
public:
// Called every frame
virtual void Tick(float DeltaTime) override;
};
此时构建项目将编译通过,并打开虚幻编辑器
- 8.虚幻编辑器中的设置
- 创建一个名为CAcotr_BP的蓝图类,父类为CActor,调用之前在CActor中创建的 SimpleCUDATest()
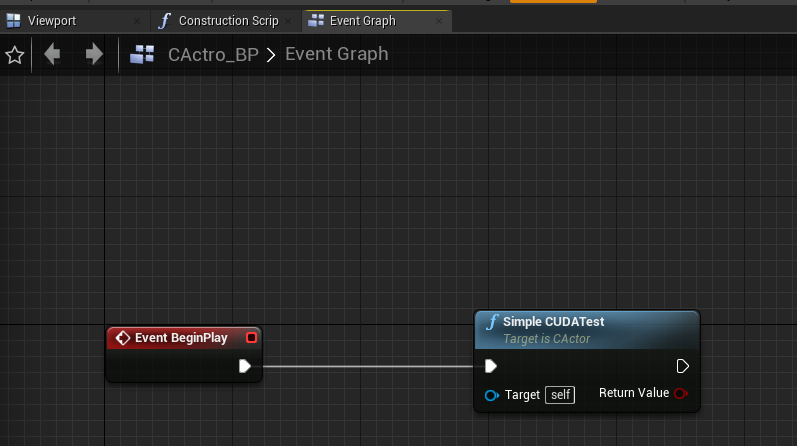
- 将CAcotr_BP放置到场景中
- Window -> Developer Tools -> Output Log
- RUN
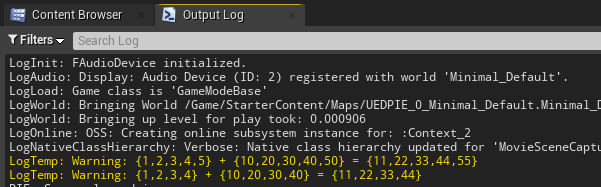
可以看到调用了CUDA核函数,加法计算正确
- 创建一个名为CAcotr_BP的蓝图类,父类为CActor,调用之前在CActor中创建的 SimpleCUDATest()
- 参考 https://www.sciement.com/tech-blog/c/cuda_in_ue4/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号