

Paper Reading
论文精读
论文精读方法参考B站UP主跟李沐学AI
阅读顺序:Abastract -> Introduction -> Conclusion -> Related Work
ResNet
网络结构
核心模块:Residual Block
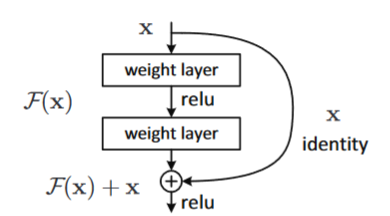
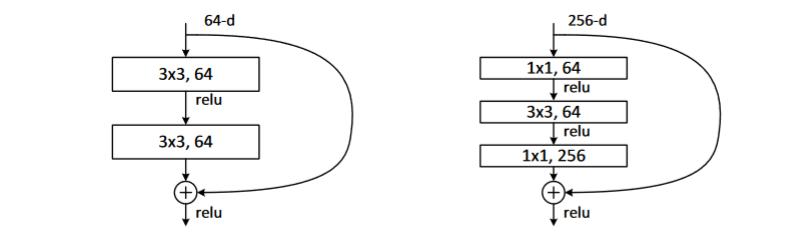
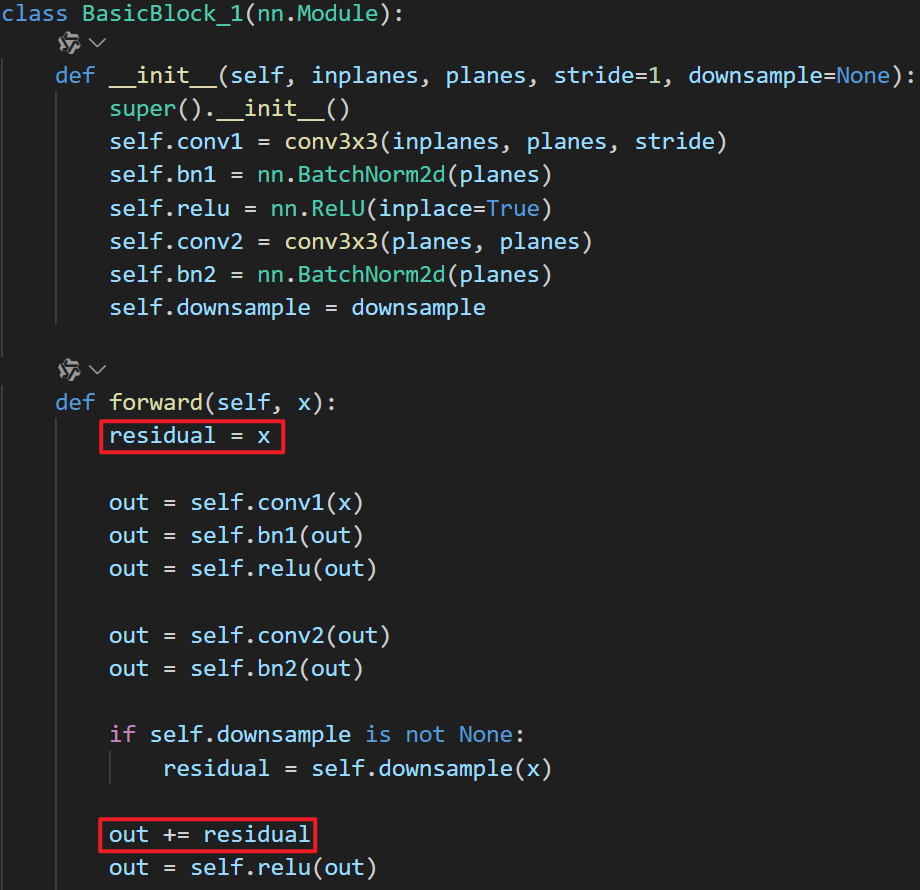
代码实现

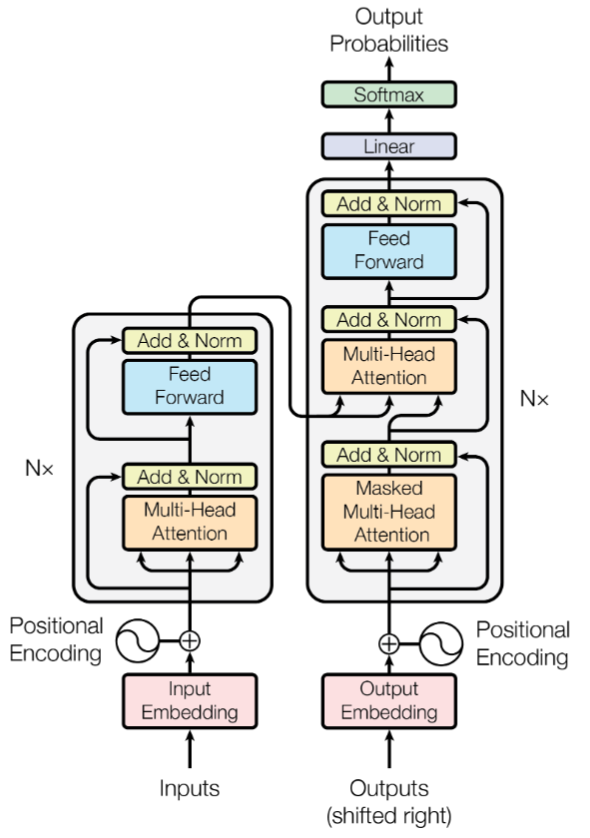
Transformer
网络结构
Multi-Head Attention
-
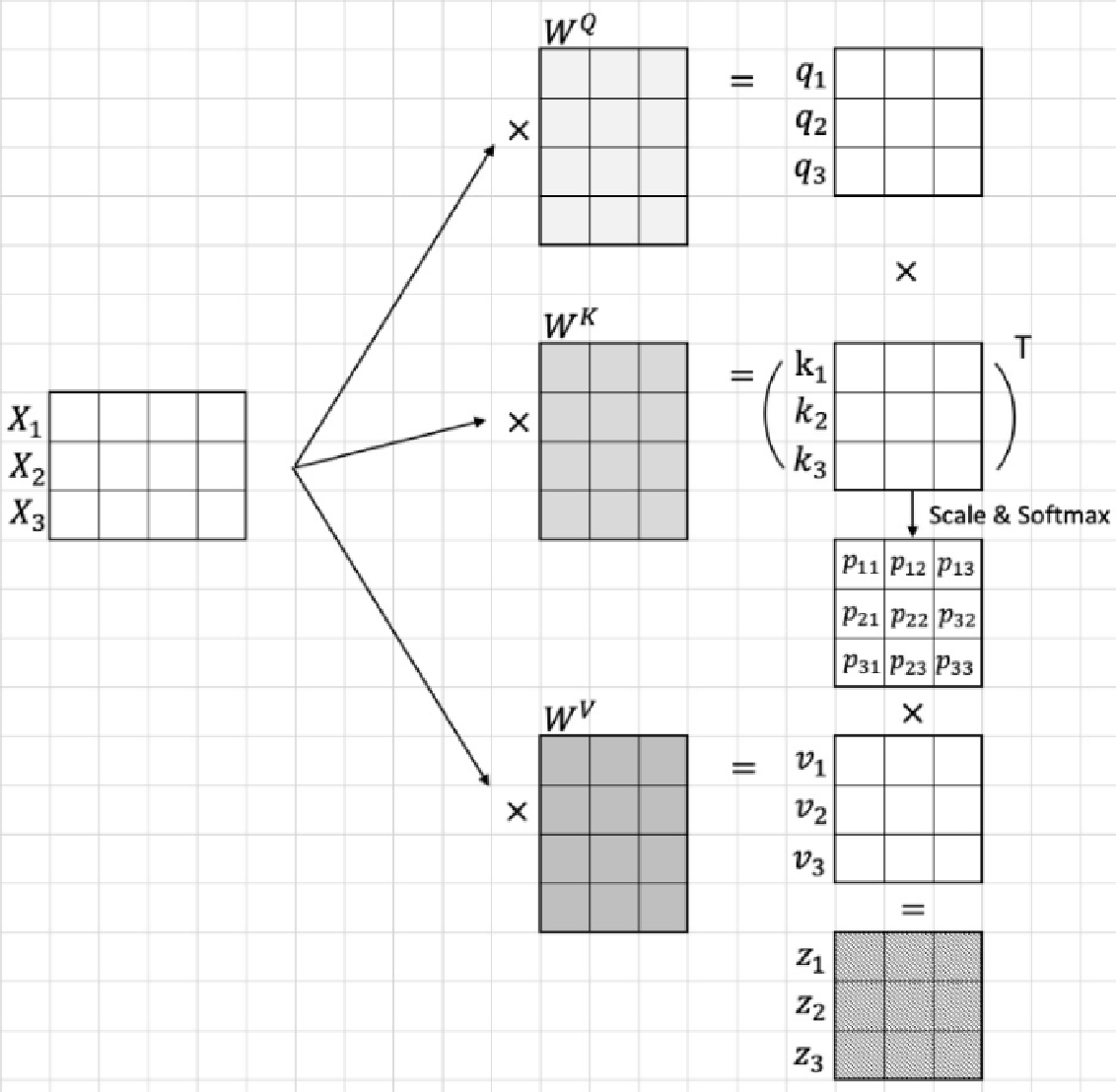
Q(Query), K(Key), V(Value)
Q 相当于近似的 K
-
向量内积:
两个向量相似度越大的时候向量的内积越大,反之则越小;当两个向量正交时内积为0
对于每一个输入的Vectorized Token进行线性映射都会得到对应的三个矩阵, , ,这三个矩阵分别与输入的相乘即可得到对应的, , ,之后再按照上面的注意力计算公式进行计算即可
备注:线性映射(
nn.Linear)实际作用就是将输入张量乘以一个高维权重矩阵然后再加上一个偏置,因此上面的, , 实际都是线性层中的权重参数
-
Self-Attention
-
Cross-Attention
Feed-Forward Networks
Positional Encoding
位置编码是为了处理连续的时间序列数据,区别于传统的RNN模型,第 时间步的计算依赖于第 步的计算结果,难以进行并行计算
将 位置处的 编码成长度为 的向量,偶数位置求sine,奇数位置求cosine,保证最后得到的每一个 编码后的向量都是不同的(但是长度相同)
Vision Transformer
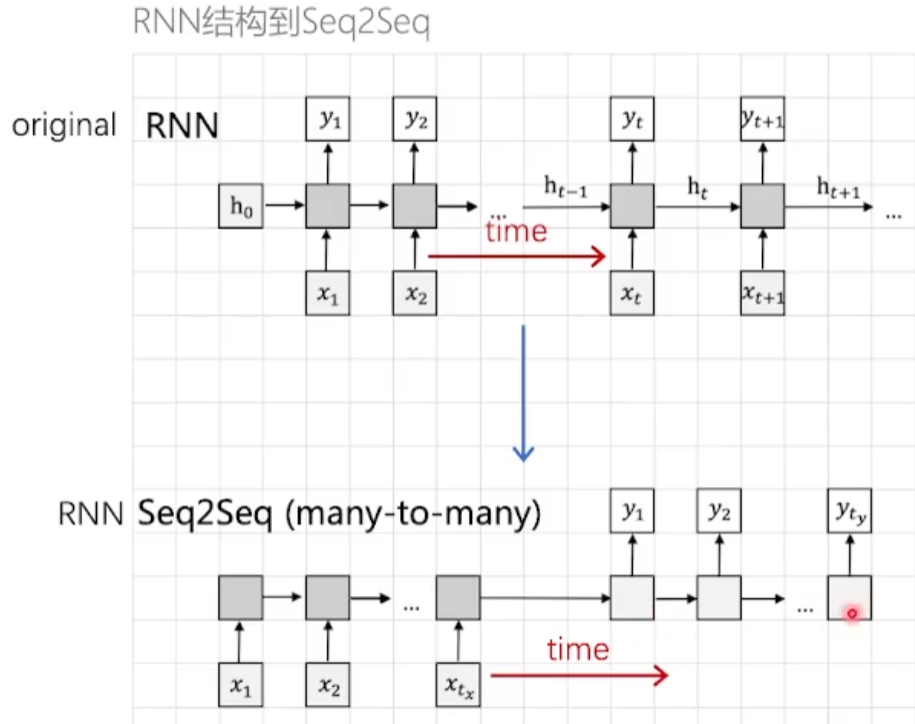
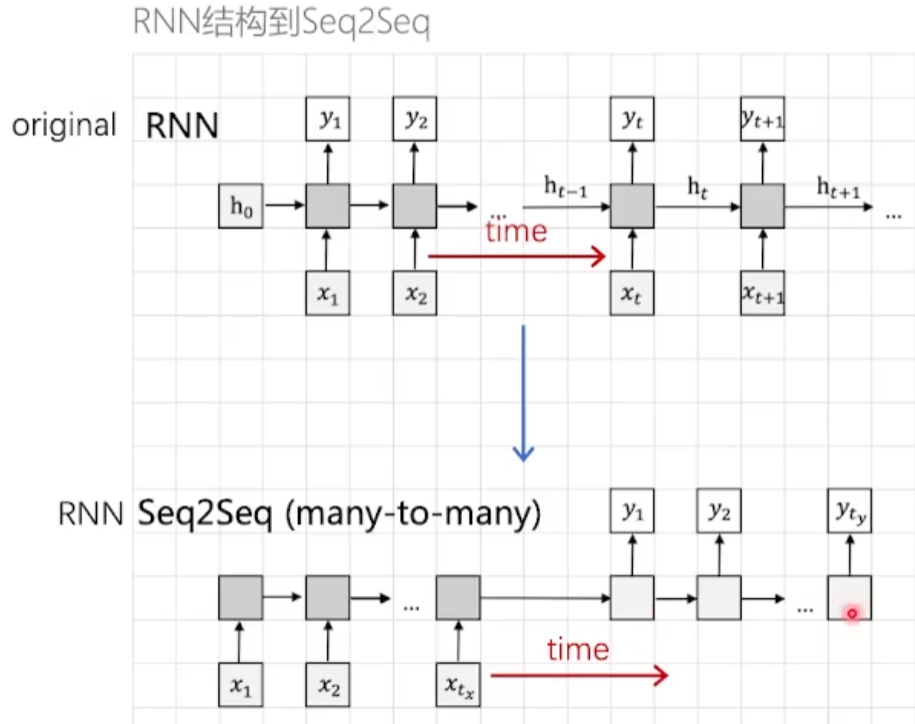
Attention机制的由来
- 原始
RNN网络输入张量和输出张量的长度是相同的 Seq2Seq模型的输入和输出长度是不相同的
BN 和 LN 的区别
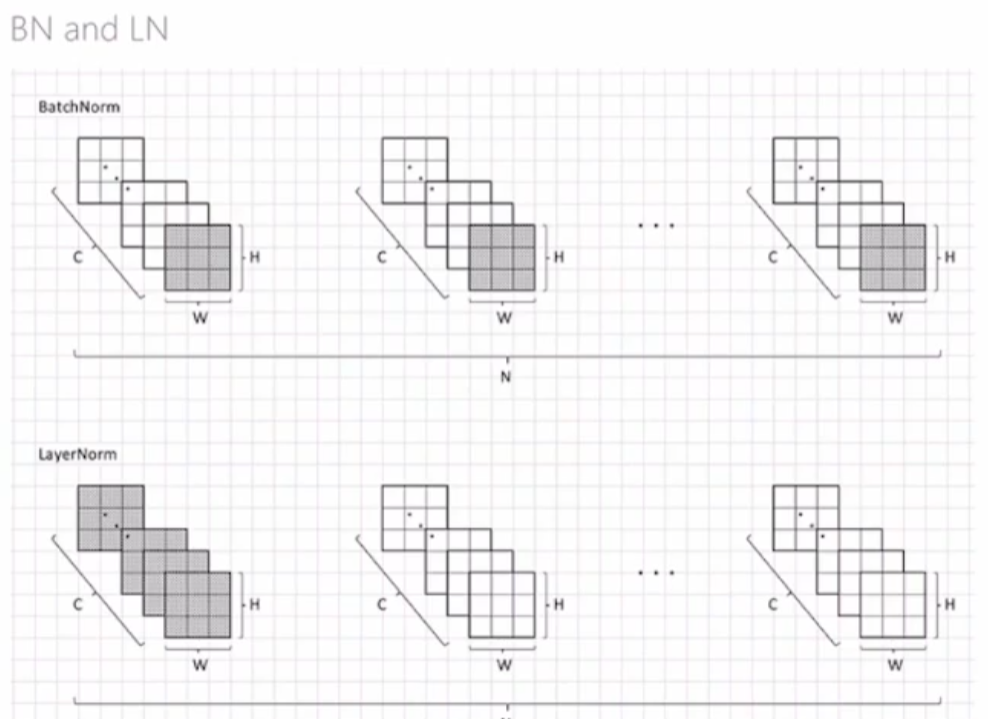
Batch Normalization是在每一个batch中抽取每个位置的张量求均值和方差
Layer Normalization是在每一个layer中抽取所有的张量求均值和方差
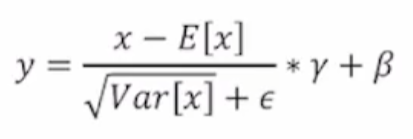
DeiT
知识蒸馏
简单来讲就是使用一个参数量更大,效果更好的模型作为
Teacher model来辅助训练一个参数量更小的Student model模型
GPT1
LSH算法:判断文章的相似度(通过word的集合进行判断)
Beam Search ?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本